DCTTS (TTS Convolutional Deep) - Implementasi Pytorch
Kertas: Sistem teks-ke-speech yang dapat dilatih secara efisien berdasarkan jaringan konvolusional yang mendalam dengan perhatian terpandu
Prasyarat
- Python 3.6
- Pytorch 1.0
- librosa, scipy, tqdm, tensorboardx
Dataset
- LJ Speech 1.1, dataset pembicara tunggal wanita.
- Saya mengikuti repo DCTTS Kyubyong dengan TensorFlow untuk preprocessing data sinyal bicara. Ini benar -benar bekerja dengan baik.
Penggunaan
Unduh dataset di atas dan ubah jalur di config.py. Dan kemudian jalankan perintah di bawah ini. Arg pertama: Sinyal Prepro, 2nd Arg: Metadata (Train/Test Split)
DCTTS memiliki dua model. Pertama, Anda harus melatih model Text2mel. Saya pikir langkah 20k sudah cukup (hanya satu jam). Tetapi Anda harus melatih model semakin banyak dengan kehilangan perhatian yang membusuk.
python train.py 1 <gpu_id>
Kedua, latih SSRN. Output SSRN adalah banyak data resolusi tinggi. Jadi pelatihan ssrn lebih lambat dari pelatihan text2mel
python train.py 2 <gpu_id>
Setelah pelatihan, Anda dapat mensintesis beberapa pidato dari teks.
python synthesize.py <gpu_id>
Perhatian
- Dalam sintesis bicara, modul perhatian penting. Jika model biasanya dilatih, maka Anda dapat melihat perhatian monotonik seperti gambar berikut.
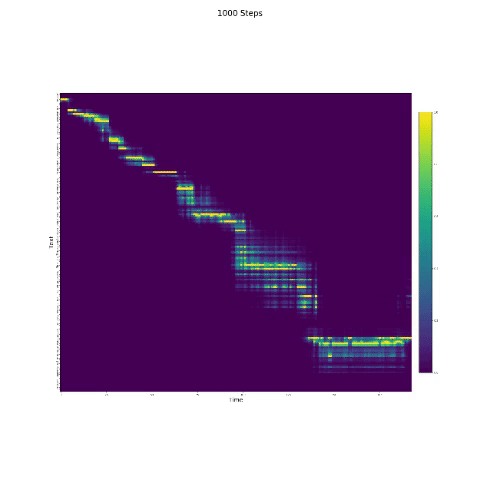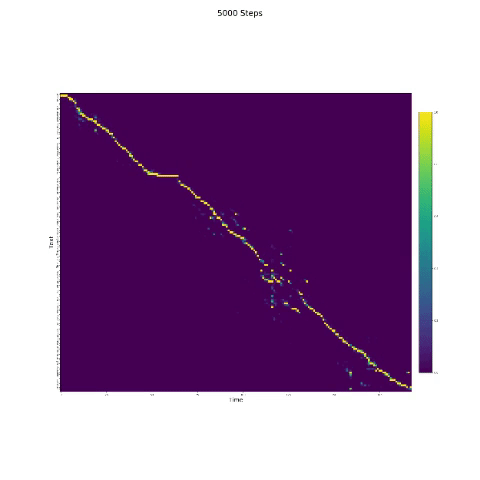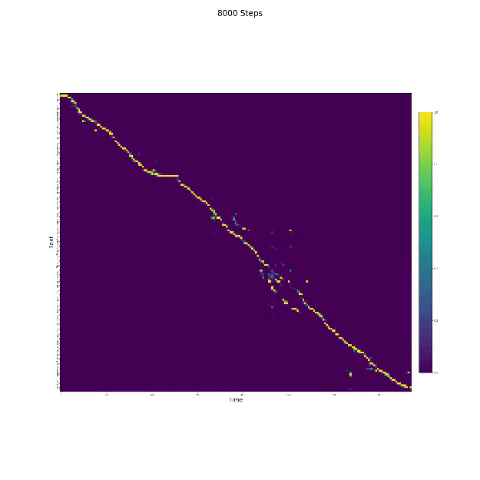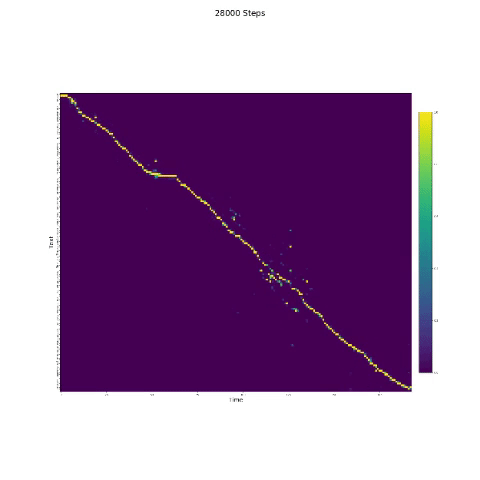
Catatan
- To Do: Perhatian sebelumnya untuk inferensi.
- Untuk melakukan: Mengurangi overfitting.
- Di koran, mereka tidak merujuk normalisasi. Jadi saya menggunakan normalisasi berat badan seperti DeepVoice3.
- Beberapa hiperparameter berbeda.
- Jika Anda ingin meningkatkan kinerja, Anda harus menggunakan semua data. Untuk beberapa percobaan yang berbeda, saya memisahkan set pelatihan dan set validasi.
Kode lain
- Implementasi Pytorch lainnya
- Implementasi TensorFlow


