DCTTS (profundo TTS convolucional) - Implementação de Pytorch
Papel: Sistema de texto para fala com eficientemente treinável com base em redes convolucionais profundas com atenção guiada
Pré -requisito
- Python 3.6
- Pytorch 1.0
- Librosa, Scipy, TQDM, Tensorboardx
Conjunto de dados
- LJ Discurso 1.1, conjunto de dados de alto -falante feminino.
- Eu sigo o repositório DCTTS de Kyubyong com o TensorFlow para pré -processamento de dados do sinal de fala. Na verdade, funcionou bem.
Uso
Faça o download do conjunto de dados acima e modifique o caminho em config.py. E depois execute o comando abaixo. 1º ARG: Signal Prepro, 2º Arg: Metadata (Split de trem/teste)
O DCTTS tem dois modelos. Em primeiro lugar, você deve treinar o modelo Text2mel. Eu acho que o passo de 20k é suficiente (por apenas uma hora). Mas você deve treinar o modelo cada vez mais com a perda de atenção guiada.
python train.py 1 <gpu_id>
Em segundo lugar, treine o SSRN. As saídas do SSRN são muitos dados de alta resolução. Portanto, o treinamento do SSRN é mais lento do que o treinamento de texto2mel
python train.py 2 <gpu_id>
Após o treinamento, você pode sintetizar algum discurso do texto.
python synthesize.py <gpu_id>
Atenção
- Na síntese da fala, o módulo de atenção é importante. Se o modelo for normalmente treinado, você poderá ver a atenção monotônica como as figuras a seguir.
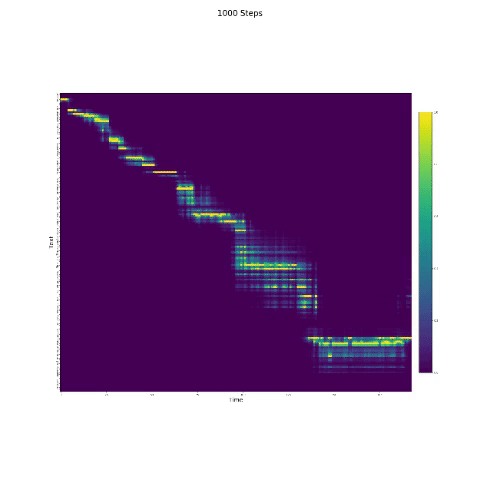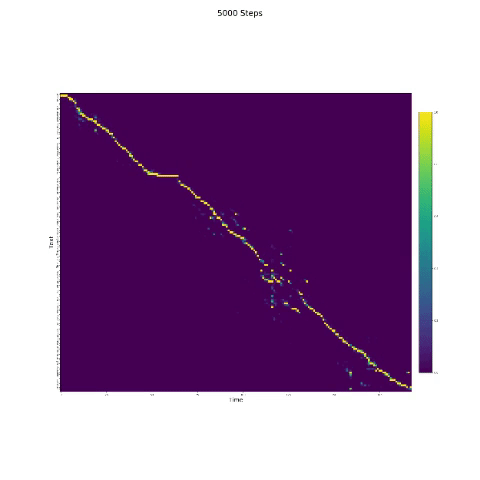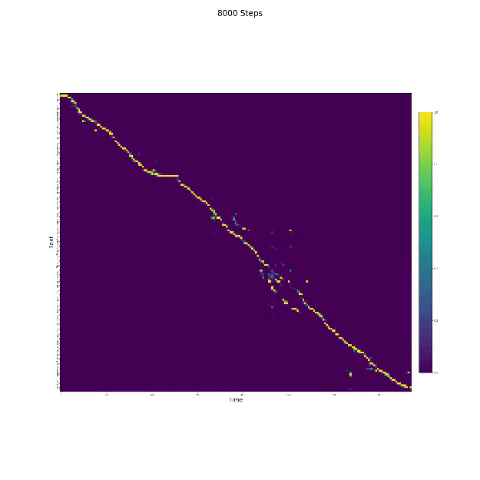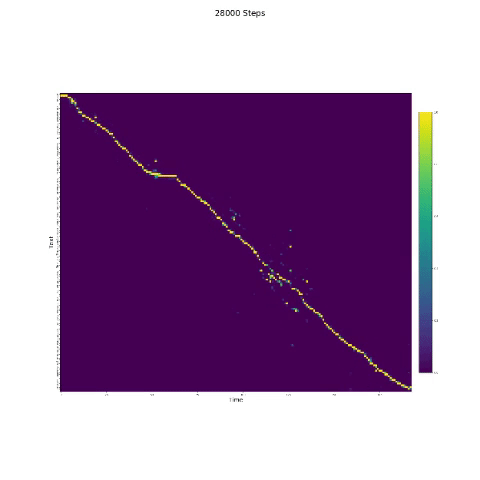
Notas
- Para fazer: atenção anterior para inferência.
- Para fazer: aliviar o excesso de ajuste.
- No artigo, eles não se referiram à normalização. Então, usei a normalização do peso como o DeepVoice3.
- Alguns hiperparâmetros são diferentes.
- Se você deseja melhorar o desempenho, use todos os dados. Para vários experimentos, separei o conjunto de treinamento e o conjunto de validação.
Outros códigos
- Outra implementação de Pytorch
- Implementação do TensorFlow


