DCTTS (Deep Convolutionnel TTS) - Implémentation de Pytorch
Document: Système de texte à dispection efficacement formable basé sur des réseaux convolutionnels profonds avec une attention guidée
Condition préalable
- Python 3.6
- pytorch 1.0
- Librosa, Scipy, TQDM, Tensorboardx
Ensemble de données
- LJ Speech 1.1, ensemble de données de haut-parleur unique féminin.
- Je suis le dépôt DCTTS de Kyubyong avec TensorFlow pour le prétraitement des données du signal vocal. Cela a bien fonctionné.
Usage
Téléchargez l'ensemble de données ci-dessus et modifiez le chemin d'accès dans config.py. Puis exécutez la commande ci-dessous. 1st Arg: Signal Prepro, 2nd Arg: Metadata (Train / Test Split)
DCTTS a deux modèles. Tout d'abord, vous devez former le modèle Text2Mel. Je pense que le pas de 20 km est suffisant (pendant seulement une heure). Mais vous devez former le modèle de plus en plus avec une perte d'attention guidée en décomposition.
python train.py 1 <gpu_id>
Deuxièmement, entraînez le SSRN. Les sorties de SSRN sont de nombreuses données à haute résolution. Donc, la formation SSRN est plus lente que la formation Text2Mel
python train.py 2 <gpu_id>
Après l'entraînement, vous pouvez synthétiser un discours à partir du texte.
python synthesize.py <gpu_id>
Attention
- Dans la synthèse de la parole, le module d'attention est important. Si le modèle est normalement formé, vous pouvez voir l'attention monotone comme les figures suivantes.
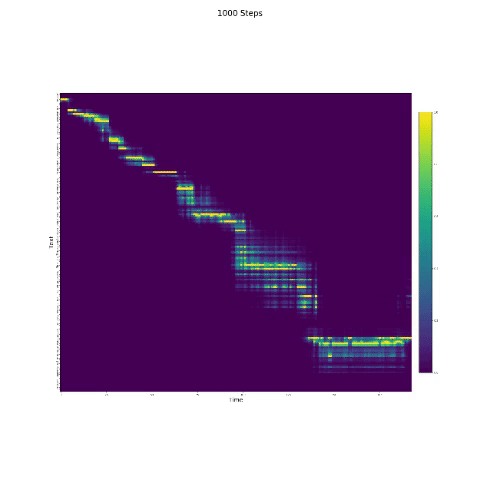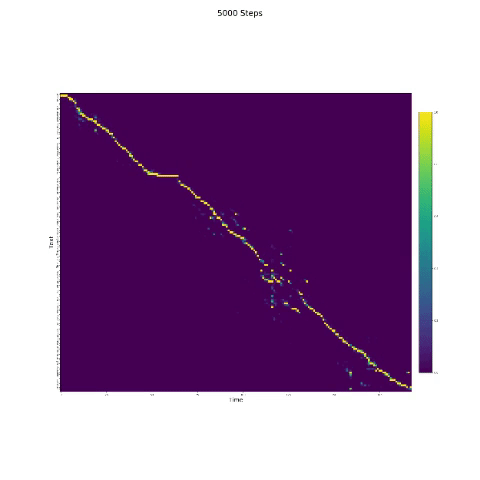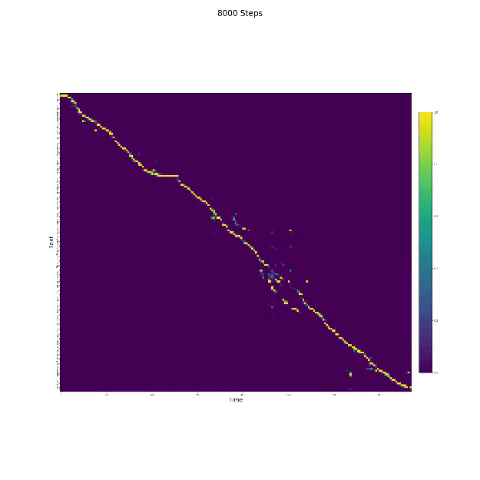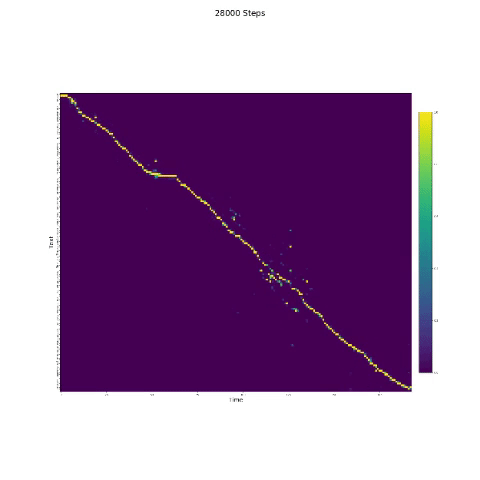
Notes
- À faire: une attention antérieure pour l'inférence.
- À faire: soulager le sur-ajustement.
- Dans l'article, ils n'ont pas référé la normalisation. J'ai donc utilisé la normalisation du poids comme DeepVoice3.
- Certains hyperparamètres sont différents.
- Si vous souhaitez améliorer les performances, vous devez utiliser toutes les données. Pour certaines expériences diverses, j'ai séparé l'ensemble de formation et l'ensemble de validation.
Autres codes
- Une autre implémentation Pytorch
- Implémentation de TensorFlow


