Conditional SpecGAN Tensorflow
1.0.0
A (условное) генеративная состязательная сеть генеративного синтеза аудио, которая генерирует спектрограмму, которая способствует синтезированию необработанной формы волны, реализации в TensorFlow. 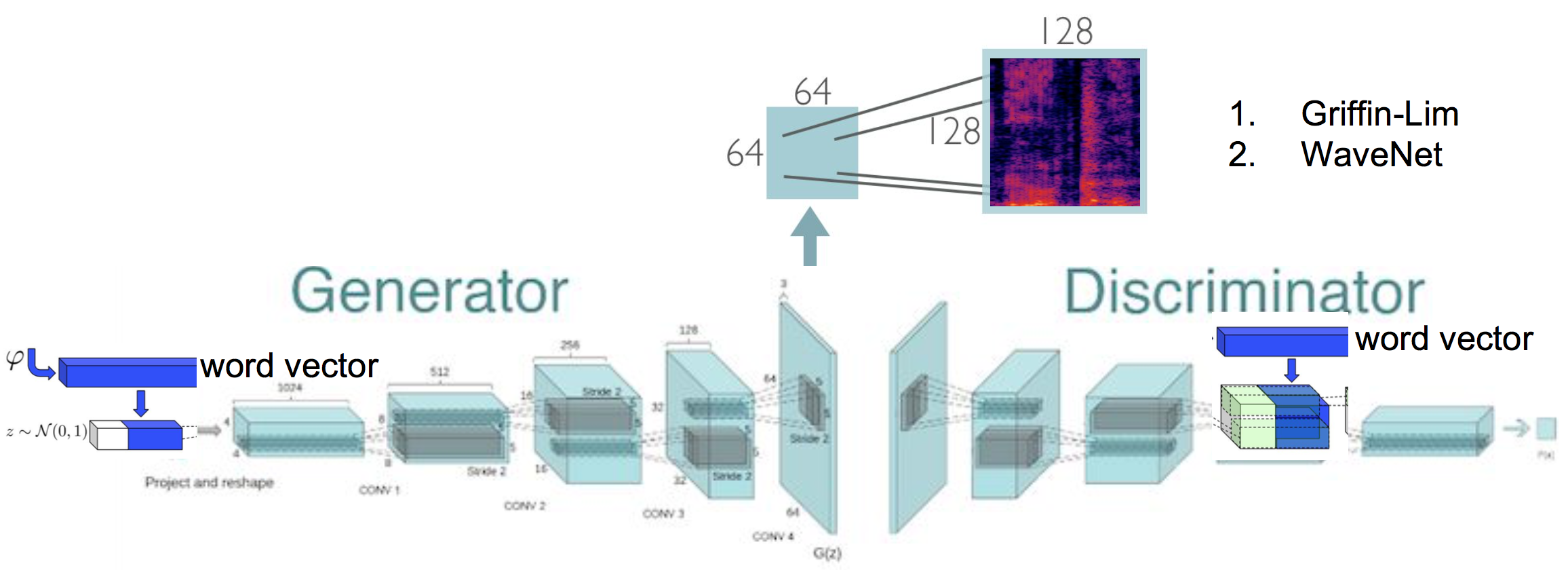
Синтез текста в речь путем генерации спектрограмм с использованием генеративной состязательной сети. Эта работа основана на исходной реализации Specgan, где я исследую обучение Specgan. Кроме того, применяется схема предварительной обработки данных на основе энергии, что приводит к улучшению качества звука.
Результат предварительной обработки может быть продемонстрирован с помощью следующей визуализации: 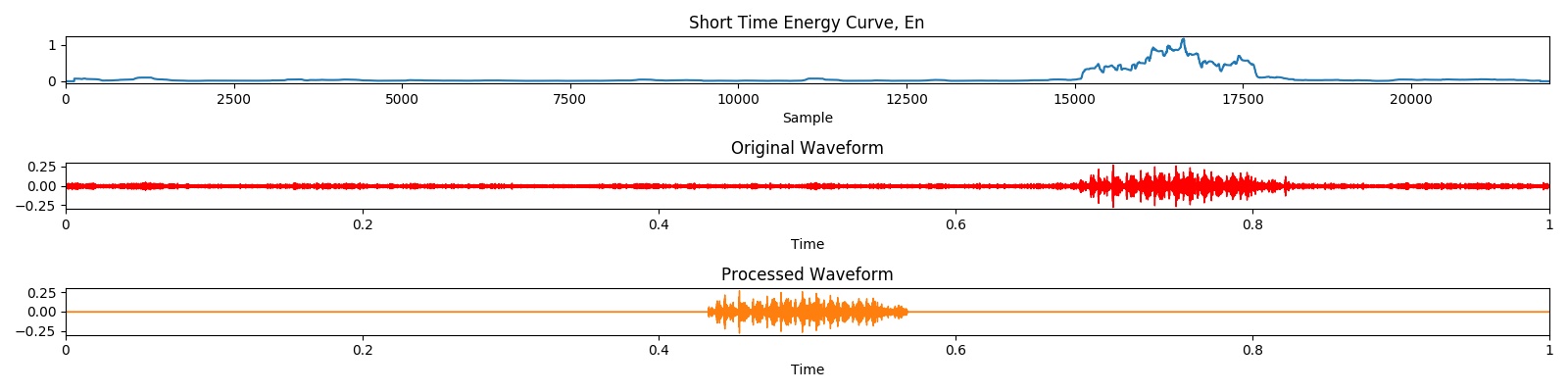
Скачать данные обучения: здесь
Запустить './src/utils/preprocess_data.py' для обработки данных или загрузки обработанных данных: здесь
Запустить './src/utils/visualize_wav.py', чтобы визуализировать обработанные чистые данные или загрузить результаты: здесь
Запустите ' ./src/utils/make_tfrecord.py ' для обработки файлов .wav в готовые файлы обучения.
Извлеките файл .tgz на шаг.4 и поместите его в соответствующий путь в соответствии с args.data_dir в ./src/config.py:
data_dir='../data/sc09_preprocess_energy'
Этот путь по умолчанию может быть изменен, изменяя опцию '-data_dir в' ./src/config.py '.
python3 ./src/runner.py train
python3 ./src/runner.py generate
python3 ./src/runner.py train --conditional
python3 ./src/runner.py generate --conditional


