Conditional SpecGAN Tensorflow
1.0.0
Sintesis audio (kondisional) jaringan permusuhan generatif yang menghasilkan spektrogram, yang selanjutnya mensintesis bentuk gelombang mentah, implementasi pada tensorflow. 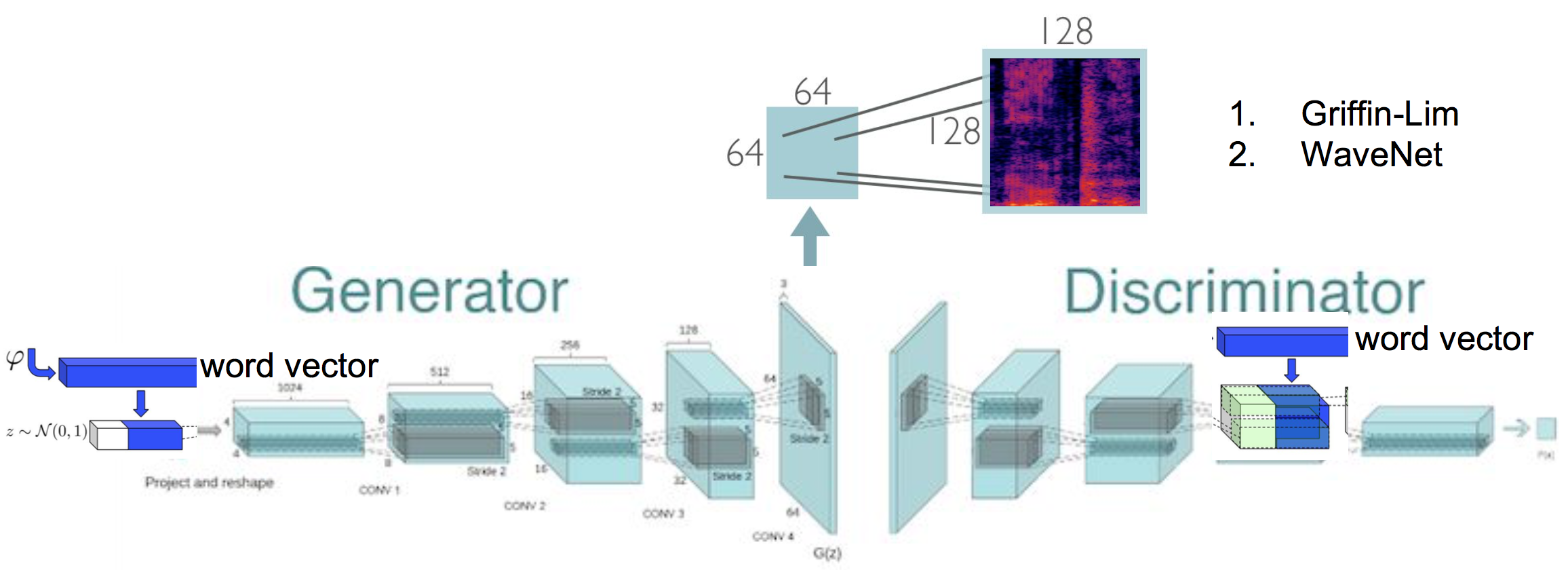
Sintesis Teks-ke-Speech dengan menghasilkan spektrogram menggunakan jaringan permusuhan generatif. Pekerjaan ini didasarkan pada implementasi asli Specgan, di mana saya lebih jauh mengeksplorasi pelatihan spektronik pengkondisian. Selain itu, skema preprocessing data berbasis energi diterapkan, yang menghasilkan peningkatan kualitas audio.
Hasil preprocess dapat ditunjukkan dengan visualisasi berikut: 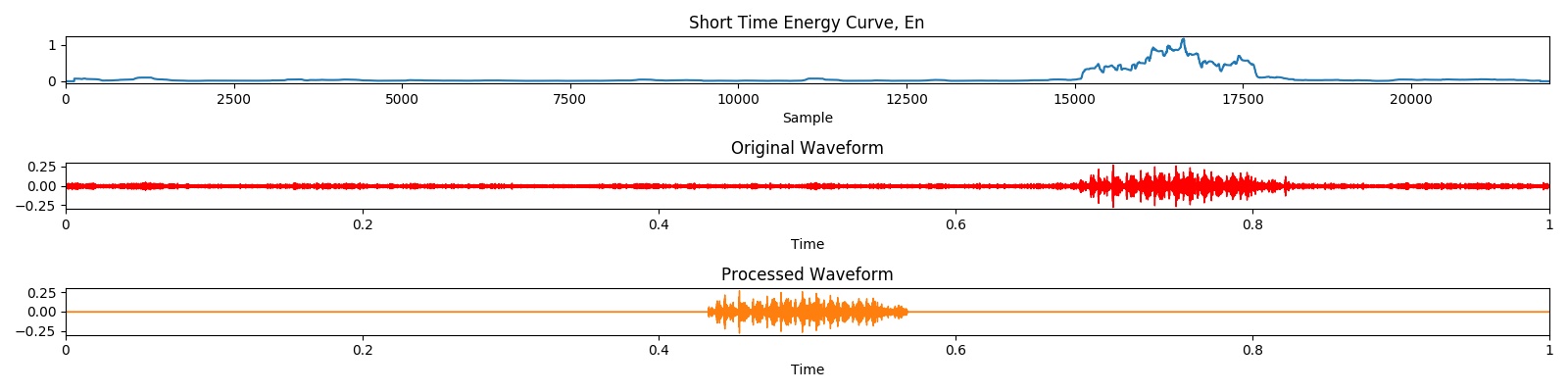
Unduh Data Pelatihan: Di Sini
Jalankan './src/utils/preprocess_data.py' untuk memproses data atau mengunduh data yang diproses: di sini
Jalankan './src/utils/visualize_wav.py' untuk memvisualisasikan data bersih yang diproses atau unduh hasilnya: di sini
Jalankan './src/utils/make_tfrecord.py' untuk memproses file .wav ke dalam file siap pelatihan .tfrecord, atau unduh data yang diproses: di sini
Ekstrak file .tgz di langkah.4, dan letakkan di jalur yang relevan menurut args.data_dir di ./src/config.py:
data_dir='../data/sc09_preprocess_energy'
Jalur default ini dapat dimodifikasi dengan mengubah opsi '--data_dir di' ./src/config.py '.
python3 ./src/runner.py train
python3 ./src/runner.py generate
python3 ./src/runner.py train --conditional
python3 ./src/runner.py generate --conditional


