Conditional SpecGAN Tensorflow
1.0.0
분광기를 생성하는 (조건부) 오디오 합성 생성 적대 네트워크, Furthur는 원시 파형, 텐서 플로에서 구현을 합성합니다. 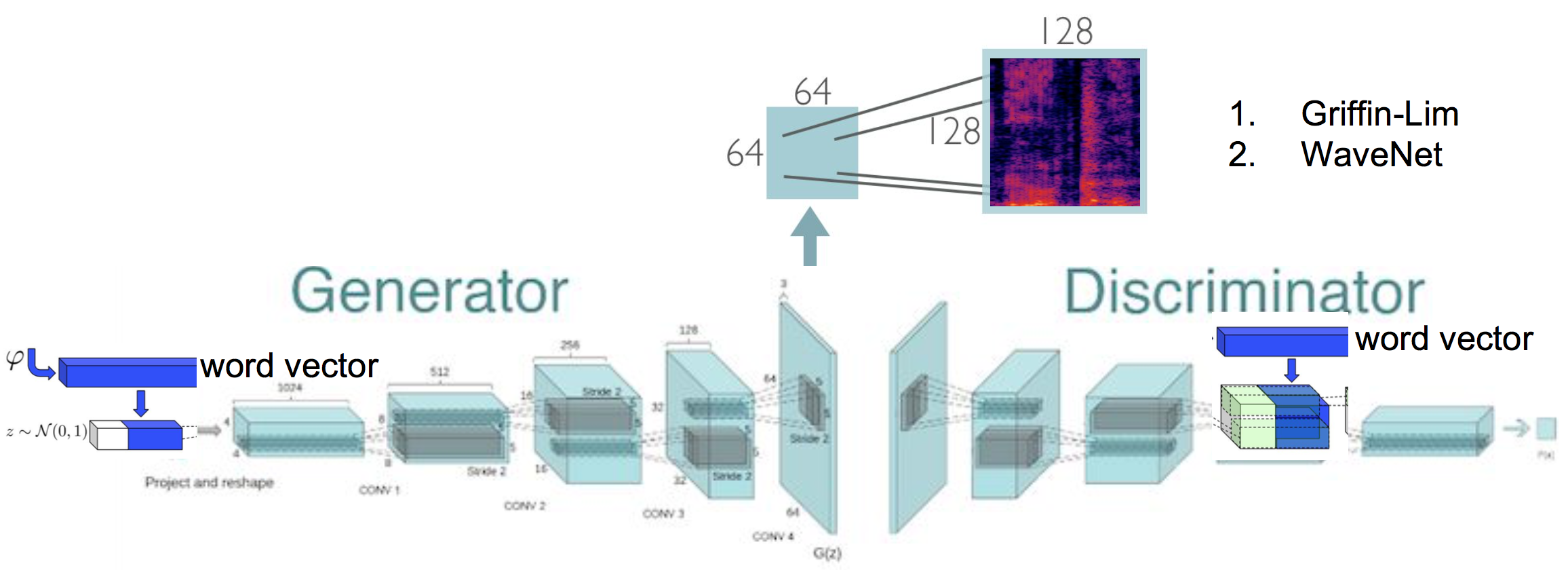
생성 적대적 네트워크를 사용하여 스펙트로 그램을 생성하여 텍스트-음성 합성. 이 작업은 Specgan의 원래 구현을 기반으로합니다. 여기서 나는 Specgan 훈련을 컨디셔닝에 대해 탐색합니다. 또한 에너지 기반 데이터 전처리 체계가 적용되어 오디오 품질이 향상됩니다.
전처리 결과는 다음 시각화로 입증 될 수 있습니다. 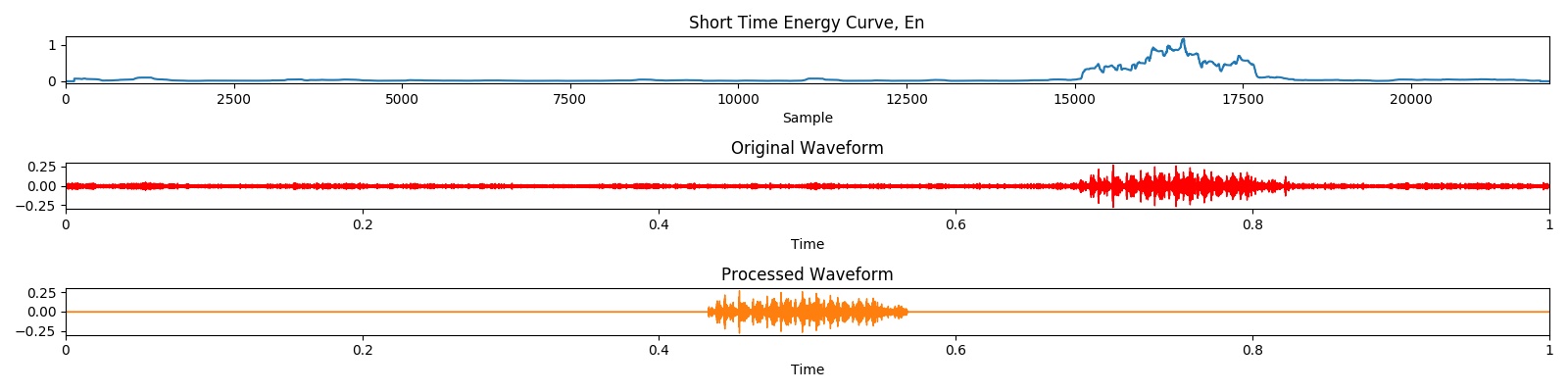
교육 데이터 다운로드 : 여기
run './src/utils/preprocess_data.py'는 데이터를 처리하거나 처리 된 데이터를 다운로드합니다 .
'./src/utils/visualize_wav.py'를 실행하여 처리 된 청정 데이터를 시각화하거나 결과를 다운로드하십시오 .
run './src/utils/make_tfrecord.py'는 .wav 파일을 .tfrecord training ready 파일로 처리하거나 처리 된 데이터를 다운로드하십시오 .
4 단계에서 .tgz 파일을 추출하고 args.data_dir in ./src/config.py에 따라 관련 경로로 배치하십시오.
data_dir='../data/sc09_preprocess_energy'
이 기본 경로는 './src/config.py'에서 '---data_dir 옵션을 변경하여 수정할 수 있습니다.
python3 ./src/runner.py train
python3 ./src/runner.py generate
python3 ./src/runner.py train --conditional
python3 ./src/runner.py generate --conditional


