Conditional SpecGAN Tensorflow
1.0.0
A (conditional) audio synthesis generative adversarial network that generates spectrogram, which furthur synthesize raw waveform, implementation in Tensorflow.
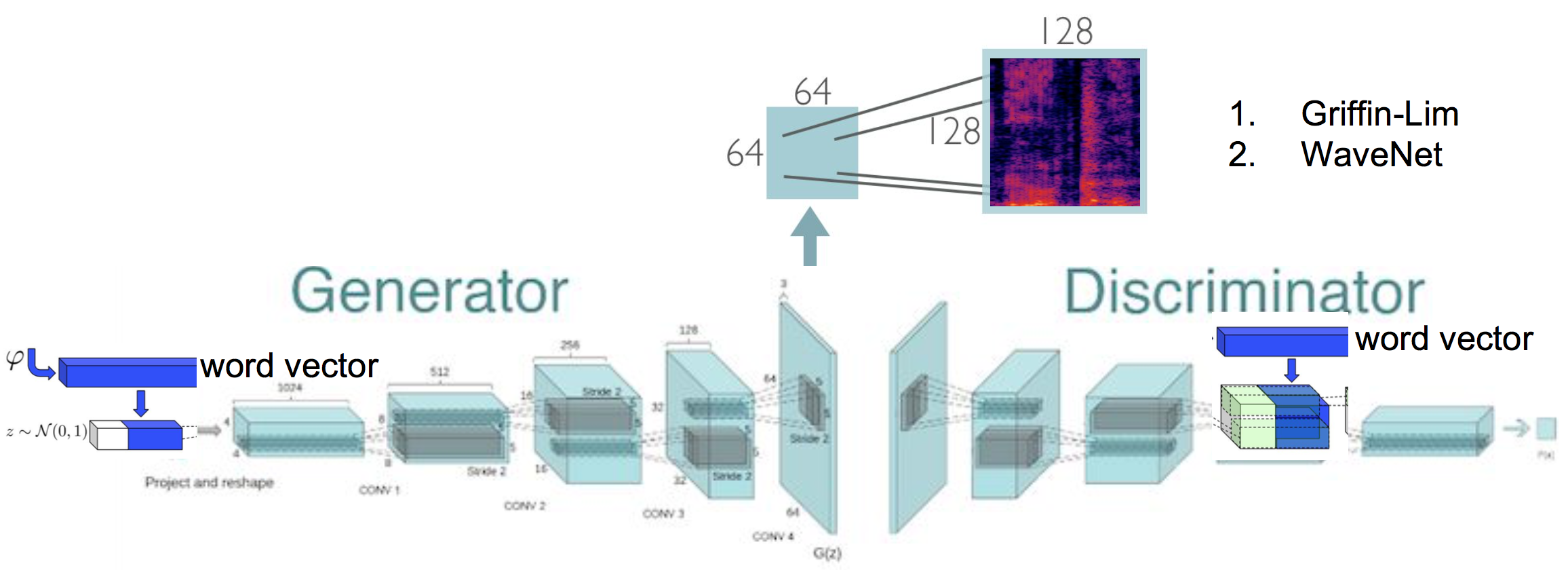
Text-to-Speech Synthesis by Generating Spectrograms using Generative Adversarial Network. This work is based on the original implementation of SpecGAN, where I furthur explore on conditioning SpecGAN training. Additionally, an energy based data preprocessing scheme is applied, which results in an improvement in audio quality.
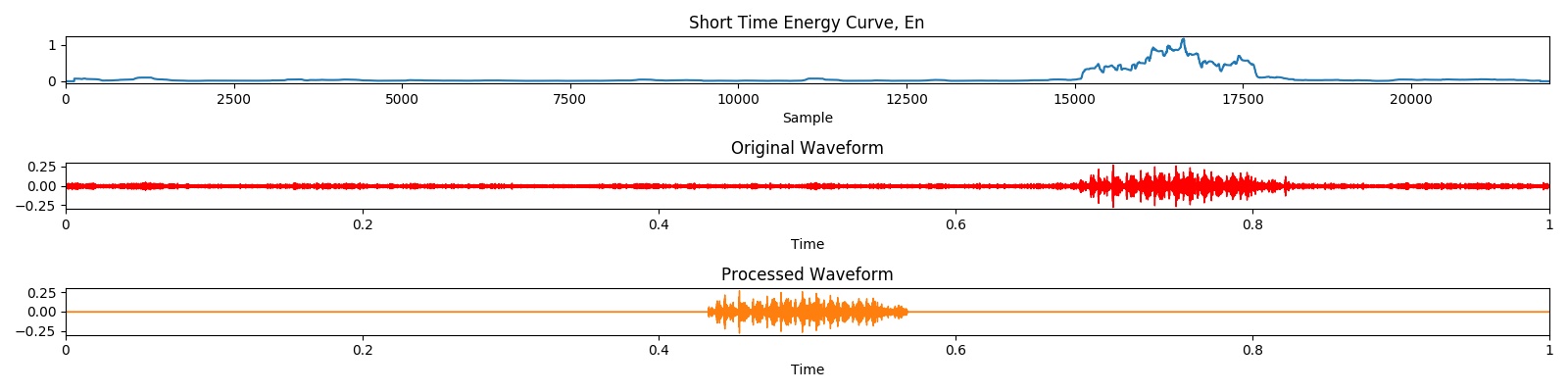
The preprocess result can be demonstrated by the following visualization:
Download training data: here
Run './src/utils/preprocess_data.py' to process data or download the processed data: here
Run './src/utils/visualize_wav.py' to visualize the processed clean data or download the results: here
Run './src/utils/make_tfrecord.py' to process .wav files into .tfrecord training ready files, or download the processed data: here
Extract the .tgz file in step.4, and place them to the relevent path according to args.data_dir in ./src/config.py:
data_dir='../data/sc09_preprocess_energy'
This default path can be modified by changing the '--data_dir option in './src/config.py'.
python3 ./src/runner.py train
python3 ./src/runner.py generate
python3 ./src/runner.py train --conditional
python3 ./src/runner.py generate --conditional


