Conditional SpecGAN Tensorflow
1.0.0
Un réseau adversaire génératif de synthèse audio (conditionnelle) qui génère du spectrogramme, qui synthétise plus la forme d'onde brute, implémentation dans TensorFlow. 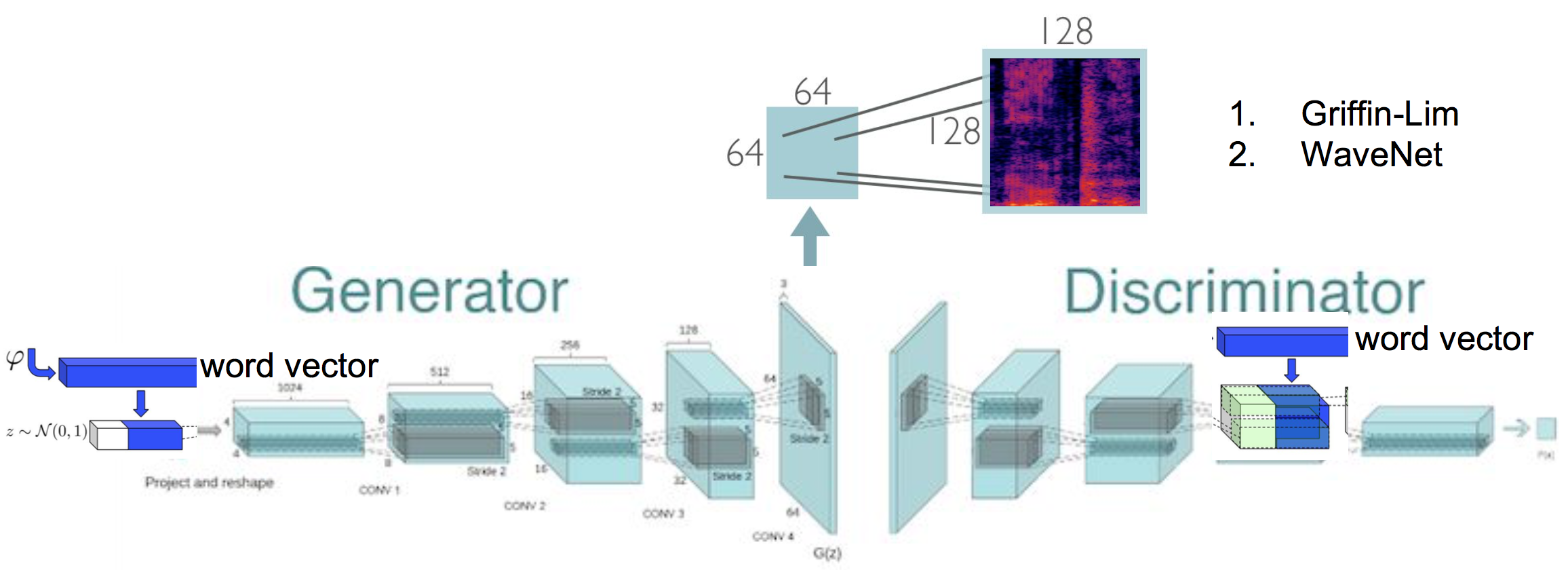
Synthèse de texte vocal en générant des spectrogrammes en utilisant un réseau adversaire génératif. Ce travail est basé sur la mise en œuvre originale de Specgan, où j'explore en plus sur la formation de condition Specgan. De plus, un schéma de prétraitement des données basé sur l'énergie est appliqué, ce qui entraîne une amélioration de la qualité audio.
Le résultat du prétraitement peut être démontré par la visualisation suivante: 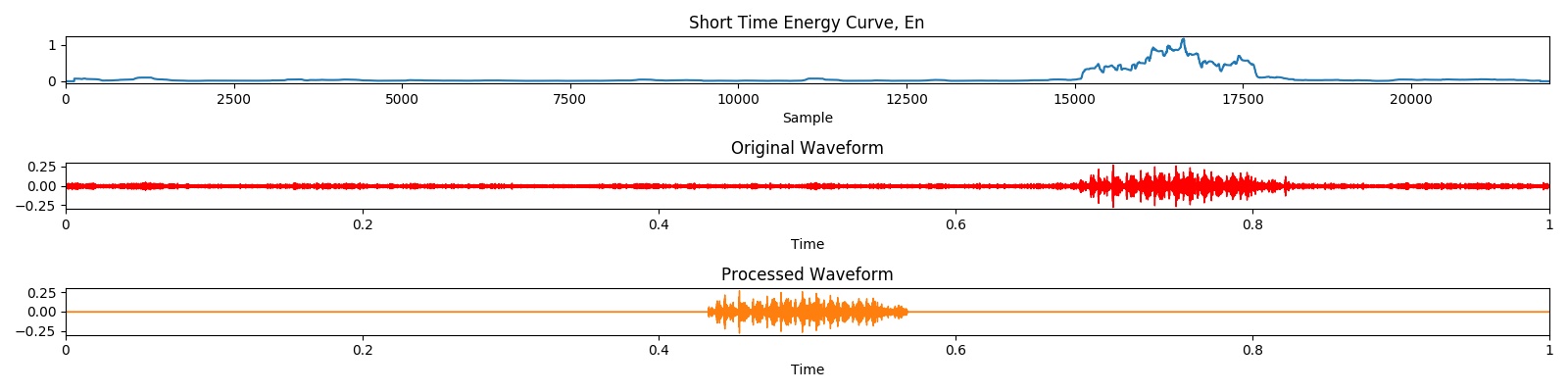
Télécharger les données de formation: ici
Exécuter './src/utils/preprocess_data.py' pour traiter les données ou télécharger les données traitées: ici
Exécuter './src/utils/visualize_wav.py' pour visualiser les données nettoyantes traitées ou télécharger les résultats: ici
Exécuter './src/utils/make_tfrecord.py' pour traiter les fichiers .wav dans .tfrecord Training Ready Files, ou télécharger les données traitées: ici
Extraire le fichier .tgz dans Step.4 et les placer sur le chemin pertinent selon args.data_dir dans ./src/config.py:
data_dir='../data/sc09_preprocess_energy'
Ce chemin par défaut peut être modifié en modifiant l'option '--data_dir dans' ./src/config.py '.
python3 ./src/runner.py train
python3 ./src/runner.py generate
python3 ./src/runner.py train --conditional
python3 ./src/runner.py generate --conditional


