Conditional SpecGAN Tensorflow
1.0.0
Ein (bedingtes) Audio -Synthese generatives kontroverses Netzwerk, das Spektrogramm erzeugt, das die Implementierung von Rohwellenform im Tensorflow weiter synthetisieren. 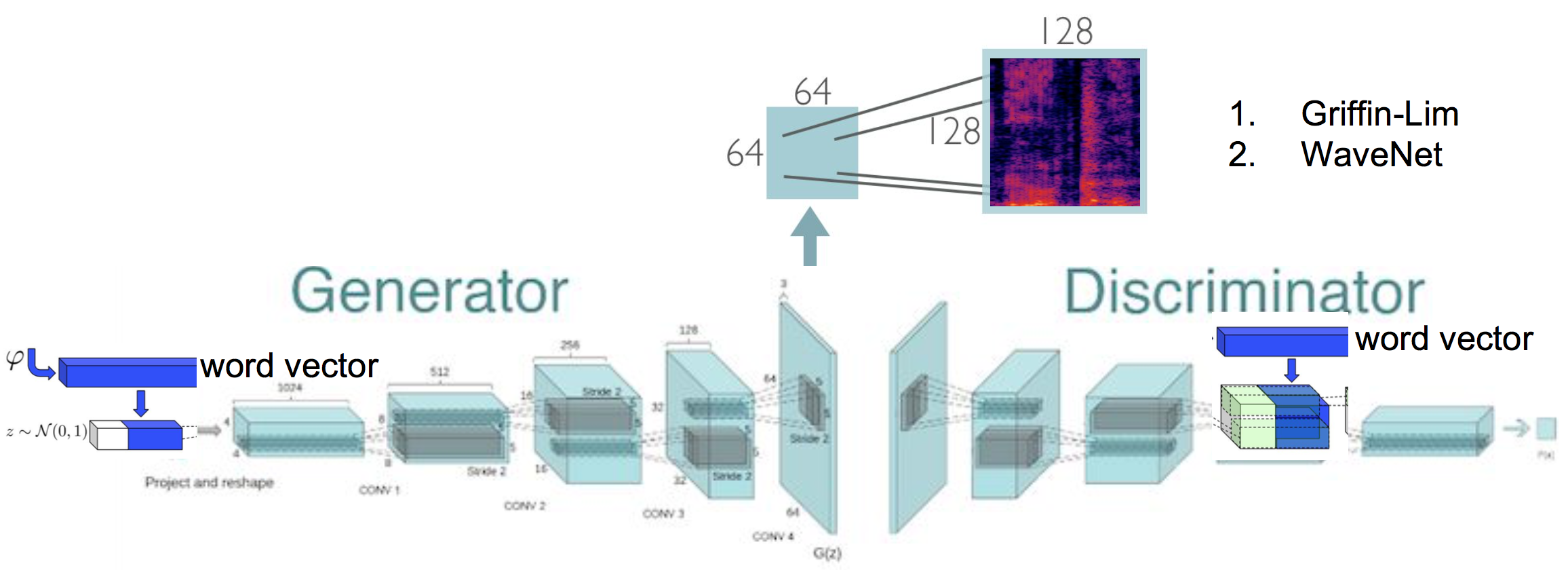
Text-to-Speech-Synthese durch Generierung von Spektrogrammen mit dem generativen kontroversen Netzwerk. Diese Arbeit basiert auf der ursprünglichen Implementierung von Spekan, wo ich das Spekan -Training von Konditionierungen weiter untersuche. Darüber hinaus wird ein energiebasiertes Datenvorverarbeitungsschema angewendet, was zu einer Verbesserung der Audioqualität führt.
Das Vorverarbeitungsergebnis kann durch die folgende Visualisierung demonstriert werden: 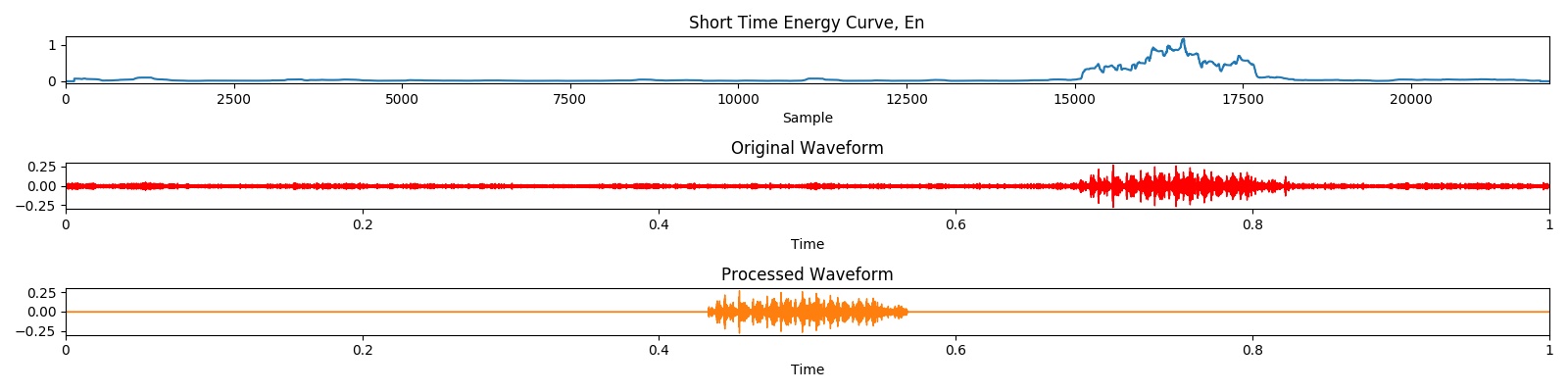
Laden Sie Trainingsdaten herunter: Hier
Rennen Sie './src/utils/preprocess_data.py', um Daten zu verarbeiten oder die verarbeiteten Daten herunterzuladen: hier
Rennen Sie './src/utils/visualize_wav.py', um die verarbeiteten sauberen Daten zu visualisieren oder die Ergebnisse herunterzuladen: hier
Rennen Sie './src/utils/make_tfrecord.py', um .wav -Dateien in .tfrecord Training Ready -Dateien zu verarbeiten, oder laden Sie die verarbeiteten Daten herunter: hier
Extrahieren Sie die .tgz -Datei in Schritt.4 und legen Sie sie gemäß args.data_dir in ./src/config.py auf den relevanten Pfad:
data_dir='../data/sc09_preprocess_energy'
Dieser Standardpfad kann geändert werden, indem die Option '--data_dir in' ./src/config.py 'geändert wird.
python3 ./src/runner.py train
python3 ./src/runner.py generate
python3 ./src/runner.py train --conditional
python3 ./src/runner.py generate --conditional


