pytorch GAT
1.0.0
Этот репо содержит реализацию Pytorch оригинальной газеты GAT (: ссылка: Veličković et al.).
Он направлен на то, чтобы легко начать играть и изучать GAT и GNN в целом.
Графические нейронные сети - это семейство нейронных сетей, которые имеют дело с сигналами, определенными на графиках!
Графики могут моделировать много интересных природных явлений, поэтому вы увидите их везде из:
и вплоть до физики частиц в крупном Hedron Collider (LHC), выявление поддельных новостей и список можно продолжать и продолжать!
GAT является представителем пространственных (сверточных) GNNS. Поскольку CNNS имел огромный успех в области компьютерного зрения, исследователи решили обобщить его на графики, и поэтому мы здесь! ?
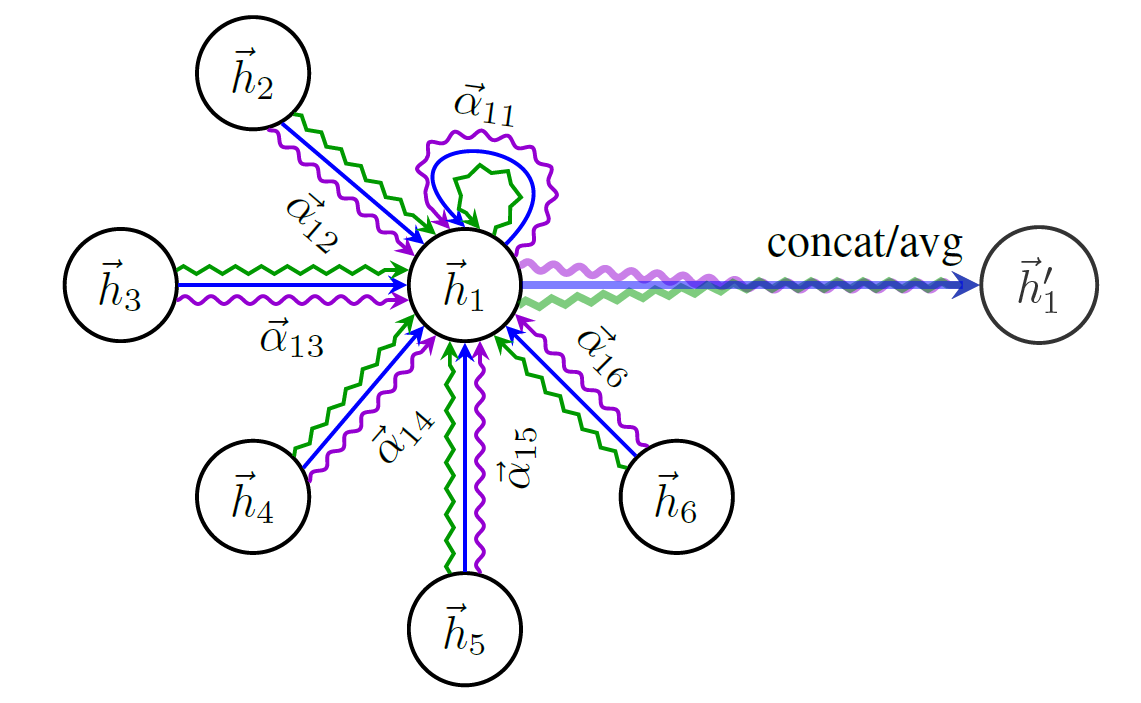
Вот схема структуры Гата:
Вы не можете просто начать говорить о GNN, не упомянув один самый известный набор данных по графику - CORA .
Узлы в CORA представляют исследовательские работы, а ссылки, как вы уже догадались, цитаты между этими статьями.
Я добавил утилиту для визуализации CORA и проведения базового сетевого анализа. Вот как выглядит Кора:

Размер узла соответствует его степени (то есть количество в/исходящих краев). Толщина края примерно соответствует тому, насколько «популярным» или «подключенным», этот край ( Edge Menerseses - это более занудный термин. Проверьте код.)
А вот сюжет, показывающий распределение степени на CORA:
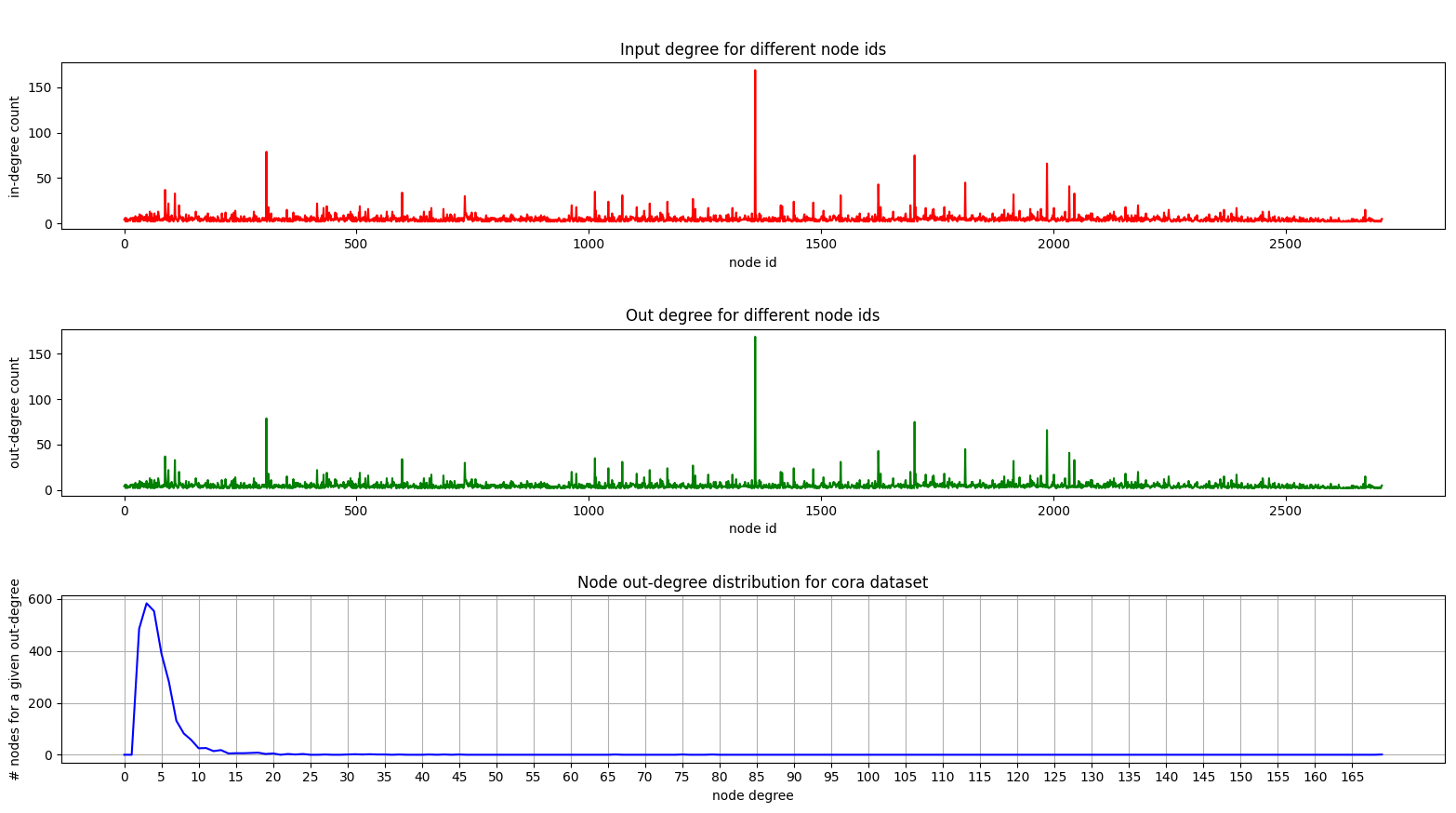
Главные участки и выходы одинаковы, так как мы имеем дело с неориентированным графиком.
На нижнем участке (распределение степени) вы можете увидеть интересный пик, происходящий в диапазоне [2, 4] . Это означает, что большинство узлов имеют небольшое количество краев, но есть 1 узел с 169 ребрами! (Большой зеленый узел)
Как только у нас будет полностью обученная модель GAT, мы сможем визуализировать внимание, которое изучили определенные «узлы».
Узлы используют внимание, чтобы решить, как объединить свой район, достаточно разговоров, давайте посмотрим:
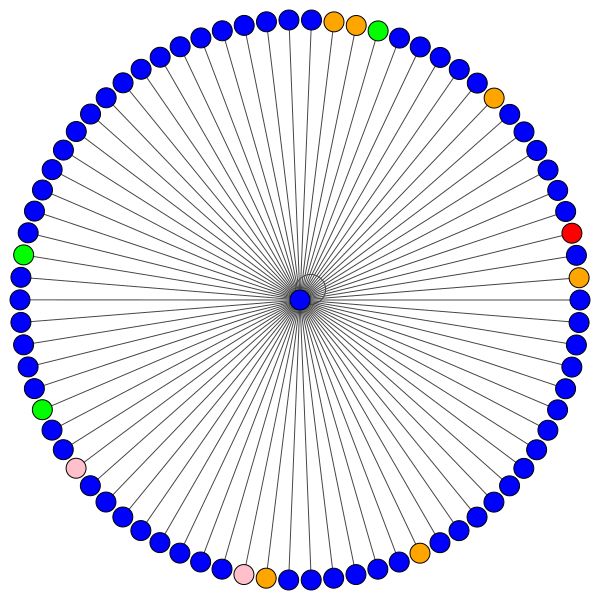
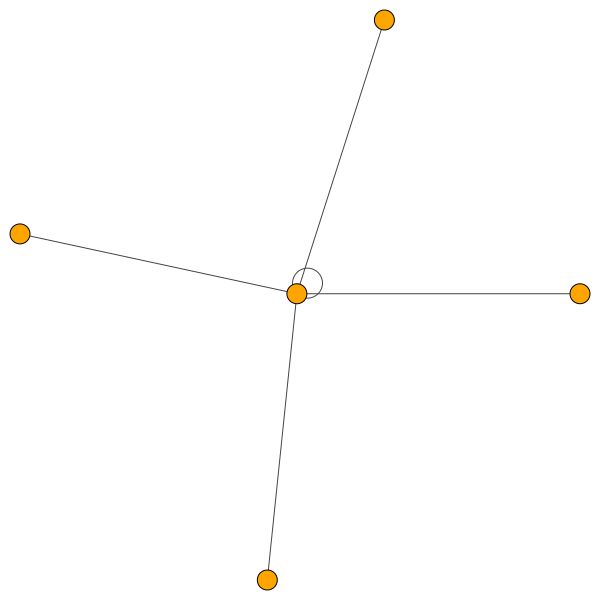
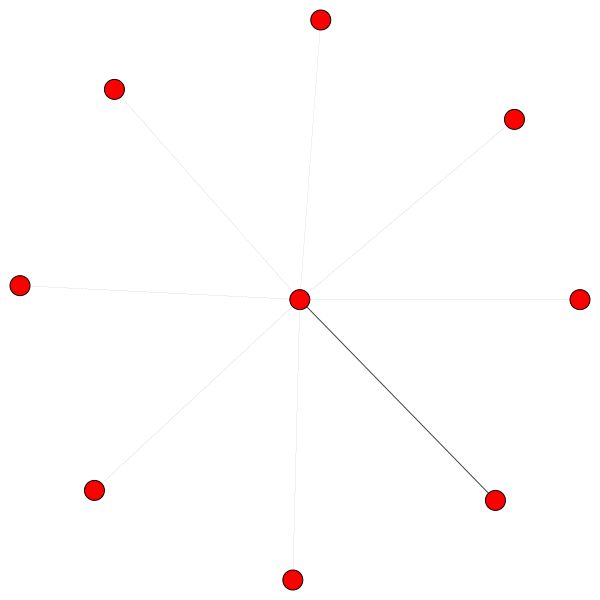
Это один из узлов Коры, который имеет большинство краев (цитаты). Цвета представляют узлы того же класса. Вы можете ясно увидеть 2 вещи из этого сюжета:
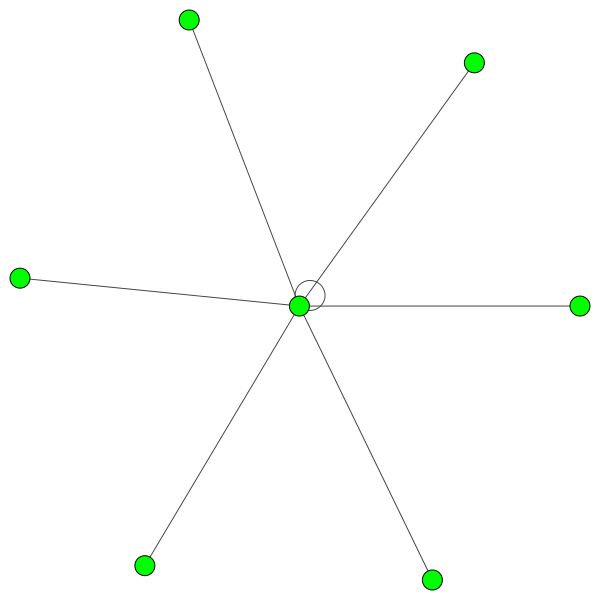
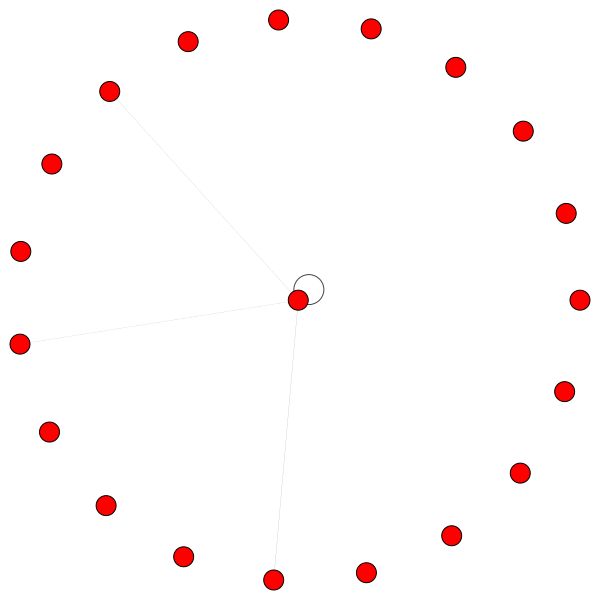
Аналогичные правила имеют для небольших районов. Также обратите внимание на самостоятельные края:
С другой стороны, PPI изучает гораздо более интересные модели внимания:
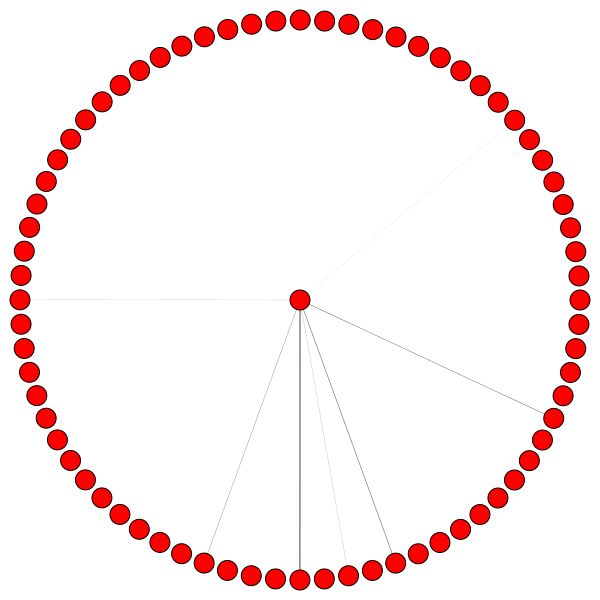
Слева мы видим, что 6 соседей получают невыплачиваемое количество внимания, и справа мы видим, что все внимание сосредоточено на одного соседа .
Наконец, еще 2 интересных шаблонов - сильный край самостоятельного края слева и справа, мы видим, что один сосед привлекает большую часть внимания, тогда как остальное в равной степени распределяется по всем остальным окрестностям:
Важное примечание: все визуализации PPI возможны только для первого слоя GAT. По какой -то причине коэффициенты внимания для второго и третьего слоев составляют почти все 0 (хотя я достиг опубликованных результатов).
Еще один способ понять, что GAT не изучает интересные модели внимания на CORA (то есть, что это обучение постоянному вниманию), - это рассматривать веса соседства узла как распределение вероятностей, расчет энтропии и накапливая информацию по окрестностям каждого узла.
Мы хотели бы, чтобы распределения внимания Гата были искажены. В Orange вы можете увидеть, как выглядит гистограмма для идеальных равномерных распределений, и в светло -голубом вы можете увидеть обученные распределения - они точно такие же!
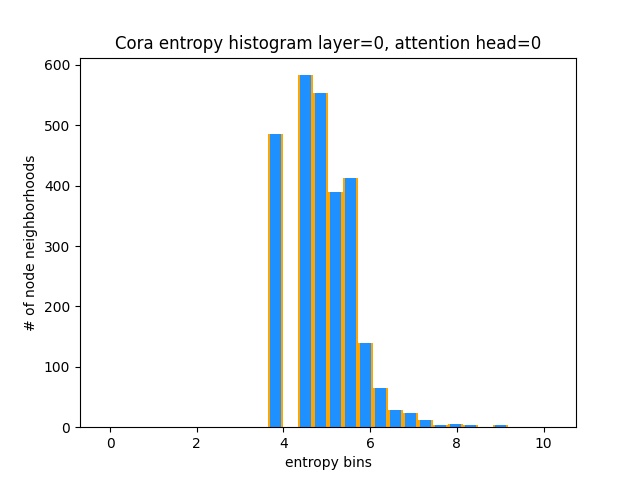
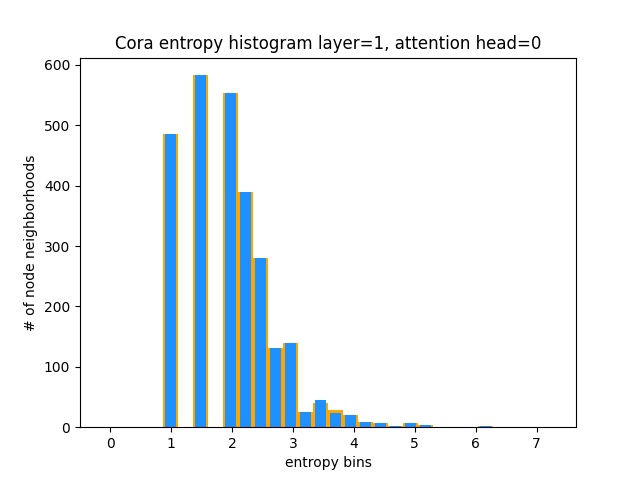
Я застроил только одну голову с первого слоя (из 8), потому что они все одинаковы!
С другой стороны, PPI изучает гораздо более интересные модели внимания:
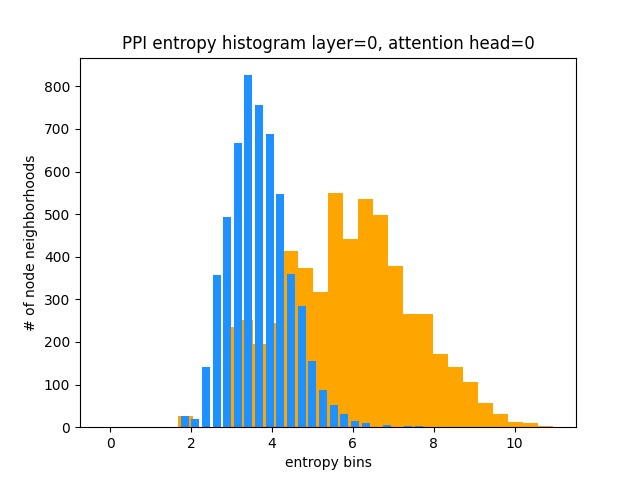
Как и ожидалось, гистограмма энтропии равномерной распределения лежит справа (оранжевый), поскольку равномерные распределения имеют самую высокую энтропию.
Хорошо, мы увидели внимание! Что еще есть, чтобы визуализировать? Что ж, давайте визуализируем ученые вторжения из последнего слоя Гата. Выход GAT представляет собой тензор формы = (2708, 7), где 2708 - это количество узлов в CORA, а 7 - количество классов. После того, как мы проецируем эти 7-градусные векторы на 2D, используя t-sne, мы получим это:

Мы видим, что узлы с одной и той же меткой/классом примерно сгруппированы вместе - с этими представлениями легко обучить простой классификатор, который сообщит нам, к какому классу принадлежат узел.
Примечание: я тоже попробовал UMAP, но не получил более приятных результатов + у него много зависимостей, если вы хотите использовать их утилит.
Итак, мы говорили о том, что такое GNN, и что они могут сделать для вас (среди прочего).
Давайте запустим эту вещь! Следуйте следующим шагам:
git clone https://github.com/gordicaleksa/pytorch-GATcd path_to_repoconda env create из Project Directory (это создаст совершенно новую среду Conda).activate pytorch-gat (для выполнения сценариев из вашей консоли или настройки интерпретатора в вашем IDE) Вот и все! Он должен работать вне коробки для выполнения среды.
Пакет Pytorch Pip будет поставляться с некоторой версией Cuda/Cudnn с ним, но настоятельно рекомендуется заранее установить общеобразовательную CUDA, в основном из-за драйверов GPU. Я также рекомендую использовать установщик Miniconda в качестве способа получить Conda в вашей системе. Следите за точками 1 и 2 этой установки и используйте самые современные версии Miniconda и Cuda/Cudnn для вашей системы.
Просто запустите jupyter notebook от вас консоли Anaconda, и она откроет сеанс в вашем браузере по умолчанию.
Откройте The Annotated GAT.ipynb , и вы готовы играть!
ПРИМЕЧАНИЕ. Если вы получите DLL load failed while importing win32api: The specified module could not be found
Просто сделайте pip uninstall pywin32 , а затем pip install pywin32 или conda install pywin32 должен его исправить!
Вам просто нужно связать среду Python, которую вы создали в разделе «Настройка».
К вашему сведению, моя реализация GAT достигает опубликованных результатов:
82-83% на тестовых узлах0.973 показателя Micro-F1 (и на самом деле еще выше) Все, что необходимо для обучения Gat на CORA, уже установлено. Чтобы запустить его (из консоли), просто позвоните:
python training_script_cora.py
Вы также можете потенциально:
--should_visualize -чтобы визуализировать данные графика--should_test -чтобы оценить GAT на тестовую часть данных--enable_tensorboard -чтобы начать сохранение метрик (точность, потеря) Код хорошо прокомментирован, поэтому вы можете (надеюсь) понять, как работает сама обучение.
Сценарий будет:
models/checkpoints/models/binaries/runs/ , просто запустите tensorboard --logdir=runs из вашей Anaconda, чтобы визуализировать ее То же самое касается обучения на PPI, просто запустите python training_script_ppi.py . PPI гораздо более громко, поэтому, если у вас нет сильного графического процессора с по крайней мере 8 ГБ, вам нужно добавить флаг- --force_cpu для обучения GAT на процессоре. В качестве альтернативы вы можете попробовать уменьшить размер партии до 1 или сделать модель более тонкой.
Вы можете визуализировать метрики во время обучения, позвонив в tensorboard --logdir=runs из вашей консоли и вставая http://localhost:6006/ url в свой браузер:
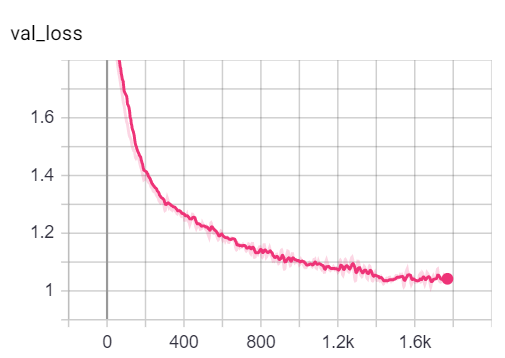
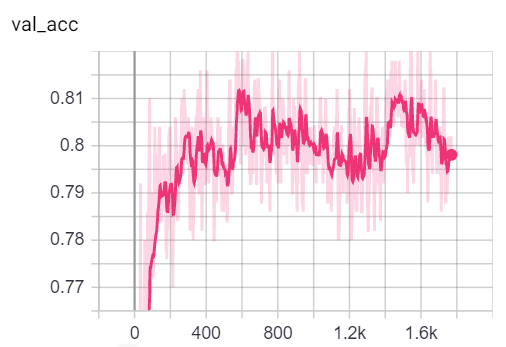
Примечание: разделение поездов Коры кажется намного сложнее, чем проверка и тесты, рассматривая показатели потери и точности.
Сказав, что большая часть веселья на самом деле лежит в сценарии playground.py .
Я добавил 3 реализации GAT - некоторые концептуально легче понять, некоторые более эффективны. Наиболее интересным и трудным для понимания является реализация 3. Реализация 1 и реализация 2 отличается от тонких деталей, но в основном делает то же самое.
Совет о том, как подходить к коду:
Если вы хотите профилировать 3 реализации, просто установите переменную playground_fn на PLAYGROUND.PROFILE_GAT в playground.py .
Есть 2 параметра, о которых вы можете позаботиться:
store_cache - установите на True , если вы хотите сохранить результаты профилирования памяти/времени послеskip_if_profiling_info_cached - установить в True , если вы хотите извлечь информацию о профилировании из кэша Результаты будут сохранены в data/ in memory.dict и timing.dict Dictionares (Pickle).
Примечание. Реализация № 3, безусловно, является наиболее оптимизированной - вы можете увидеть детали в коде.
Я также добавил profile_sparse_matrix_formats , если вы хотите получить некоторое знакомство с различными матричными разреженными форматами, такими как COO , CSR , CSC , LIL и т. Д.
Если вы хотите визуализировать встраивание T-SNE, внимание или встраивание, установите переменную playground_fn на PLAYGROUND.VISUALIZE_GAT и установите visualization_type на:
VisualizationType.ATTENTION - Если вы хотите визуализировать внимание в районах узловVisualizationType.EMBEDDING - Если вы хотите визуализировать встраивание (через t -sne)VisualizationType.ENTROPY - если вы хотите визуализировать гистограммы энтропии И вы получите сумасшедшие визуализации, подобные этим (опция VisualizationType.ATTENTION .
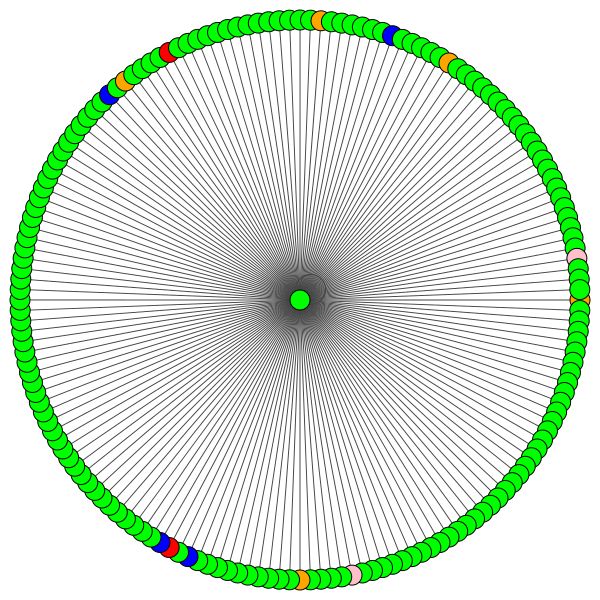
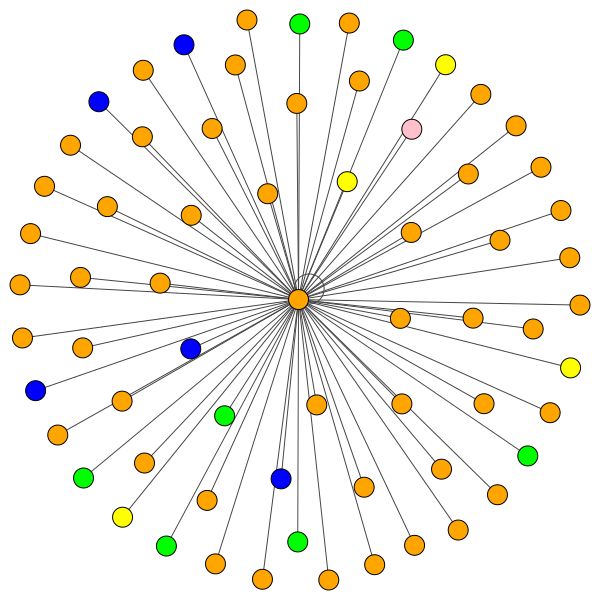
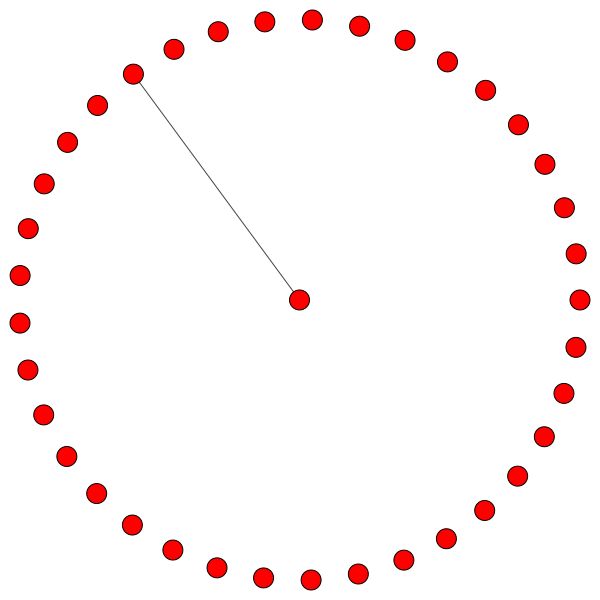
Слева вы можете увидеть узел с высшей степенью во всем наборе данных CORA.
Если вам интересно, почему они выглядят как круг, то это потому, что я использовал макет layout_reingold_tilford_circular , которая особенно хорошо подходит для графов дерева (поскольку мы визуализируем узел и его соседей, этот подграф фактически является m-ary Tree).
Но вы также можете использовать различные алгоритмы рисования, такие как kamada kawai (справа) и т. Д.
Не стесняйтесь просматривать код и играть с заговором, обращая внимание на разные слои GAT, построив различные районы узлов или головы внимания. Вы также можете легко изменить количество слоев в вашем GAT, хотя мелкие GNN, как правило, выполняют наилучшие наборы гомофильных графиков в маленьком мире.
Если вы хотите визуализировать CORA/PPI, просто установите playground_fn на PLAYGROUND.VISUALIZE_DATASET , и вы получите результаты от этой Readme.
Требования к HW сильно зависят от данных графика, которые вы используете. Если вы просто хотите поиграть с Cora , вы готовы пойти с графическим процессором 2+ ГБ .
Это требует (в сети цитаты CORA):
Сравните это с оборудованием, необходимым даже для самых маленьких трансформаторов!
С другой стороны, набор данных PPI гораздо более высока. Вам понадобится GPU с 8+ ГБ VRAM, или вы можете уменьшить размер партии до 1 и сделать модель «стройной» и, таким образом, попытаться уменьшить потребление VRAM.
sparse API PytorchЕсли у вас есть представление о том, как реализовать GAT с помощью Sparse API Pytorch, пожалуйста, не стесняйтесь отправлять PR. Лично у меня были трудности с их API, это в бета -версии, и сомнительно, возможно ли вообще сделать реализацию столь же эффективной, как и моя реализация 3, используя ее.
Во -вторых, я до сих пор не уверен, почему GAT достигает сообщений о результатах на PPI, в то время как в более глубоких слоях есть некоторые очевидные числовые проблемы, которые проявляются всеми коэффициентами внимания, равны 0.
Если у вас возникли трудности с пониманием Гата, я сделал подробный обзор бумаги в этом видео:
Я также снял проходное видео об этом репо (сосредоточившись на потенциальных боли) и блог для начала работы с Graph ML в целом! ❤
У меня есть еще несколько видео, которые могли бы помочь вам понять GNN:
Я нашел эти репо полезными (при разработке этого):
Если вы найдете этот код полезным, пожалуйста, укажите следующее:
@misc{Gordić2020PyTorchGAT,
author = {Gordić, Aleksa},
title = {pytorch-GAT},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-GAT}},
}


