pytorch GAT
1.0.0
Este repositorio contiene una implementación de Pytorch del papel GAT original (: Link: Veličković et al.).
Tiene como objetivo hacer que sea fácil comenzar a jugar y aprender sobre GAT y GNNS en general.
¡Las redes neuronales gráficas son una familia de redes neuronales que se ocupan de señales definidas sobre gráficos!
Los gráficos pueden modelar muchos fenómenos naturales interesantes, por lo que los verá usados en todas partes desde:
¡Y todo el camino a la física de partículas en Large Hedron Collider (LHC), detección de noticias falsas y la lista sigue y sigue!
GAT es un representante de los GNN espaciales (convolucionales). Como CNNS tuvo un tremendo éxito en el campo de la visión por computadora, los investigadores decidieron generalizarlo a los gráficos y ¡aquí estamos! ?
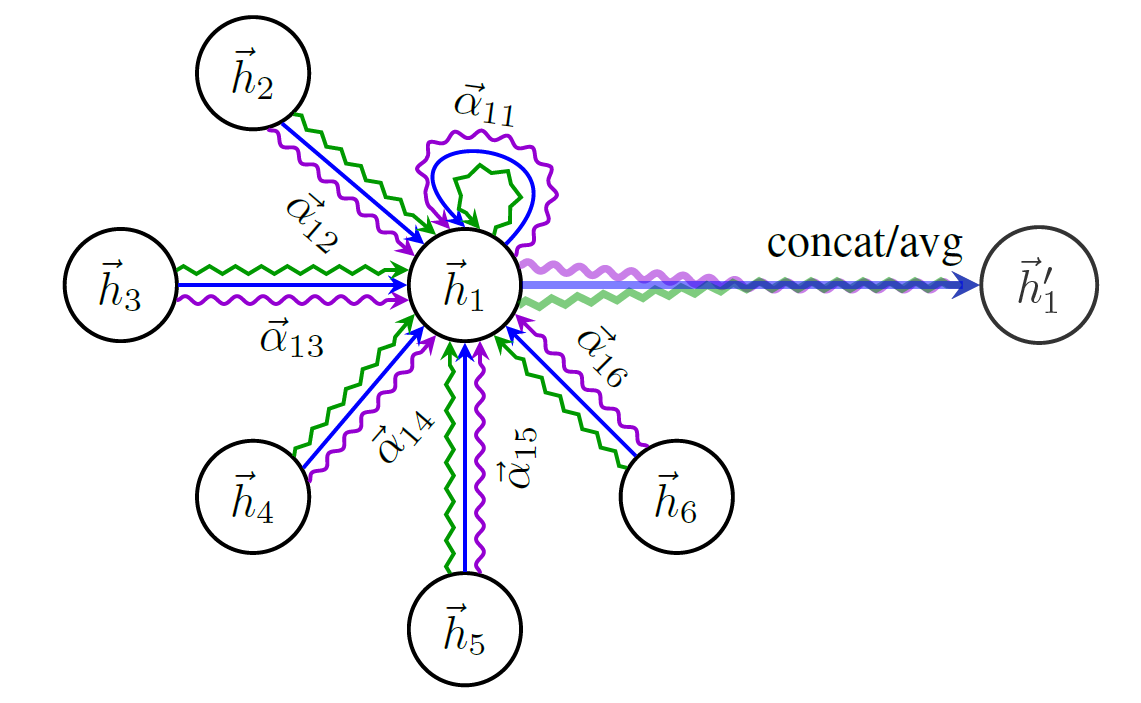
Aquí hay un esquema de la estructura de GAT:
No puede comenzar a hablar de GNN sin mencionar el conjunto de datos de gráficos más famoso: Cora .
Los nodos en Cora representan trabajos de investigación y los enlaces son, lo adivinó, citas entre esos documentos.
He agregado una utilidad para visualizar Cora y hacer un análisis básico de red. Así es como se ve Cora:

El tamaño del nodo corresponde a su grado (es decir, el número de bordes en/salientes). El grosor del borde corresponde aproximadamente a cómo "popular" o "conectado" es ese borde ( el borde es el término nerd, verifique el código).
Y aquí hay una trama que muestra la distribución de grado en Cora:
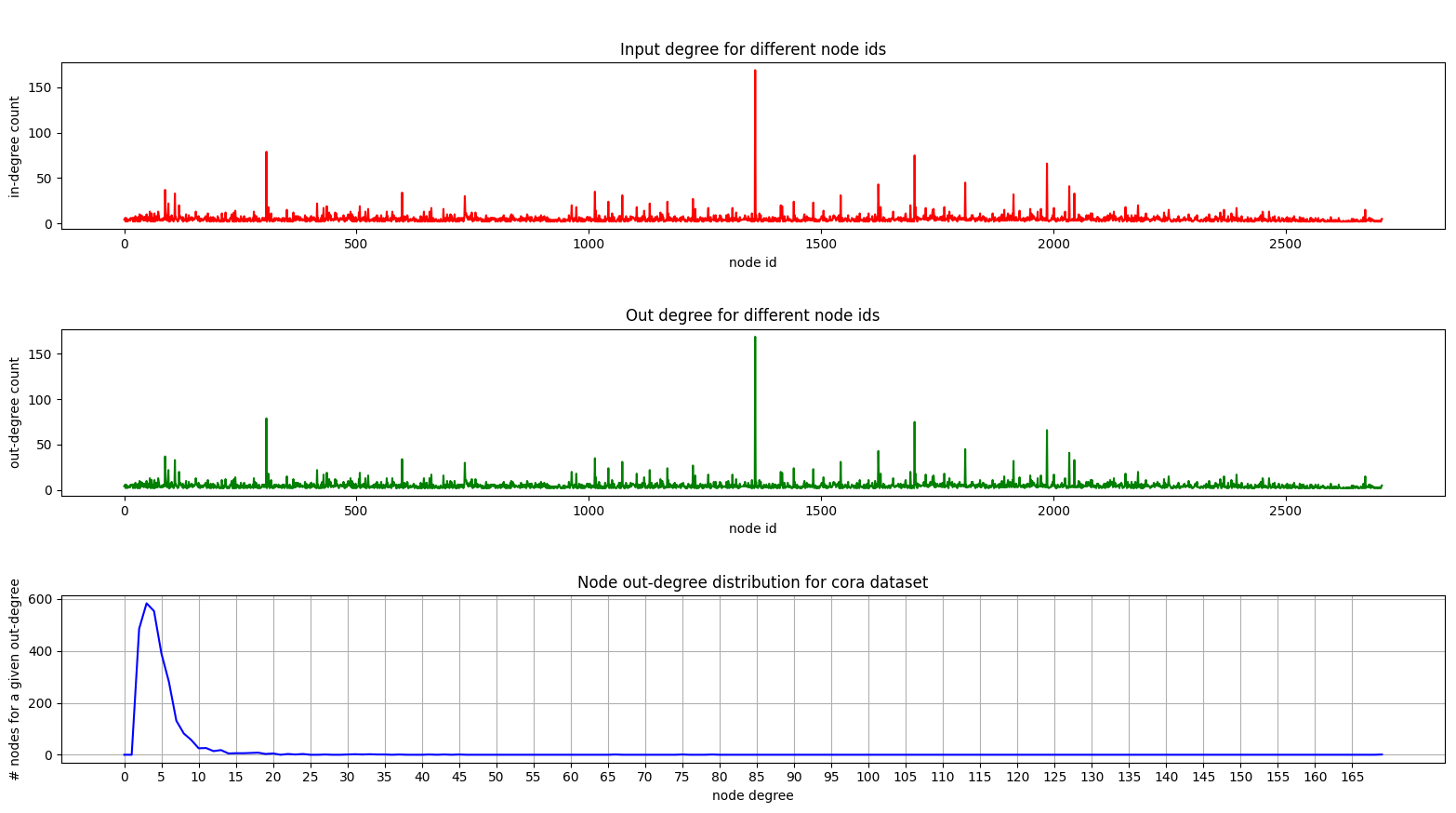
Los gráficos de grado y fuera son las mismas ya que estamos tratando con un gráfico no dirigido.
En la trama inferior (distribución de grado) puede ver un pico interesante en el rango [2, 4] . Esto significa que la mayoría de los nodos tienen un pequeño número de bordes, ¡pero hay 1 nodo que tiene 169 bordes! (El gran nodo verde)
Una vez que tenemos un modelo GAT totalmente entrenado, podemos visualizar la atención que han aprendido ciertos "nodos".
Los nodos usan la atención para decidir cómo agregar su vecindario, suficiente charla, veamos:
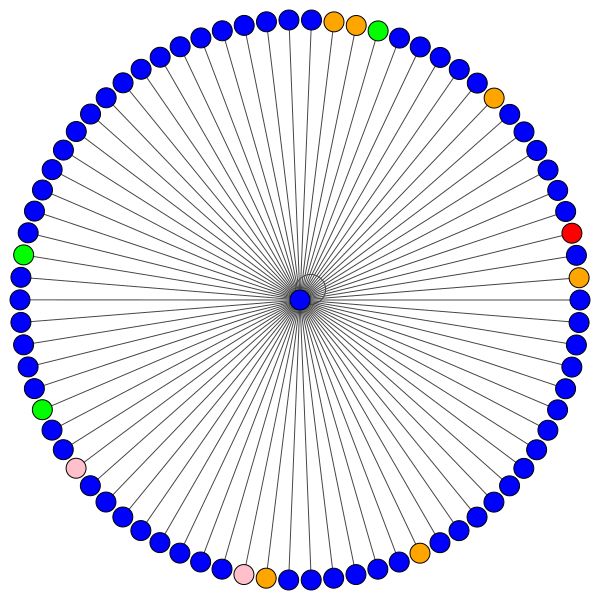
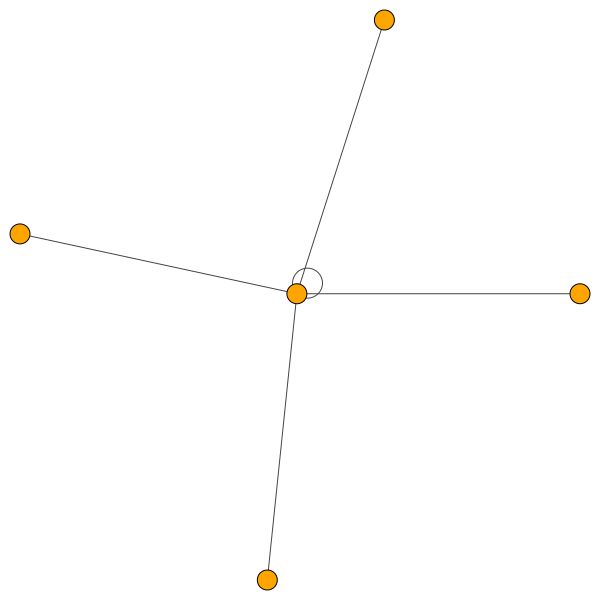
Este es uno de los nodos de Cora que tiene la mayor cantidad de bordes (citas). Los colores representan los nodos de la misma clase. Puedes ver claramente 2 cosas de esta trama:
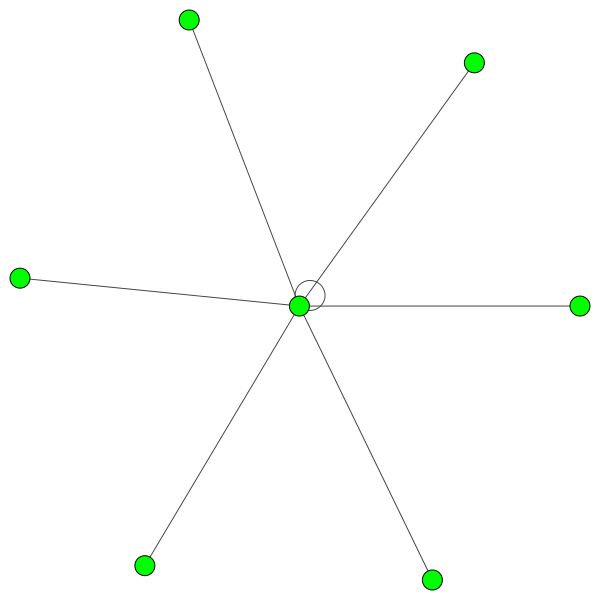
Reglas similares se mantienen para barrios más pequeños. Observe también los bordes de sí mismo:
Por otro lado, PPI está aprendiendo patrones de atención mucho más interesantes:
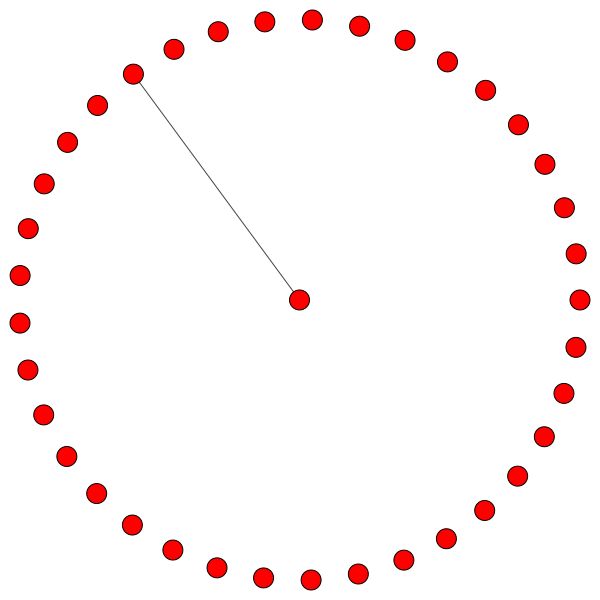
A la izquierda podemos ver que 6 vecinos reciben una cantidad de atención no desplegable y, a la derecha, podemos ver que toda la atención se centra en un solo vecino .
Finalmente, 2 patrones más interesantes: una fuerte ventaja a la izquierda y a la derecha podemos ver que un solo vecino está recibiendo una mayor parte de la atención, mientras que el resto se distribuye igualmente en el resto del vecindario:
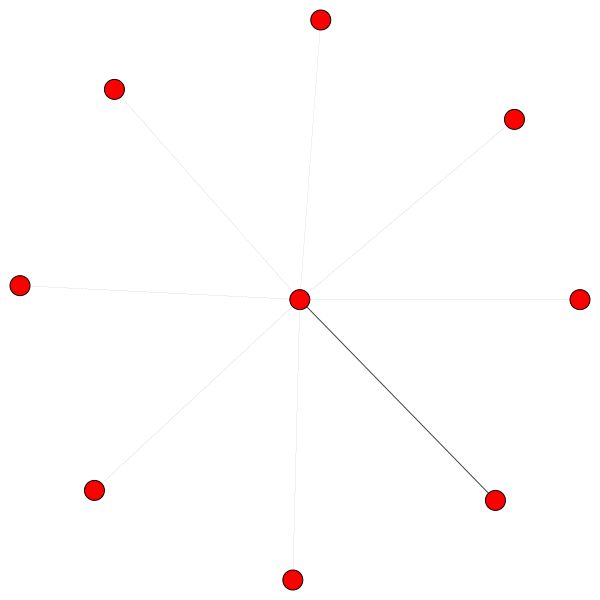
Nota importante: Todas las visualizaciones PPI solo son posibles para la primera capa de GAT. Por alguna razón, los coeficientes de atención para la segunda y tercera capas son casi todas las 0 (aunque logré los resultados publicados).
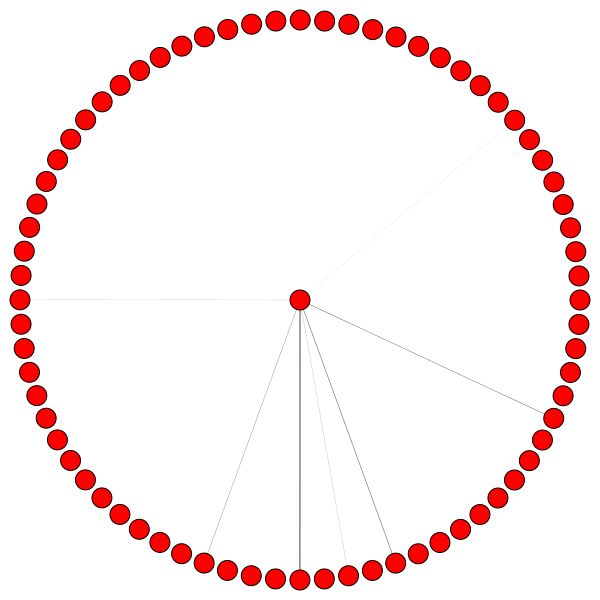
Otra forma de entender que GAT no está aprendiendo patrones de atención interesantes en Cora (es decir, que está aprendiendo la atención constante) es tratar los pesos de atención del vecindario del nodo como una distribución de probabilidad, calcular la entropía y acumular la información en el vecindario de cada nodo.
Nos encantaría que las distribuciones de atención de Gat estuvieran sesgadas. Puede ver en naranja cómo se ve el histograma para distribuciones de uniformes ideales, y puede ver en azul claro las distribuciones aprendidas: ¡son exactamente iguales!
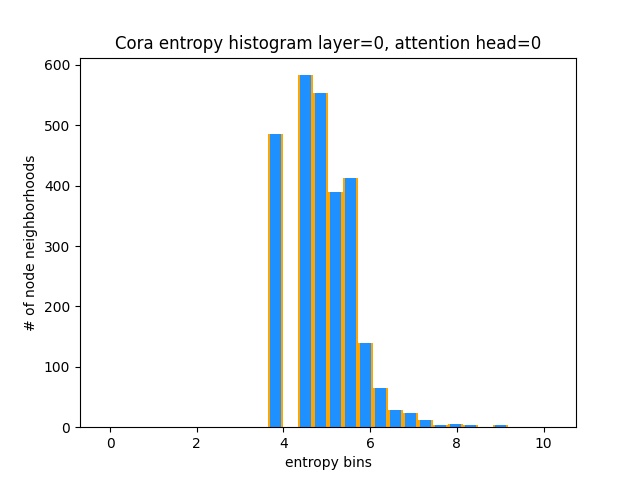
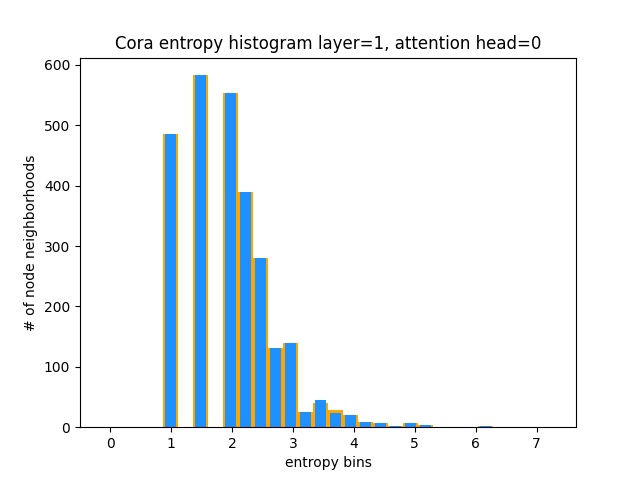
¡He planeado solo una cabeza de atención de la primera capa (de 8) porque son todos iguales!
Por otro lado, PPI está aprendiendo patrones de atención mucho más interesantes:
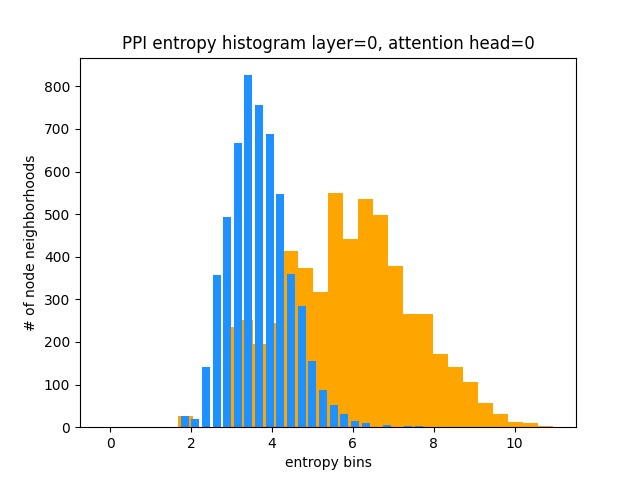
Como se esperaba, el histograma de entropía de distribución uniforme se encuentra a la derecha (naranja) ya que las distribuciones uniformes tienen la entropía más alta.
Ok, ¡hemos visto atención! ¿Qué más hay para visualizar? Bueno, visualicemos los incrustaciones aprendidas de la última capa de GAT. La salida de GAT es un tensor de forma = (2708, 7) donde 2708 es el número de nodos en Cora y 7 es el número de clases. Una vez que proyectamos esos vectores de 7 dim en 2D, usando T-SNE, obtenemos esto:

Podemos ver que los nodos con la misma etiqueta/clase se agrupan más o menos: con estas representaciones es fácil entrenar un clasificador simple en la parte superior que nos indique a qué clase pertenece el nodo.
NOTA: También he probado UMAP pero no obtuve resultados más agradables + tiene muchas dependencias si desea usar su planeo utilizado.
Así que hablamos sobre qué son los GNN y lo que pueden hacer por usted (entre otras cosas).
¡Hagamos que esto funcione! Sigue los siguientes pasos:
git clone https://github.com/gordicaleksa/pytorch-GATcd path_to_repoconda env create desde el directorio de proyectos (esto creará un entorno de condena nuevo).activate pytorch-gat (para ejecutar scripts desde su consola o configurar el intérprete en su IDE) ¡Eso es todo! Debe funcionar archivo de ejecución.YML de uso de casa fuera de la caja que se ocupa de las dependencias.
El paquete Pytorch Pip vendrá con alguna versión de CUDA/CUDNN, pero se recomienda encarecidamente que instale un CUDA de todo el sistema de antemano, principalmente debido a los controladores de GPU. También recomiendo usar el instalador de Miniconda como una forma de obtener conda en su sistema. Siga los puntos 1 y 2 de esta configuración y use las versiones más actualizadas de Miniconda y Cuda/Cudnn para su sistema.
Simplemente ejecute jupyter notebook desde su consola Anaconda y abrirá una sesión en su navegador predeterminado.
¡Abra The Annotated GAT.ipynb y estará listo para jugar!
NOTA: Si obtiene DLL load failed while importing win32api: The specified module could not be found
¡Simplemente pip uninstall pywin32 y luego pip install pywin32 o conda install pywin32 debería arreglarlo!
Solo necesita vincular el entorno Python que creó en la sección Configuración.
FYI, My Gat Implementation logra los resultados publicados:
82-83% en los nodos de prueba0.973 micro-F1 (y en realidad aún más alto) Todo lo necesario para entrenar a GAT en Cora ya está configurado. Para ejecutarlo (desde la consola) solo llame:
python training_script_cora.py
También podrías potencialmente:
--should_visualize -para visualizar los datos de su gráfico--should_test -para evaluar el GAT en la parte de prueba de los datos--enable_tensorboard -para comenzar a guardar las métricas (precisión, pérdida) El código está bien comentado para que pueda (con suerte) comprender cómo funciona la capacitación en sí.
El guión:
models/checkpoints/models/binaries/runs/ , simplemente ejecute tensorboard --logdir=runs desde su anaconda para visualizarla Lo mismo ocurre con el entrenamiento en PPI, simplemente ejecute python training_script_ppi.py . PPI tiene mucho más hambre de GPU, por lo que si no tiene una GPU fuerte con al menos 8 GB, necesitará agregar la bandera --force_cpu para entrenar GAT en CPU. Alternativamente, puede intentar reducir el tamaño del lote a 1 o hacer que el modelo sea más delgado.
Puede visualizar las métricas durante la capacitación, llamando tensorboard --logdir=runs desde su consola y pegando el http://localhost:6006/ url en su navegador:
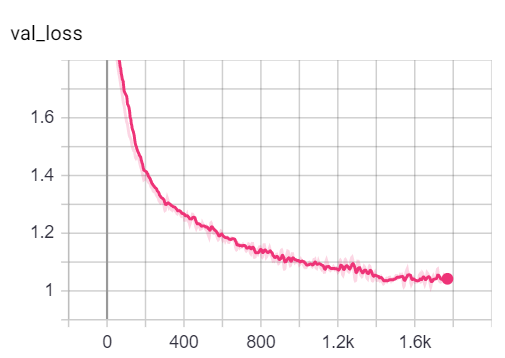
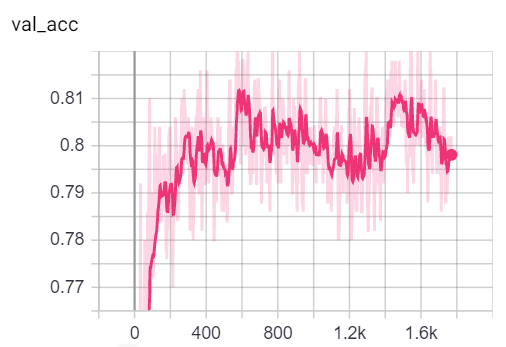
Nota: La división del tren de Cora parece ser mucho más difícil que la validación y las divisiones de pruebas que analizan las métricas de pérdida y precisión.
Habiendo dicho que la mayor parte de la diversión en realidad se encuentra en el guión playground.py .
He agregado 3 implementaciones de GAT: algunas son conceptualmente más fáciles de entender que algunos son más eficientes. El más interesante y más difícil de entender es la implementación 3. Implementación 1 y la implementación 2 difieren en detalles sutiles, pero básicamente hacen lo mismo.
Consejos sobre cómo abordar el código:
Si desea perfilar las 3 implementaciones, simplemente establezca la variable playground_fn en PLAYGROUND.PROFILE_GAT en playground.py .
Hay 2 parámetros que puede preocuparse:
store_cache : establezca en True si desea guardar los resultados de perfiles de memoria/tiempo después de ejecutarloskip_if_profiling_info_cached - Establecer en True si desea extraer la información de perfil de Cache Los resultados se almacenarán en data/ In memory.dict and timing.dict Dictionaries (Pickle).
Nota: La implementación #3 es, con mucho, la más optimizada: puede ver los detalles del código.
También he agregado profile_sparse_matrix_formats si desea familiarizarse con diferentes formatos dispersos de matriz como COO , CSR , CSC , LIL , etc.
Si desea visualizar las incrustaciones T-SNE, la atención o las incrustaciones establezcan la variable playground_fn en PLAYGROUND.VISUALIZE_GAT y establezca el visualization_type en:
VisualizationType.ATTENTION : si desea visualizar la atención en los vecindarios del nodoVisualizationType.EMBEDDING : si desea visualizar los incrustaciones (a través de T -SNE)VisualizationType.ENTROPY : si desea visualizar los histogramas de entropía Y obtendrás visualizaciones locas como estas ( VisualizationType.ATTENTION Opción):
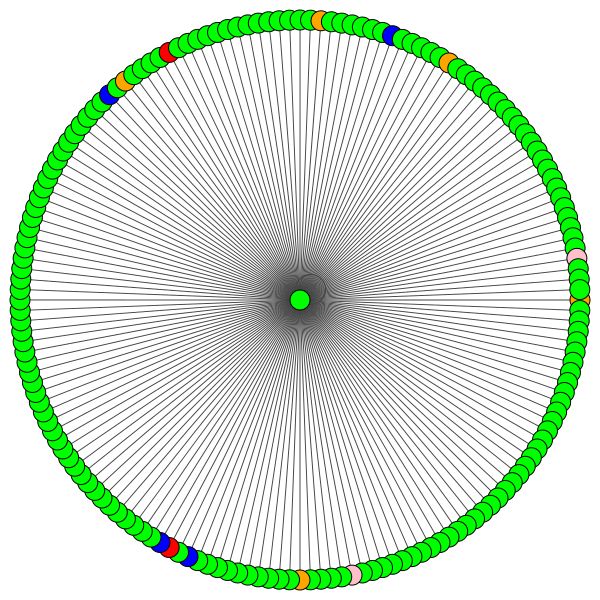
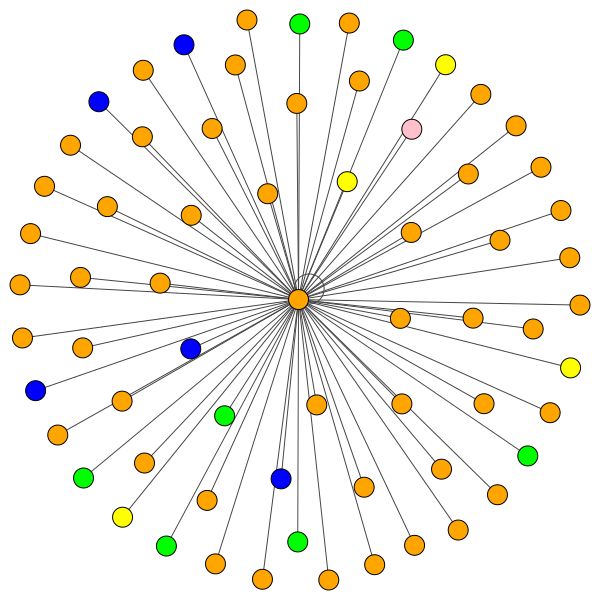
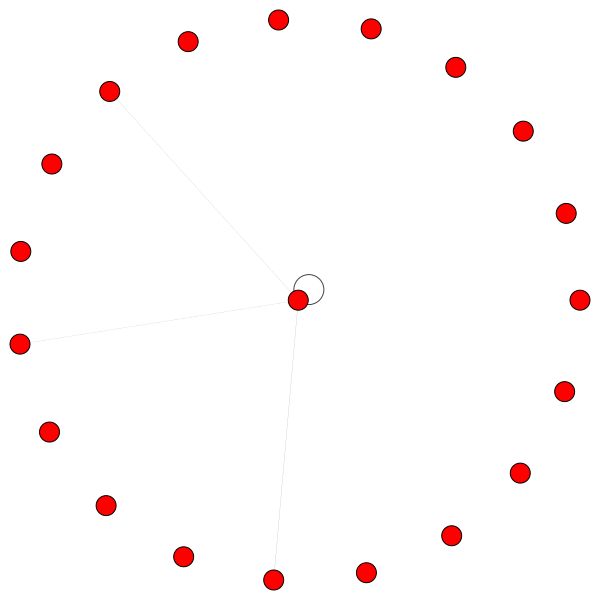
A la izquierda puede ver el nodo con el más alto grado en todo el conjunto de datos Cora.
Si se pregunta por qué se ven como un círculo, es porque he usado el diseño layout_reingold_tilford_circular , que es particularmente adecuado para gráficos como árboles (ya que estamos visualizando un nodo y sus vecinos, este subgrafio es efectivamente un árbol m-ary ).
Pero también puede usar diferentes algoritmos de dibujo como kamada kawai (a la derecha), etc.
Siéntase libre de pasar por el código y jugar con la atención de diferentes capas de GAT, trazando diferentes vecindarios de nodos o cabezas de atención. También puede cambiar fácilmente el número de capas en su GAT, aunque los GNN poco profundos tienden a funcionar lo mejor en conjuntos de datos de gráficos homofílicos en el mundo pequeño.
Si desea visualizar Cora/PPI, simplemente establezca el playground_fn en PLAYGROUND.VISUALIZE_DATASET y obtendrá los resultados de este ReadMe.
Los requisitos de HW dependen en gran medida de los datos de gráficos que utilizará. Si solo quieres jugar con Cora , eres bueno para ir con una GPU de 2+ GBS .
Se necesita (en la red Cora Citation):
¡Compare esto con el hardware necesario incluso para los transformadores más pequeños!
Por otro lado, el conjunto de datos PPI tiene mucho más hambre de GPU. Necesitará una GPU con más de 8 GB de VRAM, o puede reducir el tamaño del lote a 1 y hacer que el modelo sea "más delgado" y, por lo tanto, tratar de reducir el consumo de VRAM.
sparse API de PytorchSi tiene una idea de cómo implementar GAT usando la escasa API de Pytorch, no dude en enviar un PR. Personalmente, tuve dificultades con su API, está en Beta, y es cuestionable si es posible hacer que una implementación sea tan eficiente como mi implementación 3 usándola.
En segundo lugar, todavía no estoy seguro de por qué GAT logra los resultados reportados en PPI, mientras que hay algunos problemas numéricos obvios en capas más profundas como se manifiesta por todos los coeficientes de atención iguales a 0.
Si tiene dificultades para comprender el GAT, hice una descripción en profundidad del documento en este video:
¡También hice un video de recorrido de este repositorio (enfocándome en los posibles puntos débiles) y un blog para comenzar con Graph ML en general! ❤️
Tengo algunos videos más que podrían ayudarlo a comprender GNNS:
Encontré estos repositorios útiles (mientras desarrollaba este):
Si encuentra útil este código, cite lo siguiente:
@misc{Gordić2020PyTorchGAT,
author = {Gordić, Aleksa},
title = {pytorch-GAT},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-GAT}},
}


