pytorch GAT
1.0.0
Repo ini berisi implementasi Pytorch dari kertas GAT asli (: tautan: Veličković et al.).
Ini bertujuan membuatnya mudah untuk mulai bermain dan belajar tentang GAT dan GNNs secara umum.
Grafik Neural Networks adalah keluarga jaringan saraf yang berurusan dengan sinyal yang ditentukan melalui grafik!
Grafik dapat memodelkan banyak fenomena alam yang menarik, jadi Anda akan melihatnya digunakan di mana -mana dari:
Dan semua jalan ke fisika partikel di Hedron Collider (LHC) yang besar, deteksi berita palsu dan daftarnya terus berlanjut!
GAT adalah perwakilan dari GNNs spasial (konvolusional). Karena CNNs memiliki keberhasilan luar biasa di bidang visi komputer, para peneliti memutuskan untuk menggeneralisasikannya ke grafik dan di sinilah kita! ?
Berikut adalah skema struktur GAT:
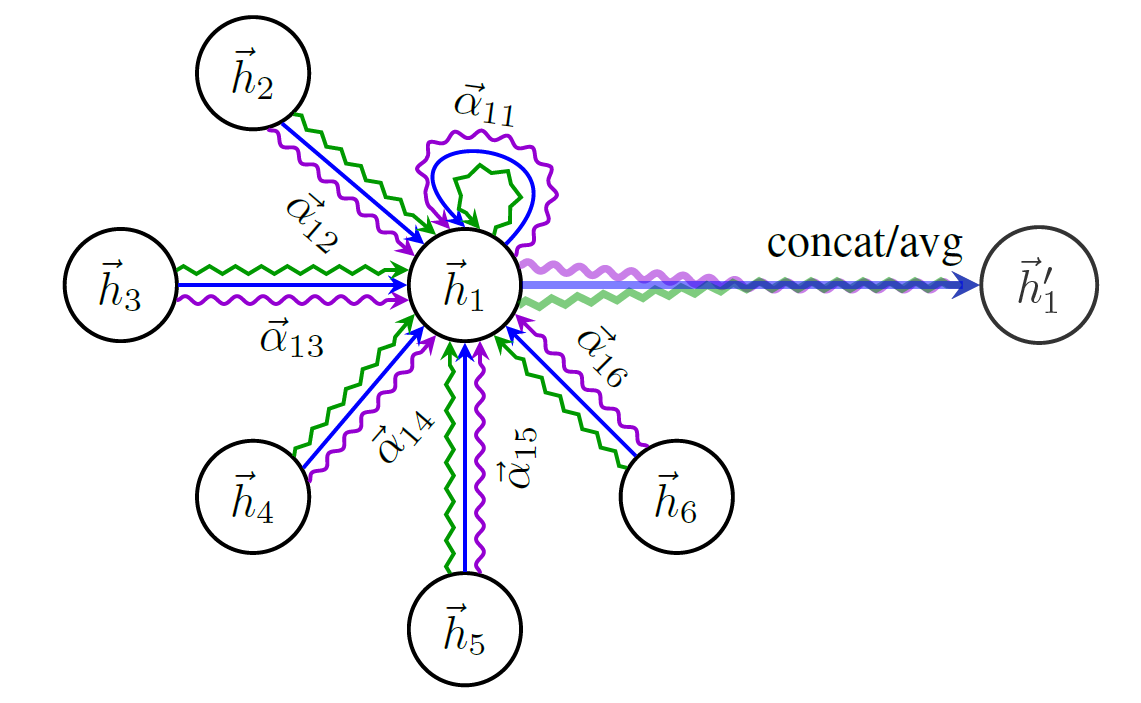
Anda tidak bisa hanya mulai berbicara tentang GNNs tanpa menyebutkan satu -satunya dataset grafik paling terkenal - Cora .
Node di Cora mewakili makalah penelitian dan tautannya, Anda dapat menebaknya, kutipan di antara makalah -makalah tersebut.
Saya telah menambahkan utilitas untuk memvisualisasikan CORA dan melakukan analisis jaringan dasar. Beginilah penampilan Cora:

Ukuran simpul sesuai dengan gelar (yaitu jumlah ujung/keluar/keluar). Ketebalan tepi secara kasar sesuai dengan seberapa "populer" atau "terhubung" tepi itu ( edge wetnesses adalah istilah kutu buku periksa kode.)
Dan di sini adalah plot yang menunjukkan distribusi derajat di Cora:
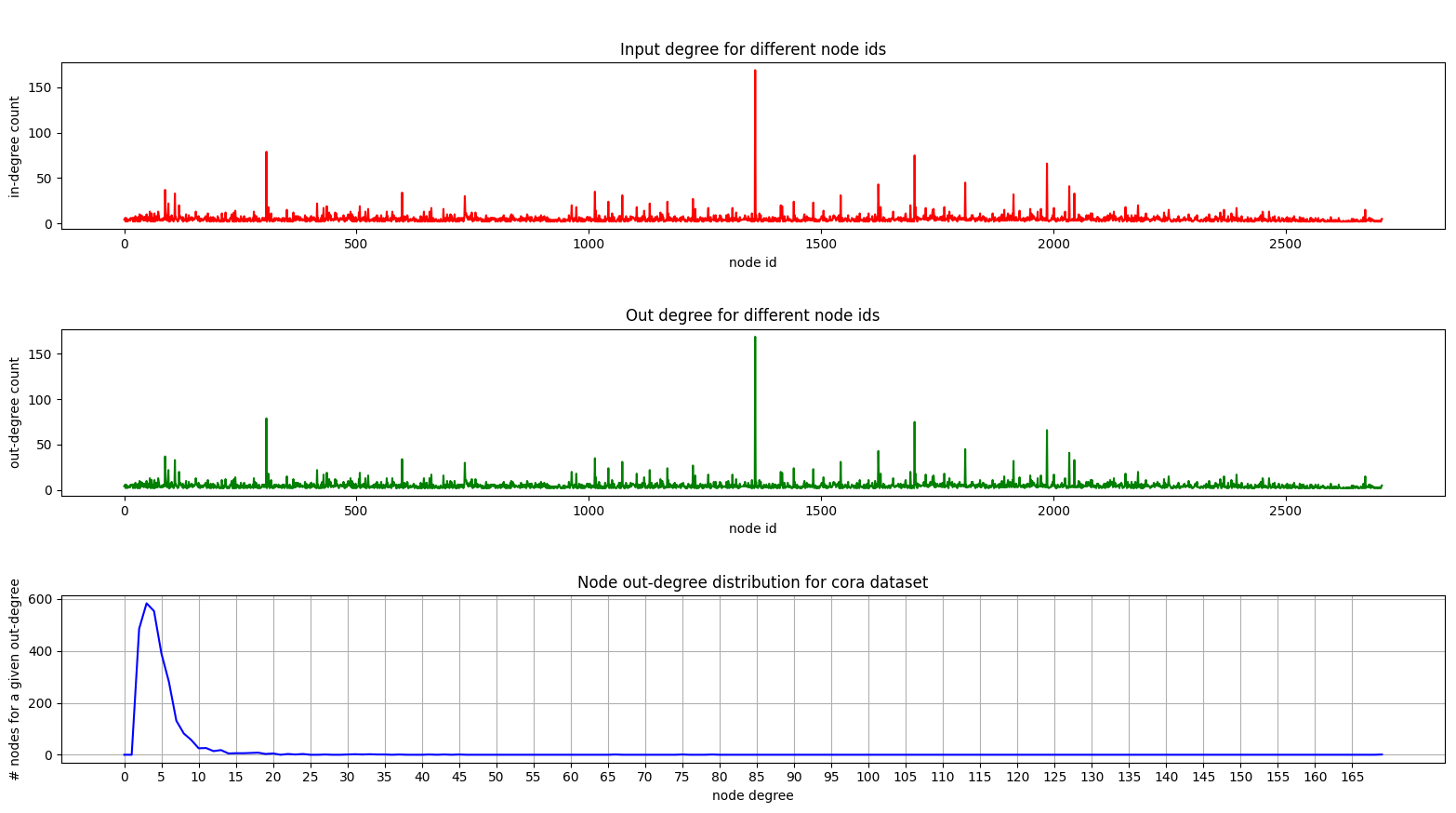
Plot masuk dan keluar adalah sama karena kami berurusan dengan grafik yang tidak diarahkan.
Di plot bawah (Distribusi derajat) Anda dapat melihat puncak yang menarik terjadi di kisaran [2, 4] . Ini berarti bahwa sebagian besar node memiliki sejumlah kecil tepi tetapi ada 1 node yang memiliki 169 tepi! (simpul hijau besar)
Setelah kami memiliki model GAT terlatih, kami dapat memvisualisasikan perhatian yang telah dipelajari "node" tertentu.
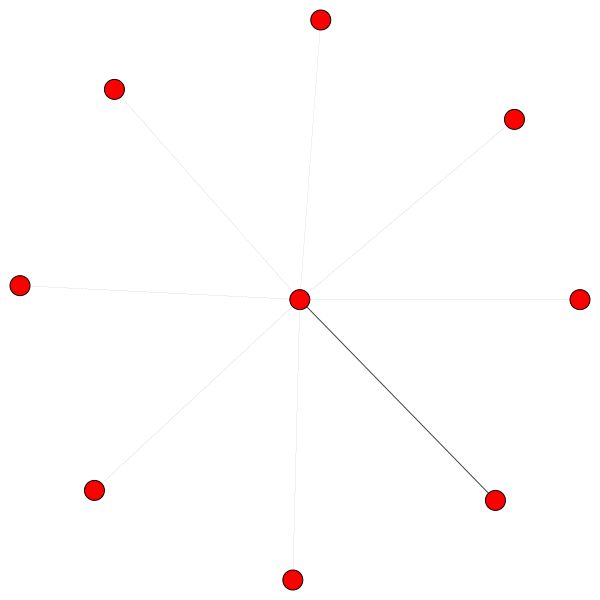
Node Gunakan perhatian untuk memutuskan bagaimana mengumpulkan lingkungan mereka, cukup bicara, mari kita lihat:
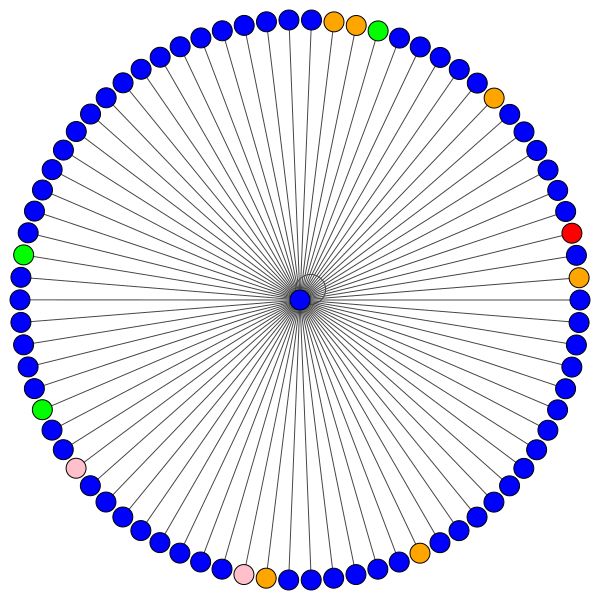
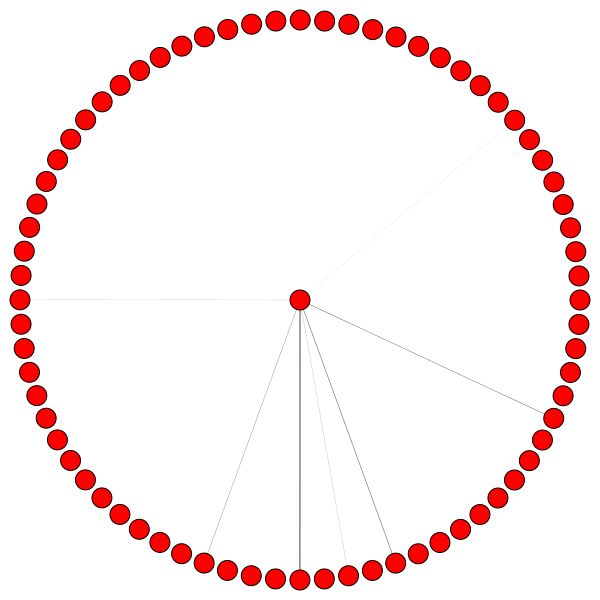
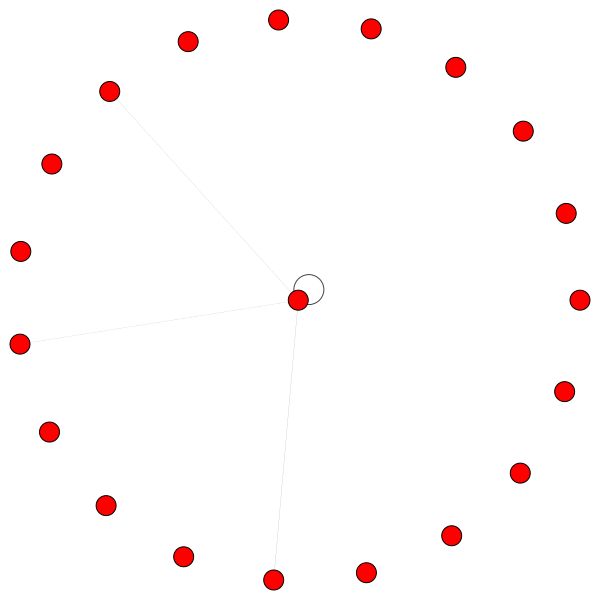
Ini adalah salah satu node Cora yang memiliki tepi terbanyak (kutipan). Warna mewakili node dari kelas yang sama. Anda dapat dengan jelas melihat 2 hal dari plot ini:
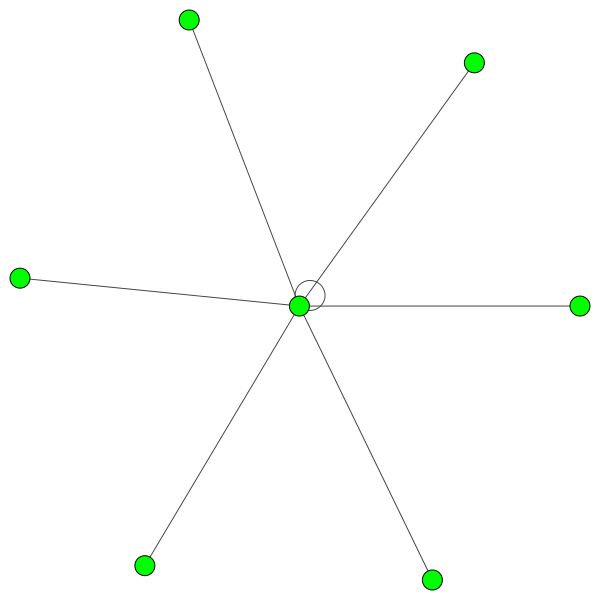
Aturan serupa berlaku untuk lingkungan yang lebih kecil. Perhatikan juga tepi diri:
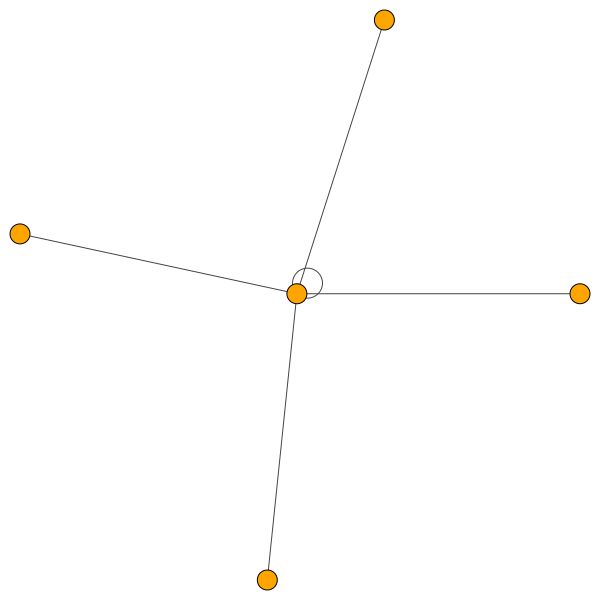
Di sisi lain, PPI mempelajari pola perhatian yang jauh lebih menarik:
Di sebelah kiri kita dapat melihat bahwa 6 tetangga menerima perhatian yang tidak dapat diabaikan dan di sebelah kanan kita dapat melihat bahwa semua perhatian difokuskan pada satu tetangga .
Akhirnya 2 pola yang lebih menarik - tepi diri yang kuat di sebelah kiri dan di sebelah kanan kita dapat melihat bahwa satu tetangga menerima sebagian besar perhatian sedangkan sisanya didistribusikan secara merata di seluruh lingkungan:
Catatan penting: Semua visualisasi PPI hanya mungkin untuk lapisan GAT pertama. Untuk beberapa alasan koefisien perhatian untuk lapisan kedua dan ketiga hampir semua 0s (meskipun saya mencapai hasil yang dipublikasikan).
Cara lain untuk memahami bahwa GAT tidak belajar pola perhatian yang menarik pada Cora (yaitu bahwa itu belajar perhatian konstan) adalah dengan memperlakukan bobot perhatian lingkungan simpul sebagai distribusi probabilitas, menghitung entropi, dan mengumpulkan info di setiap lingkungan node.
Kami akan menyukai distribusi perhatian Gat untuk condong. Anda dapat melihat dalam oranye bagaimana histogram terlihat untuk distribusi seragam yang ideal, dan Anda dapat melihat dengan warna biru muda distribusi yang dipelajari - mereka persis sama!
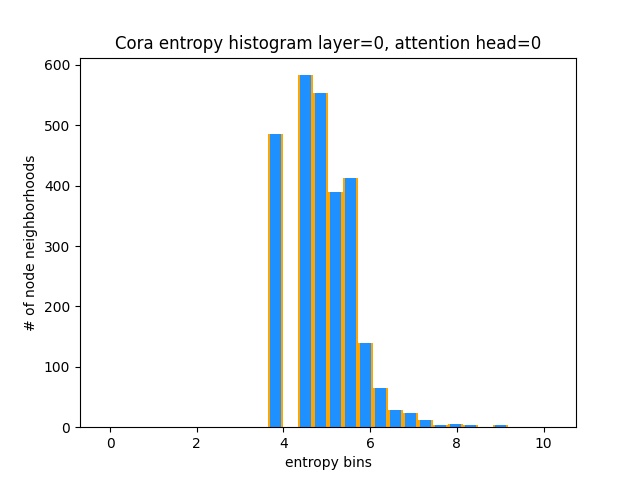
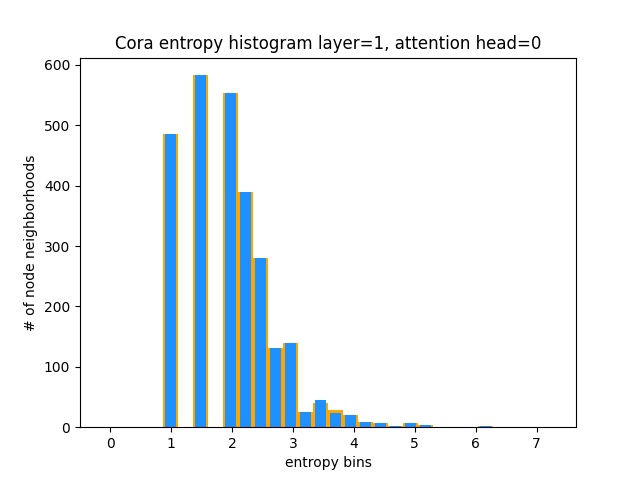
Saya telah merencanakan hanya satu kepala perhatian dari lapisan pertama (dari 8) karena semuanya sama!
Di sisi lain, PPI mempelajari pola perhatian yang jauh lebih menarik:
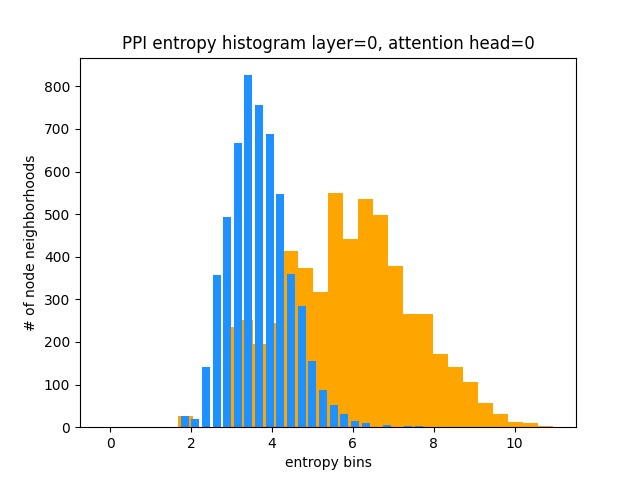
Seperti yang diharapkan, histogram entropi distribusi yang seragam terletak di sebelah kanan (oranye) karena distribusi seragam memiliki entropi tertinggi.
Oke, kami telah melihat perhatian! Apa lagi yang harus divisualisasikan? Baiklah, mari kita visualisasikan embeddings yang dipelajari dari lapisan terakhir Gat. Output GAT adalah tensor bentuk = (2708, 7) di mana 2708 adalah jumlah node dalam cora dan 7 adalah jumlah kelas. Setelah kami memproyeksikan vektor 7-DIM ke 2D, menggunakan T-SNE, kami mendapatkan ini:

Kita dapat melihat bahwa node dengan label/kelas yang sama secara kasar dikelompokkan bersama - dengan representasi ini, mudah untuk melatih classifier sederhana di atas yang akan memberi tahu kita kelas mana node itu milik.
Catatan: Saya sudah mencoba UMAP juga tetapi tidak mendapatkan hasil yang lebih baik + memiliki banyak dependensi jika Anda ingin menggunakan plot mereka.
Jadi kami berbicara tentang apa GNN, dan apa yang dapat mereka lakukan untuk Anda (antara lain).
Mari kita mulai berjalan! Ikuti langkah selanjutnya:
git clone https://github.com/gordicaleksa/pytorch-GATcd path_to_repoconda env create dari Project Directory (ini akan menciptakan lingkungan Conda baru).activate pytorch-gat (untuk menjalankan skrip dari konsol Anda atau mengatur juru bahasa di IDE Anda) Itu saja! Ini harus bekerja di luar kotak pelaksanaan lingkungan.yml file yang berurusan dengan dependensi.
Paket Pytorch Pip akan dibundel dengan beberapa versi CUDA/CUDNN dengan itu, tetapi sangat disarankan agar Anda memasang CUDA di seluruh sistem sebelumnya, sebagian besar karena driver GPU. Saya juga merekomendasikan menggunakan Installer Miniconda sebagai cara untuk mendapatkan Conda di sistem Anda. Ikuti poin 1 dan 2 dari pengaturan ini dan gunakan versi miniconda dan cudnn yang paling mutakhir untuk sistem Anda.
Cukup jalankan jupyter notebook dari Anda Anaconda Console dan itu akan membuka sesi di browser default Anda.
Buka The Annotated GAT.ipynb dan Anda siap bermain!
Catatan: Jika Anda mendapatkan DLL load failed while importing win32api: The specified module could not be found
Lakukan saja pip uninstall pywin32 dan kemudian pip install pywin32 atau conda install pywin32 harus memperbaikinya!
Anda hanya perlu menautkan lingkungan Python yang Anda buat di bagian pengaturan.
FYI, Implementasi GAT saya mencapai hasil yang dipublikasikan:
82-83% pada node uji0.973 mikro-F1 (dan sebenarnya bahkan lebih tinggi) Segala diperlukan untuk melatih GAT di Cora sudah diatur. Untuk menjalankannya (dari konsol), hubungi:
python training_script_cora.py
Anda juga bisa berpotensi:
--should_visualize -untuk memvisualisasikan data grafik Anda--should_test -untuk mengevaluasi GAT pada bagian uji data--enable_tensorboard -Untuk mulai menyimpan metrik (akurasi, kerugian) Kode ini dikomentari dengan baik sehingga Anda dapat (semoga) memahami bagaimana pelatihan itu sendiri bekerja.
Skrip akan:
models/checkpoints/models/binaries/runs/ , cukup jalankan tensorboard --logdir=runs dari anaconda Anda untuk memvisualisasikannya Hal yang sama berlaku untuk pelatihan tentang PPI, cukup jalankan python training_script_ppi.py . PPI jauh lebih haus GPU jadi jika Anda tidak memiliki GPU yang kuat dengan setidaknya 8 GB Anda, Anda harus menambahkan bendera --force_cpu untuk melatih Gat pada CPU. Anda dapat mencoba mengurangi ukuran batch menjadi 1 atau membuat model lebih ramping.
Anda dapat memvisualisasikan metrik selama pelatihan, dengan memanggil tensorboard --logdir=runs dari konsol Anda dan menempelkan http://localhost:6006/ url ke browser Anda:
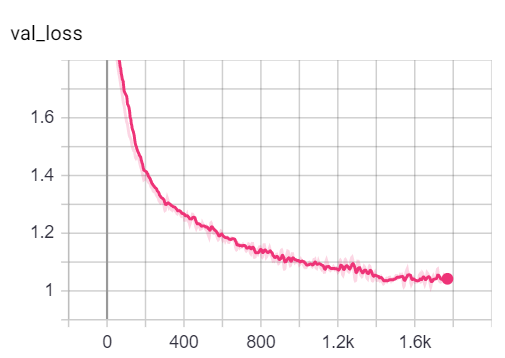
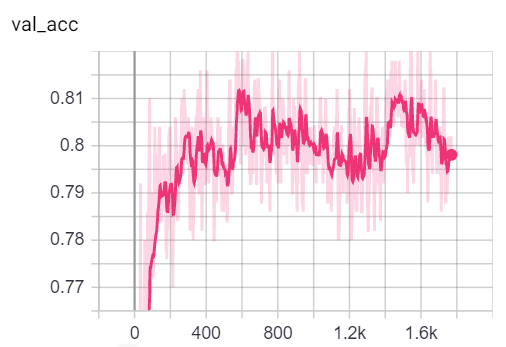
Catatan: Perpecahan kereta Cora tampaknya jauh lebih sulit daripada validasi dan pembelahan tes yang melihat metrik kehilangan dan akurasi.
Setelah mengatakan bahwa sebagian besar kesenangan sebenarnya terletak pada skrip playground.py .
Saya telah menambahkan 3 implementasi GAT - beberapa secara konseptual lebih mudah untuk memahami beberapa lebih efisien. Yang paling menarik dan paling sulit untuk dipahami adalah implementasi 3. Implementasi 1 dan implementasi 2 berbeda dalam detail halus tetapi pada dasarnya melakukan hal yang sama.
Saran tentang cara mendekati kode:
Jika Anda ingin profil 3 implementasi, cukup atur variabel playground_fn ke PLAYGROUND.PROFILE_GAT di playground.py .
Ada 2 param yang mungkin Anda pedulikan:
store_cache - Setel ke True jika Anda ingin menyimpan hasil profil memori/waktu setelah Anda menjalankannyaskip_if_profiling_info_cached - atur ke True jika Anda ingin menarik info profil dari cache Hasilnya akan disimpan dalam data/ dalam memory.dict dan timing.dict Kamus Diktik (Pickle).
Catatan: Implementasi #3 sejauh ini yang paling dioptimalkan - Anda dapat melihat detail dalam kode.
Saya juga menambahkan profile_sparse_matrix_formats jika Anda ingin mendapatkan keakraban dengan format matriks jarang yang berbeda seperti COO , CSR , CSC , LIL , dll.
Jika Anda ingin memvisualisasikan embedding T-SNE, perhatian atau embeddings atur variabel playground_fn ke PLAYGROUND.VISUALIZE_GAT dan atur visualization_type ke:
VisualizationType.ATTENTION - Jika Anda ingin memvisualisasikan perhatian di lingkungan simpulVisualizationType.EMBEDDING - Jika Anda ingin memvisualisasikan embeddings (melalui T -SNE)VisualizationType.ENTROPY - Jika Anda ingin memvisualisasikan histogram entropi Dan Anda akan mendapatkan visualisasi gila seperti ini ( VisualizationType.ATTENTION Opsi):
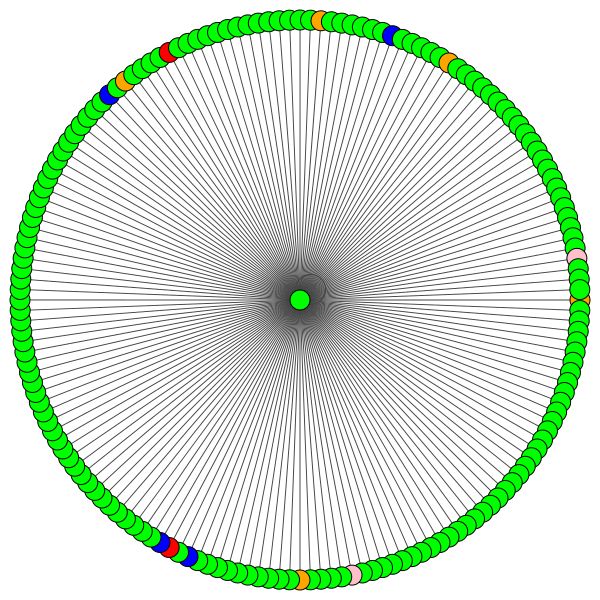
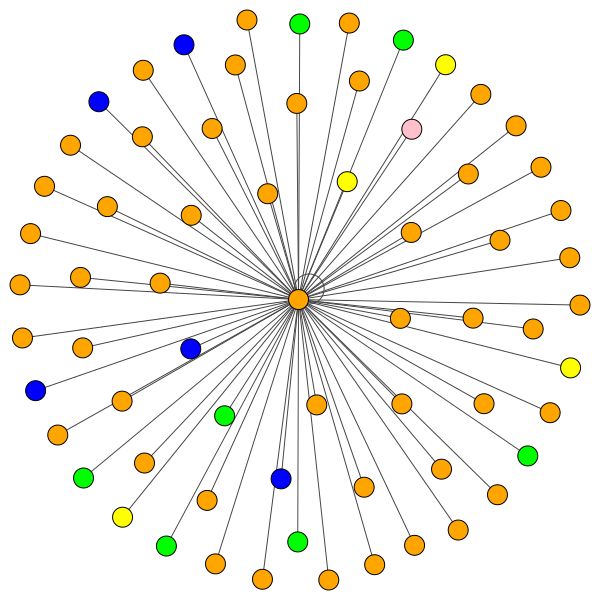
Di sebelah kiri Anda dapat melihat simpul dengan derajat tertinggi di seluruh dataset CORA.
Jika Anda bertanya-tanya mengapa ini terlihat seperti lingkaran, itu karena saya telah menggunakan tata letak layout_reingold_tilford_circular yang sangat cocok untuk grafik seperti pohon (karena kami memvisualisasikan sebuah node dan tetangga-tetangganya subgraph ini secara efektif merupakan pohon m-ary ).
Tetapi Anda juga dapat menggunakan algoritma gambar yang berbeda seperti kamada kawai (di sebelah kanan), dll.
Jangan ragu untuk membaca kode dan bermain dengan merencanakan perhatian dari berbagai lapisan GAT, merencanakan berbagai lingkungan simpul atau kepala perhatian. Anda juga dapat dengan mudah mengubah jumlah lapisan di GAT Anda, meskipun GNNs dangkal cenderung melakukan yang terbaik pada dataset grafik homofilik di dunia kecil.
Jika Anda ingin memvisualisasikan CORA/PPI, cukup atur playground_fn ke PLAYGROUND.VISUALIZE_DATASET dan Anda akan mendapatkan hasil dari readme ini.
Persyaratan HW sangat tergantung pada data grafik yang akan Anda gunakan. Jika Anda hanya ingin bermain dengan Cora , Anda baik -baik saja dengan GPU 2+ GBS .
Dibutuhkan (di jaringan kutipan cora):
Bandingkan ini dengan perangkat keras yang dibutuhkan bahkan untuk transformer terkecil!
Di sisi lain, dataset PPI jauh lebih haus GPU. Anda akan memerlukan GPU dengan 8+ GB VRAM, atau Anda dapat mengurangi ukuran batch menjadi 1 dan membuat model "lebih ramping" dan dengan demikian mencoba mengurangi konsumsi VRAM.
sparse APIJika Anda memiliki gagasan tentang cara mengimplementasikan GAT menggunakan API Pytorch yang jarang, jangan ragu untuk mengirimkan PR. Saya pribadi mengalami kesulitan dengan API mereka, itu dalam beta, dan dipertanyakan apakah mungkin untuk membuat implementasi seefisien implementasi saya 3 menggunakannya.
Kedua, saya masih tidak yakin mengapa GAT mencapai hasil yang dilaporkan pada PPI sementara ada beberapa masalah numerik yang jelas di lapisan yang lebih dalam seperti yang dimanifestasikan oleh semua koefisien perhatian sama dengan 0.
Jika Anda mengalami kesulitan memahami GAT, saya melakukan gambaran mendalam tentang makalah ini dalam video ini:
Saya juga membuat video walk-through dari repo ini (berfokus pada titik nyeri potensial), dan sebuah blog untuk memulai dengan grafik ML secara umum! ❤️
Saya memiliki beberapa video lagi yang selanjutnya dapat membantu Anda memahami GNNs:
Saya menemukan repo ini bermanfaat (saat mengembangkan yang ini):
Jika Anda menemukan kode ini bermanfaat, silakan kutip yang berikut:
@misc{Gordić2020PyTorchGAT,
author = {Gordić, Aleksa},
title = {pytorch-GAT},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-GAT}},
}


