pytorch GAT
1.0.0
Dieses Repo enthält eine Pytorch -Implementierung des ursprünglichen GAT -Papiers (: Link: Veličković et al.).
Es zielt darauf ab, das Spielen und Lernen von Gat und GNNs im Allgemeinen leicht zu machen.
Graph Neural Networks sind eine Familie von neuronalen Netzwerken, die sich mit Signalen befassen, die über Diagramme definiert sind!
Diagramme können viele interessante natürliche Phänomene modellieren, sodass Sie sie überall von:
und bis zur Teilchenphysik bei Large Hedron Collider (LHC), gefälschte Nachrichtenerkennung und der Liste geht weiter und weiter!
Gat ist ein Vertreter der räumlichen (Faltungs-) GNNs. Da CNNs im Bereich Computer Vision einen enormen Erfolg hatte, beschlossen die Forscher, es auf Grafiken zu verallgemeinern, und so sind wir hier! ?
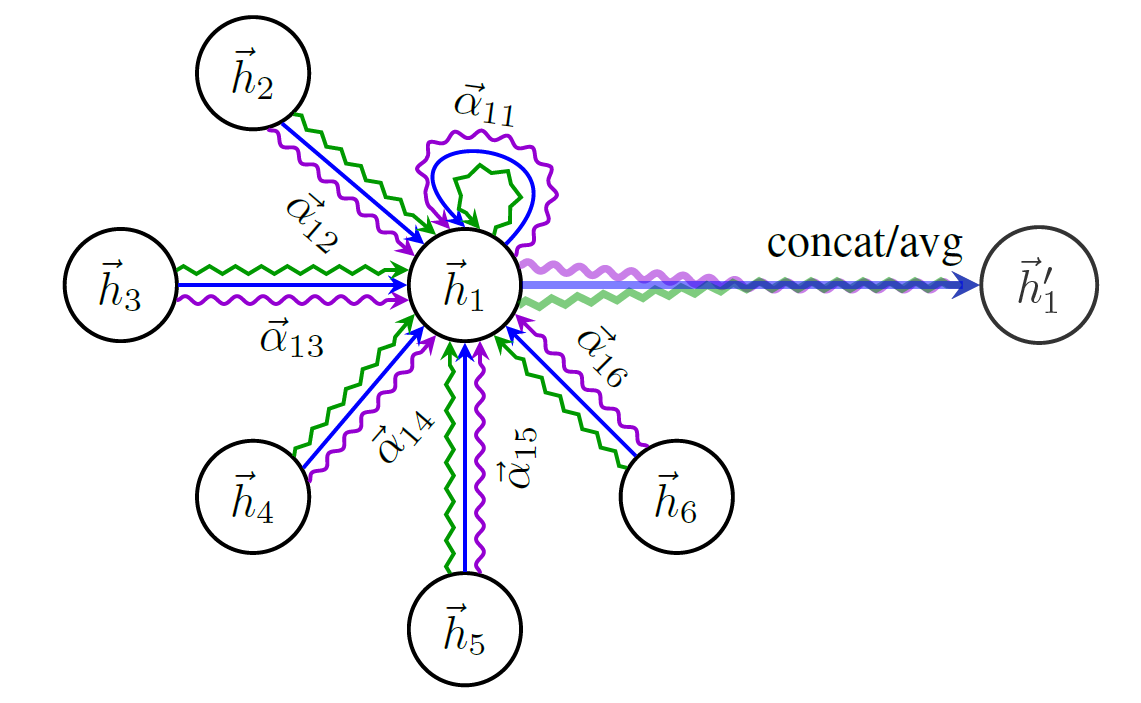
Hier ist ein Schema der Struktur von Gat:
Sie können nicht einfach über GNNs sprechen, ohne den berühmtesten Graph -Datensatz - Cora - zu erwähnen.
Knoten in Cora repräsentieren Forschungsarbeiten und die Links sind, wie Sie erraten haben, Zitate zwischen diesen Papieren.
Ich habe ein Dienstprogramm zur Visualisierung von CORA und eine grundlegende Netzwerkanalyse hinzugefügt. So sieht Cora aus:

Die Knotengröße entspricht ihrem Abschluss (dh der Anzahl der in/ausgehenden Kanten). Die Kantendicke entspricht ungefähr, wie "beliebt" oder "verbunden" diese Kante ist ( Edge zwischen den Nertern. Schauen Sie sich den Code an.)
Und hier ist ein Diagramm, das die Gradverteilung auf Cora zeigt:
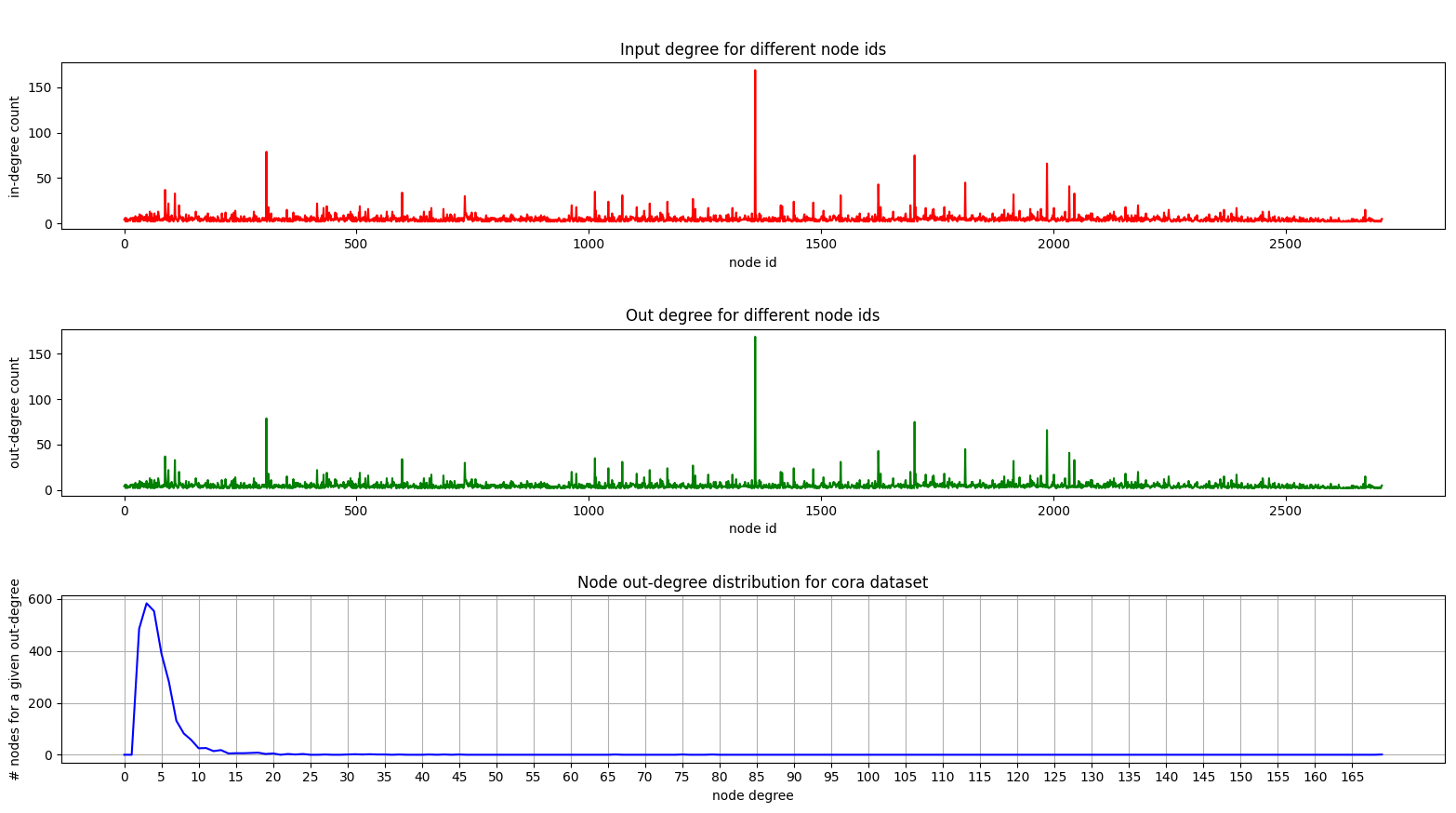
In- und Out -Grad -Diagramme sind gleich, da wir uns mit einem ungerichteten Diagramm befassen.
Auf dem unteren Diagramm (Gradverteilung) sehen Sie einen interessanten Peak im Bereich [2, 4] . Dies bedeutet, dass die Mehrheit der Knoten eine kleine Anzahl von Kanten hat, aber es gibt einen Knoten mit 169 Kanten! (der große grüne Knoten)
Sobald wir ein vollständig ausgebildetes GAT-Modell haben, können wir die Aufmerksamkeit, die bestimmte "Knoten" gelernt haben, visualisieren.
Knoten nutzen die Aufmerksamkeit, um zu entscheiden, wie sie ihre Nachbarschaft aggregieren können, genug Gespräche. Lassen Sie uns es sehen:
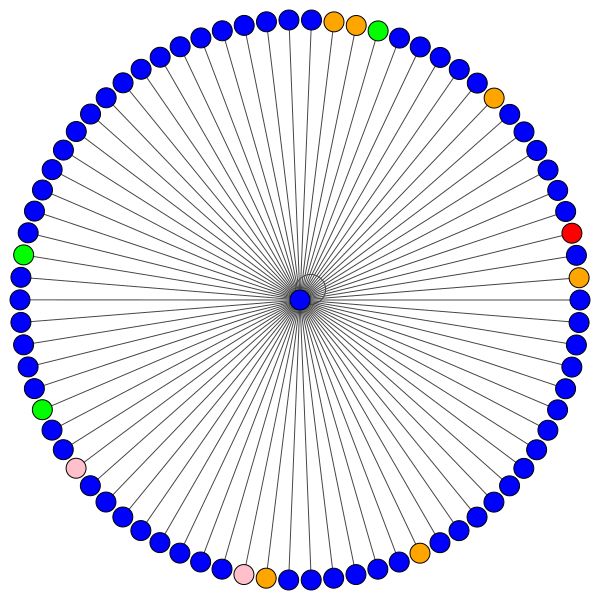
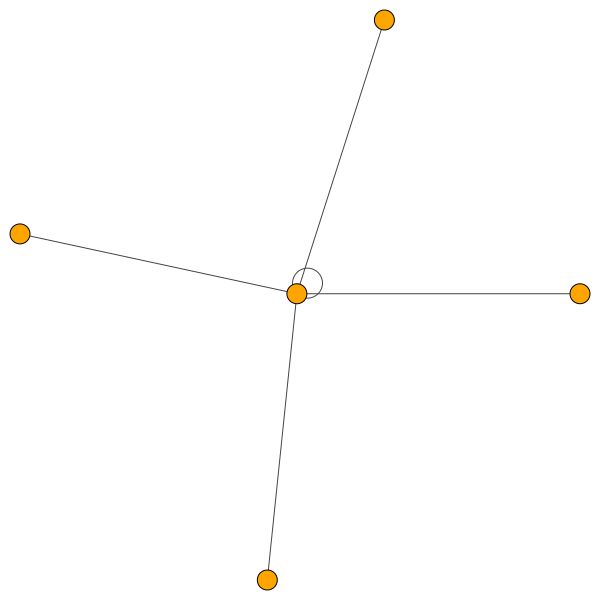
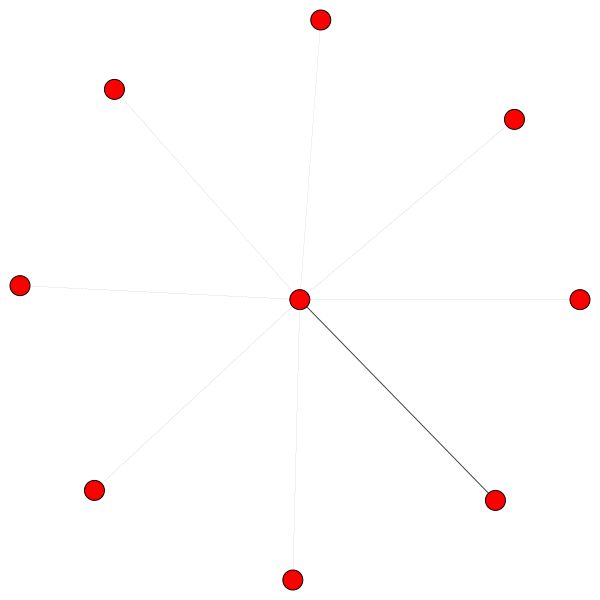
Dies ist einer von Coras Knoten, der die meisten Kanten (Zitate) hat. Die Farben repräsentieren die Knoten derselben Klasse. Sie können deutlich 2 Dinge aus dieser Handlung sehen:
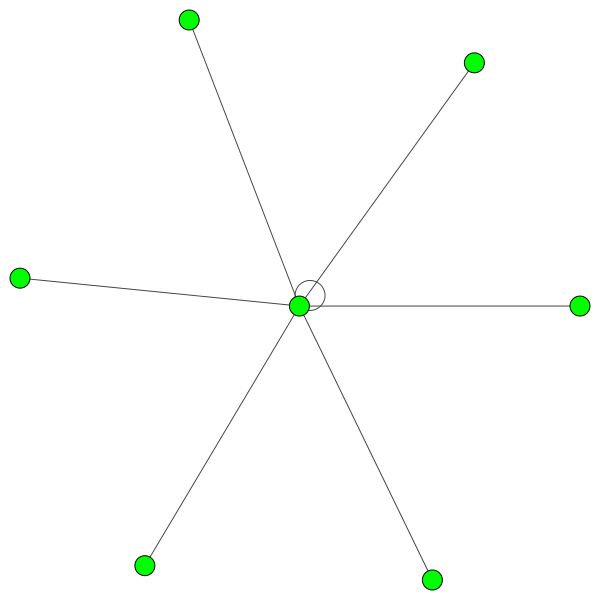
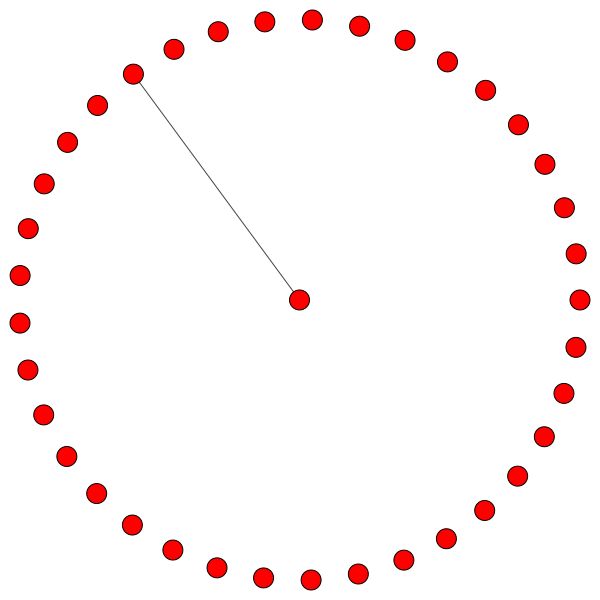
Ähnliche Regeln halten für kleinere Stadtteile. Beachten Sie auch die Selbstkanten:
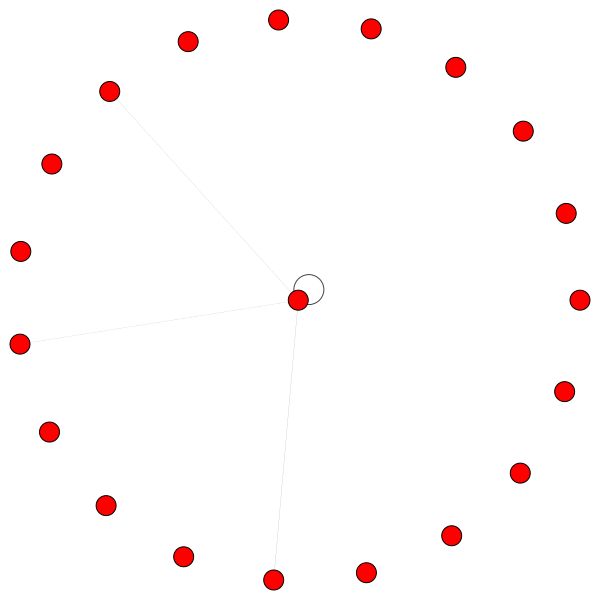
Andererseits lernt PPI viel interessantere Aufmerksamkeitsmuster:
Auf der linken Seite können wir sehen, dass 6 Nachbarn eine nicht zu vernachlässige Menge an Aufmerksamkeit erhalten, und rechts können wir sehen, dass die gesamte Aufmerksamkeit auf einen einzelnen Nachbarn gerichtet ist.
Schließlich 2 weitere interessante Muster - eine starke Selbstkante links und rechts können wir sehen, dass ein einzelner Nachbar einen Großteil der Aufmerksamkeit erhält, während der Rest über den Rest der Nachbarschaft gleichermaßen verteilt ist:
Wichtiger Hinweis: Alle PPI -Visualisierungen sind nur für die erste GAT -Schicht möglich. Aus irgendeinem Grund betragen die Aufmerksamkeitskoeffizienten für die zweite und dritte Schichten fast alle 0S (obwohl ich die veröffentlichten Ergebnisse erzielt habe).
Eine andere Möglichkeit zu verstehen, dass Gat keine interessanten Aufmerksamkeitsmuster für Cora (dh, dass es Lernkonstant ist), besteht darin, die Aufmerksamkeitsgewichte des Knoten -Nachbars als Wahrscheinlichkeitsverteilung, die Berechnung der Entropie zu berechnen und die Informationen über die Nachbarschaft der einzelnen Knoten zu sammeln.
Wir würden es lieben, Gats Aufmerksamkeitsverteilungen zu verdrängen. Sie können in Orange sehen, wie das Histogramm für ideale einheitliche Verteilungen aussieht, und Sie können in hellblau die gelernten Verteilungen sehen - sie sind genau gleich!
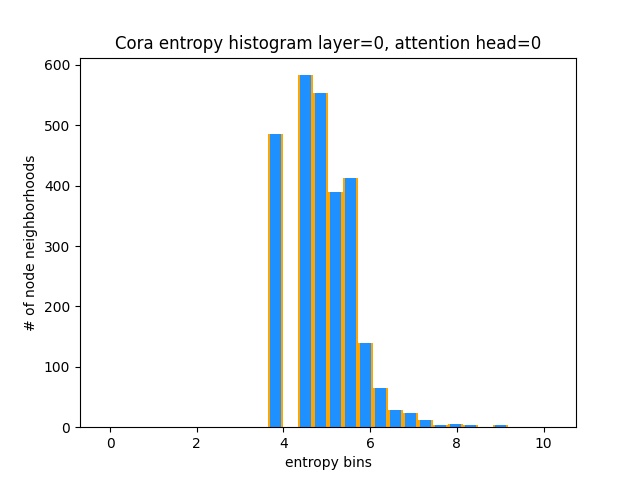
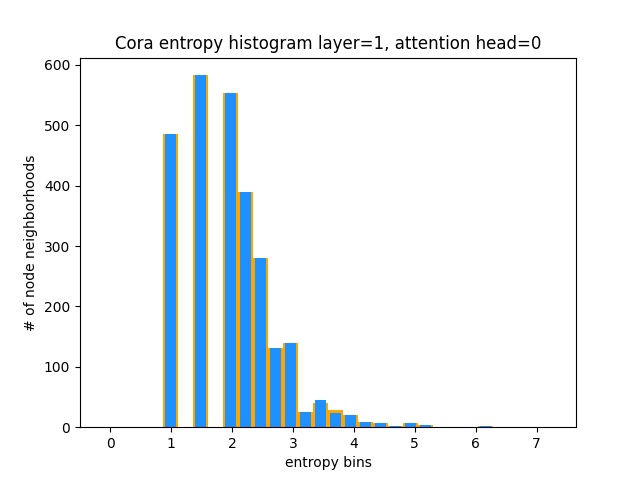
Ich habe nur einen einzigen Aufmerksamkeitskopf von der ersten Schicht (von 8) aufgetragen, weil sie alle gleich sind!
Andererseits lernt PPI viel interessantere Aufmerksamkeitsmuster:
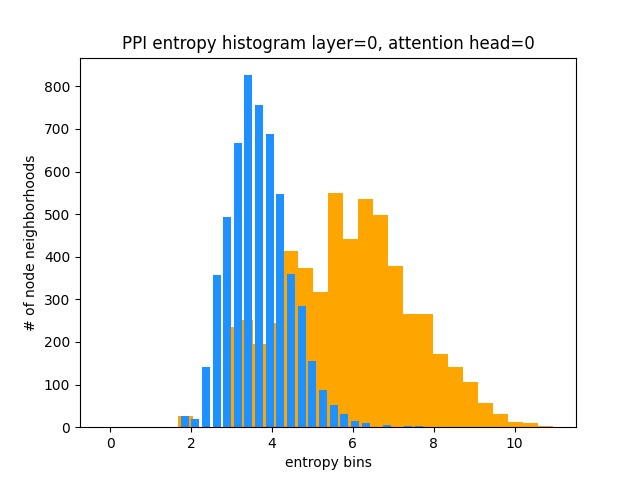
Wie erwartet liegt das einheitliche Verteilungs -Entropie -Histogramm rechts (orange), da einheitliche Verteilungen die höchste Entropie aufweisen.
Ok, wir haben Aufmerksamkeit gesehen! Was gibt es noch zu visualisieren? Lassen Sie uns die erlernten Einbettungen aus Gats letzter Schicht visualisieren. Die Ausgabe von Gat ist ein Tensor der Form = (2708, 7), wobei 2708 die Anzahl der Knoten in Cora und 7 die Anzahl der Klassen ist. Sobald wir diese 7-DIM-Vektoren mit T-SNE in 2D projizieren, bekommen wir Folgendes:

Wir können sehen, dass die Knoten mit demselben Etikett/derselben Klasse grob zusammengeklustert sind - mit diesen Darstellungen ist es einfach, einen einfachen Klassifikator darüber zu trainieren, der uns mitteilt, zu welcher Klasse der Knoten gehört.
HINWEIS: Ich habe auch UMAP ausprobiert, hat aber keine schöneren Ergebnisse erzielt + es hat viele Abhängigkeiten, wenn Sie ihren Handlungs -Util verwenden möchten.
Also haben wir darüber gesprochen, was GNNs sind und was sie für Sie tun können (unter anderem).
Lassen Sie uns dieses Ding zum Laufen bringen! Befolgen Sie die nächsten Schritte:
git clone https://github.com/gordicaleksa/pytorch-GATcd path_to_repoconda env create aus dem Projektverzeichnis aus (dadurch werden eine brandneue Conda -Umgebung geschaffen).activate pytorch-gat (zum Ausführen von Skripten aus Ihrer Konsole oder Einrichten des Interpreters in Ihrer IDE) Das war's! Es sollte eine optimale Ausführungsdatei von Environment.yml funktionieren, die sich mit Abhängigkeiten befasst.
Das Pytorch-PIP-Paket wird mit einer Version von CUDA/CUDNN mit ihm gebündelt. Es wird jedoch dringend empfohlen, dass Sie vorher ein systemweites CUDA installieren, hauptsächlich wegen der GPU-Treiber. Ich empfehle auch, das Miniconda -Installationsprogramm zu verwenden, um Conda auf Ihr System zu bringen. Folgen Sie durch die Punkte 1 und 2 dieses Setups und verwenden Sie die aktuellsten Versionen von Miniconda und CUDA/CUDNN für Ihr System.
Führen Sie einfach jupyter notebook von Ihnen Anaconda -Konsole aus und es wird eine Sitzung in Ihrem Standardbrowser eröffnen.
Öffnen Sie The Annotated GAT.ipynb und Sie sind bereit zu spielen!
HINWEIS: Wenn Sie DLL load failed while importing win32api: The specified module could not be found
pip uninstall pywin32 einfach und pip install pywin32 oder conda install pywin32 sollte es reparieren!
Sie müssen nur die Python -Umgebung verknüpfen, die Sie im Setup -Abschnitt erstellt haben.
Zu Ihrer Information, meine GAT -Implementierung erzielt die veröffentlichten Ergebnisse:
82-83% auf Testknoten0.973 Micro-F1-Score (und tatsächlich sogar höher) Alles, um Gat auf Cora zu trainieren, ist bereits eingerichtet. Um es auszuführen (von der Konsole) rufen Sie einfach an:
python training_script_cora.py
Sie könnten auch möglicherweise:
--should_visualize -hinzu, um Ihre Grafikdaten zu visualisieren--should_test -hinzu, um GAT im Testteil der Daten zu bewerten--enable_tensorboard -hinzu, um Metriken zu sparen (Genauigkeit, Verlust). Der Code ist gut kommentiert, sodass Sie (hoffentlich) verstehen können, wie das Training selbst funktioniert.
Das Skript wird:
models/checkpoints/models/binaries/runs/ Führen Sie einfach tensorboard --logdir=runs von Ihrer Anaconda aus, um sich zu visualisieren Gleiches gilt für das Training auf PPI. Führen Sie einfach python training_script_ppi.py aus. PPI ist viel mehr GPU-Hungry. Wenn Sie also keine starke GPU mit mindestens 8 GBs haben, müssen Sie das Flag- --force_cpu hinzufügen, um Gat auf der CPU zu trainieren. Sie können alternativ versuchen, die Stapelgröße auf 1 zu reduzieren oder das Modell schlanker zu machen.
Sie können die Metriken während des Trainings visualisieren, indem Sie tensorboard --logdir=runs von Ihrer Konsole aus und das Einfügen des http://localhost:6006/ url in Ihren Browser:
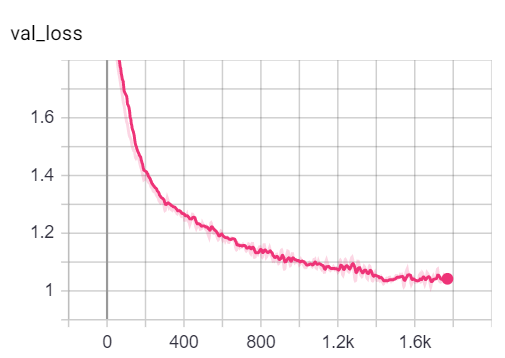
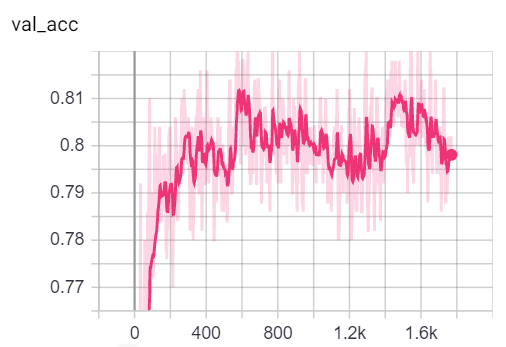
Hinweis: Coras Zugspaltung scheint viel schwieriger zu sein als die Validierungs- und Testspaltungen, die sich mit den Verlust- und Genauigkeitsmetriken befassen.
Allerdings liegt der größte Teil des Spaßes tatsächlich im Drehbuch für das playground.py .
Ich habe 3 GAT -Implementierungen hinzugefügt - einige sind konzeptionell einfacher zu verstehen, einige sind effizienter. Am interessantesten und am schwierigsten zu verstehen ist die Implementierung 3. Implementierung 1 und die Implementierung 2 unterscheiden sich in subtilen Details, tun jedoch im Grunde dasselbe.
Ratschläge zur Herangehensweise an den Code:
Wenn Sie die 3 Implementierungen profilieren möchten, stellen Sie einfach die Variable der playground_fn auf PLAYGROUND.PROFILE_GAT in playground.py ein.
Es gibt 2 Paramente, die Sie sich möglicherweise interessieren:
store_cache - auf True einstellen, wenn Sie nach dem Ausführen die Ergebnisse des Speicher-/Zeitprofils speichern möchtenskip_if_profiling_info_cached - Setzen Sie auf True , wenn Sie die Profiling -Informationen aus dem Cache ziehen möchten Die Ergebnisse werden in data/ in memory.dict und timing.dict .
Hinweis: Implementierung Nr. 3 ist bei weitem am optimiertesten - Sie können die Details im Code sehen.
Ich habe auch profile_sparse_matrix_formats hinzugefügt, wenn Sie mit verschiedenen Matrix -Sparse -Formaten wie COO , CSR , CSC , LIL usw. vertraut machen möchten.
Wenn Sie T-SNE-Einbettungen, Aufmerksamkeit oder Einbettung visualisieren möchten, setzen Sie die Variable playground_fn auf PLAYGROUND.VISUALIZE_GAT und setzen Sie die visualization_type auf:
VisualizationType.ATTENTION - Wenn Sie die Aufmerksamkeit in den Node -Vierteln visualisieren möchtenVisualizationType.EMBEDDINGVisualizationType.ENTROPY - Wenn Sie die Entropie -Histogramme visualisieren möchten Und Sie werden verrückte Visualisierungen wie diese ( VisualizationType.ATTENTION -Option):
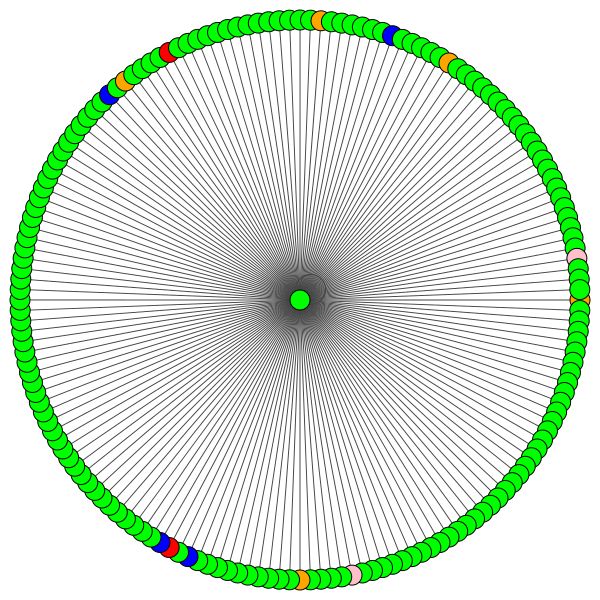
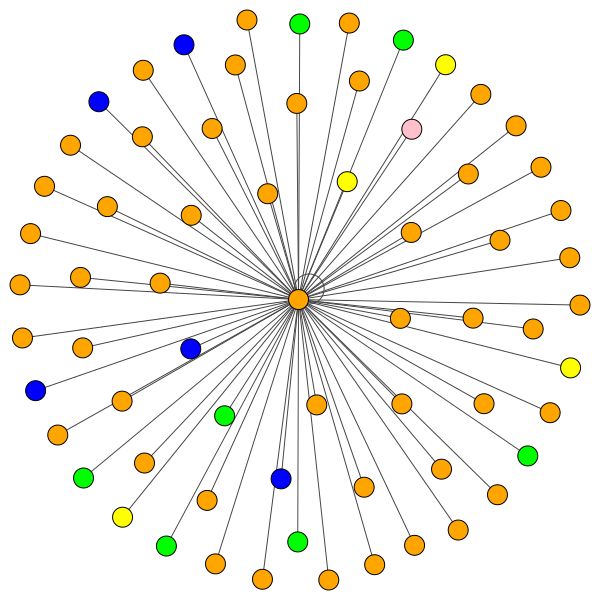
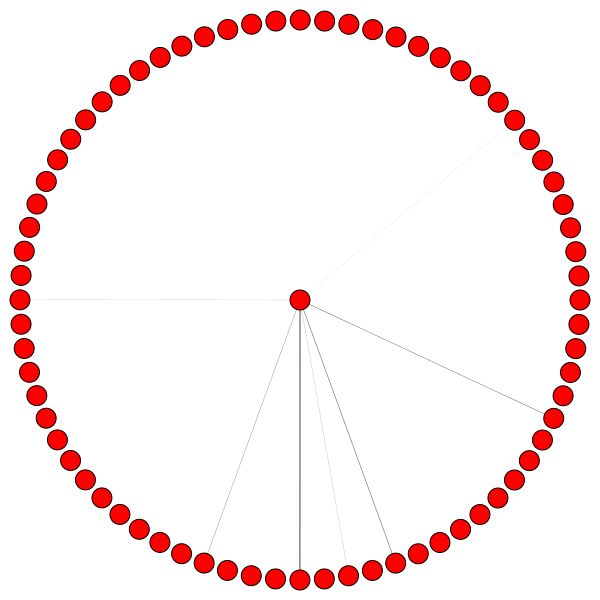
Links können Sie den Knoten mit dem höchsten Grad im gesamten Cora -Datensatz sehen.
Wenn Sie sich wundern, warum diese wie ein Kreis aussehen, dann, weil ich das Layout der layout_reingold_tilford_circular verwendet habe, das besonders gut für baumähnliche Grafiken geeignet ist (da wir einen Knoten und seine Nachbarn visualisieren, ist dieser Untergraphen effektiv ein m-ary -Baum).
Sie können aber auch verschiedene Zeichenalgorithmen wie kamada kawai (rechts) usw. verwenden.
Fühlen Sie sich frei, den Code durchzugehen und mit der Aufmerksamkeit der Aufmerksamkeit aus verschiedenen GAT -Schichten zu spielen, wobei verschiedene Notenviertel oder Aufmerksamkeitsköpfe gezeichnet werden. Sie können auch leicht die Anzahl der Schichten in Ihrem GAT ändern, obwohl flache GNNs in der Regel das Beste in kleinen weltweiten, homophilen Graphendatensätzen ausführen.
Wenn Sie Cora/PPI visualisieren möchten, stellen Sie einfach den playground_fn auf PLAYGROUND.VISUALIZE_DATASET ein und Sie erhalten die Ergebnisse von diesem Readme.
HW -Anforderungen hängen stark von den von Ihnen verwendeten Grafikdaten ab. Wenn Sie nur mit Cora spielen möchten, können Sie gut mit einer 2+ GBS -GPU gehen.
Es dauert (im Cora Citation Network):
Vergleichen Sie dies mit der Hardware, die auch für die kleinsten Transformatoren benötigt wird!
Andererseits ist der PPI Datensatz viel mehr GPU-Hungry. Sie benötigen eine GPU mit 8+ GBs VRAM, oder Sie können die Chargengröße auf 1 reduzieren und das Modell "schlanker" machen und so versuchen, den VRAM -Verbrauch zu verringern.
sparse API von Pytorch nutztWenn Sie eine Vorstellung davon haben, wie Sie GAT mithilfe der spärlichen API von Pytorch implementieren können, können Sie eine PR einreichen. Ich persönlich hatte Schwierigkeiten mit ihrer API, es ist in der Beta, und es ist fraglich, ob es überhaupt möglich ist, eine Implementierung so effizient wie meine Implementierung 3 zu machen.
Zweitens bin ich mir immer noch nicht sicher, warum Gat die gemeldeten Ergebnisse auf PPI erzielt, während es einige offensichtliche numerische Probleme in tieferen Schichten gibt, die sich durch alle Aufmerksamkeitskoeffizienten manifestieren, die gleich 0 sind.
Wenn Sie Schwierigkeiten haben, Gat zu verstehen, habe ich in diesem Video einen detaillierten Überblick über das Papier gemacht:
Ich habe auch ein Walk-Through-Video von diesem Repo gemacht (konzentriert sich auf die potenziellen Schmerzpunkte) und einen Blog zum Einstieg mit Diagramm ML im Allgemeinen! ❤️
Ich habe noch einige Videos, die Ihnen weiter helfen könnten, GNNs zu verstehen:
Ich fand diese Repos nützlich (während ich diese entwickelte):
Wenn Sie diesen Code nützlich finden, geben Sie Folgendes an:
@misc{Gordić2020PyTorchGAT,
author = {Gordić, Aleksa},
title = {pytorch-GAT},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-GAT}},
}


