pytorch GAT
1.0.0
Ce repo contient une implémentation pytorch du papier GAT d'origine (: lien: Veličković et al.).
Il vise à faciliter le début de la lecture et de l'apprentissage de GAT et GNNS en général.
Les réseaux de neurones graphiques sont une famille de réseaux de neurones qui traitent des signaux définis sur les graphiques!
Les graphiques peuvent modéliser de nombreux phénomènes naturels intéressants, vous les verrez donc utilisés partout à partir de:
Et jusqu'à la physique des particules dans le grand collisionneur Hedron (LHC), la détection de fausses nouvelles et la liste s'allonge encore et encore!
Le GAT est un représentant des GNN spatiaux (convolutionnels). Étant donné que CNNS a connu un énorme succès dans le domaine de la vision par ordinateur, les chercheurs ont décidé de le généraliser à des graphiques et nous y sommes donc! ?
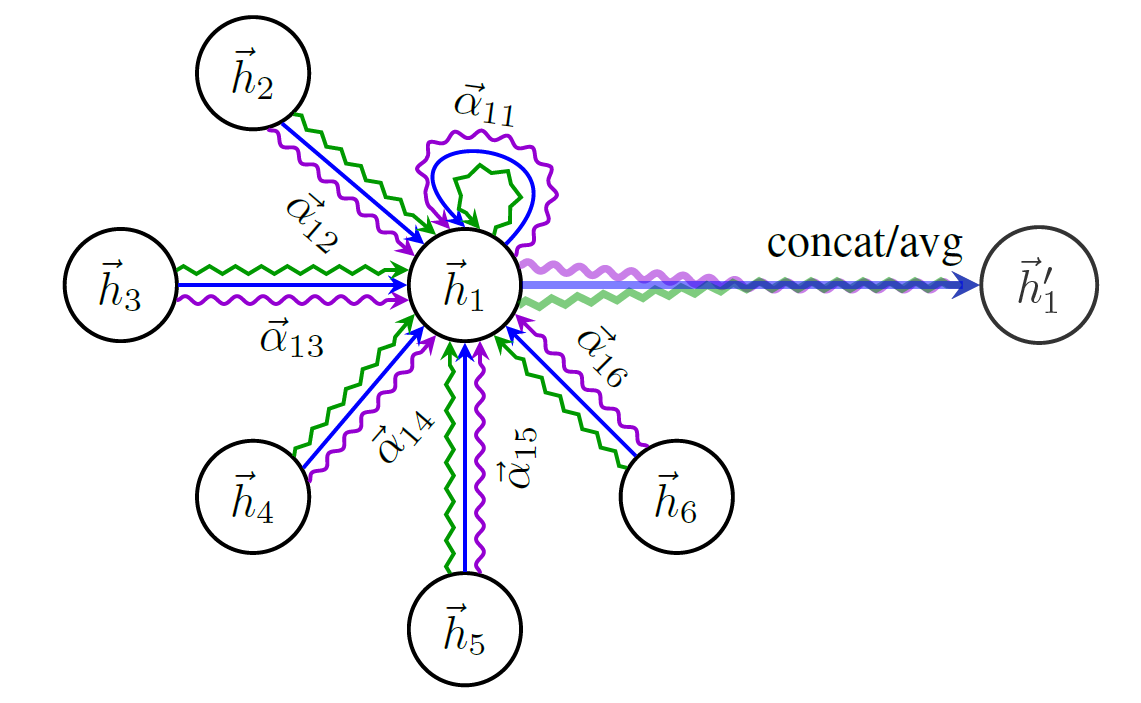
Voici un schéma de la structure de GAT:
Vous ne pouvez pas simplement commencer à parler de GNNS sans mentionner le jeu de données de graphe le plus célèbre - Cora .
Les nœuds de CORA représentent des articles de recherche et les liens sont, vous l'avez deviné, des citations entre ces articles.
J'ai ajouté un utilitaire pour visualiser Cora et effectuer une analyse de réseau de base. Voici à quoi ressemble Cora:

La taille du nœud correspond à son degré (c'est-à-dire le nombre de bords in / sortants). L'épaisseur du bord correspond approximativement à la façon dont "populaire" ou "connecté" ce bord est ( les deux deux deux ans sont le terme ringard, consultez le code.)
Et voici un complot montrant la distribution de diplôme sur Cora:
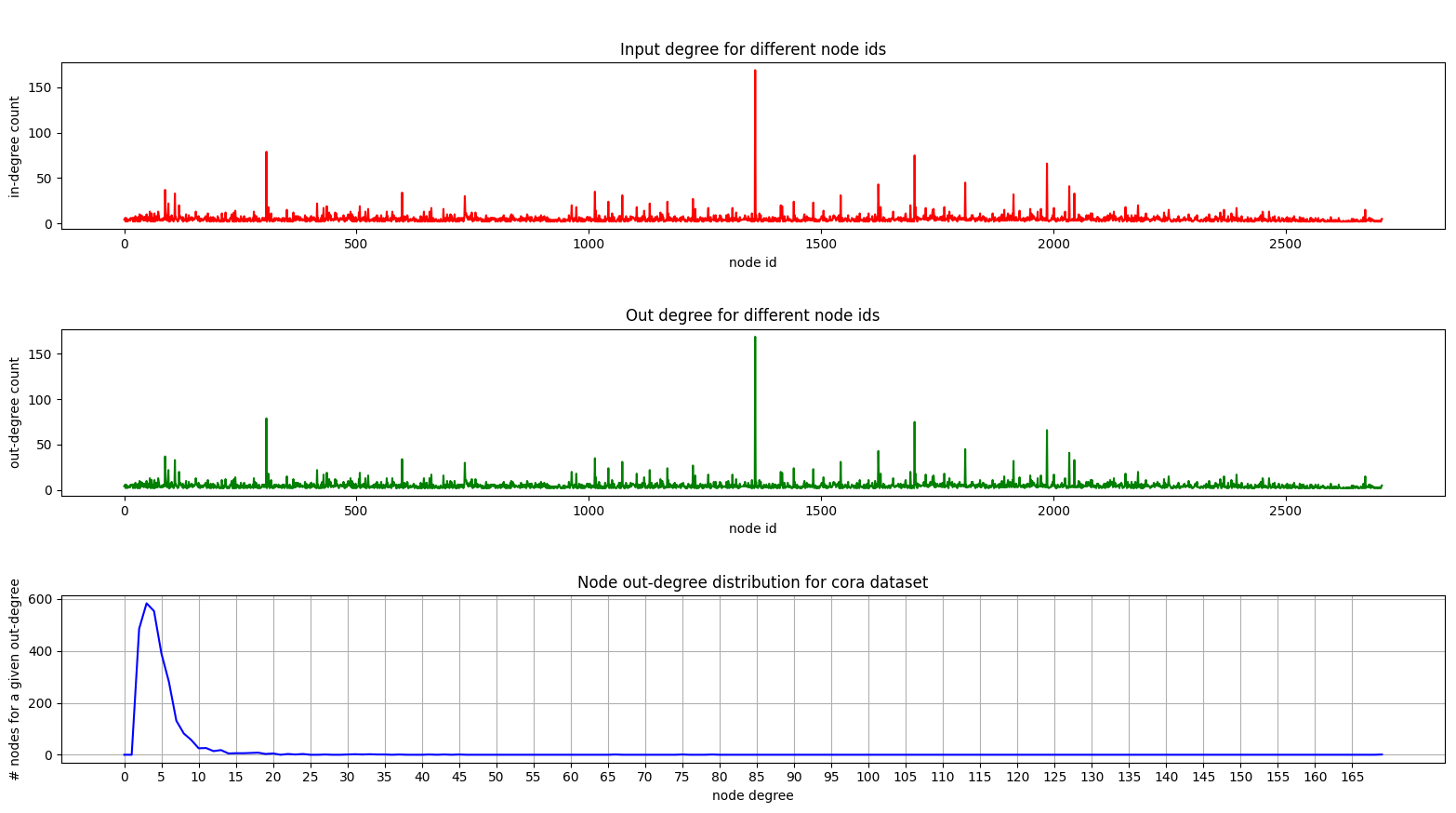
Les parcelles de degré dans et hors degrés sont les mêmes car nous avons affaire à un graphique non dirigé.
Sur le graphique inférieur (distribution de degré), vous pouvez voir un pic intéressant se produire dans la gamme [2, 4] . Cela signifie que la majorité des nœuds ont un petit nombre d'arêtes mais il y a 1 nœud qui a 169 bords! (le grand nœud vert)
Une fois que nous avons un modèle GAT entièrement formé, nous pouvons visualiser l'attention que certains «nœuds» ont appris.
Les nœuds utilisent l'attention pour décider comment agréger leur quartier, suffisamment de discussions, voyons-le:
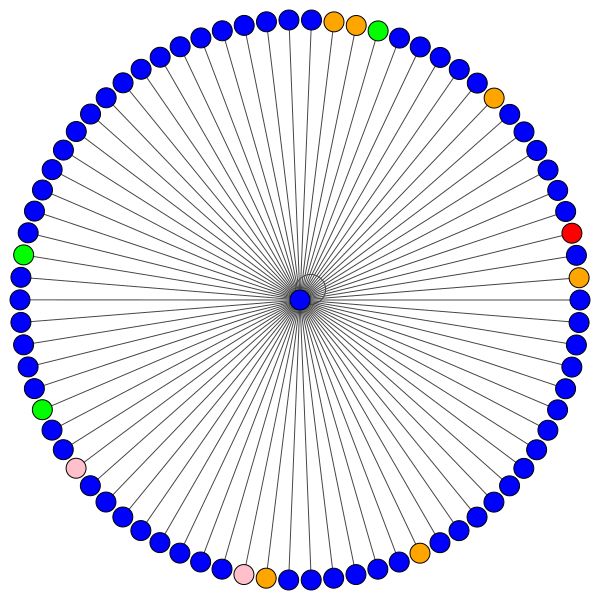
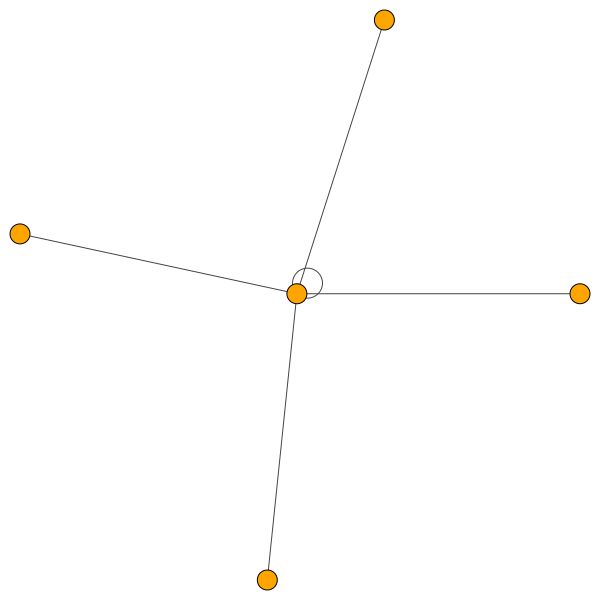
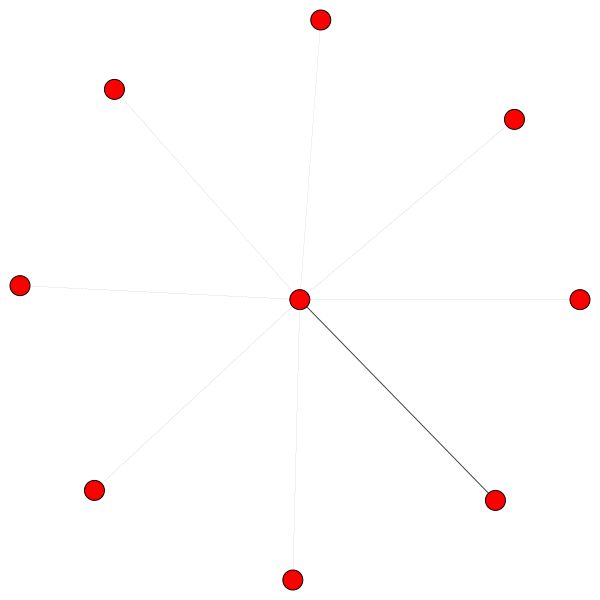
C'est l'un des nœuds de Cora qui a le plus de bords (citations). Les couleurs représentent les nœuds de la même classe. Vous pouvez clairement voir 2 choses à partir de cette intrigue:
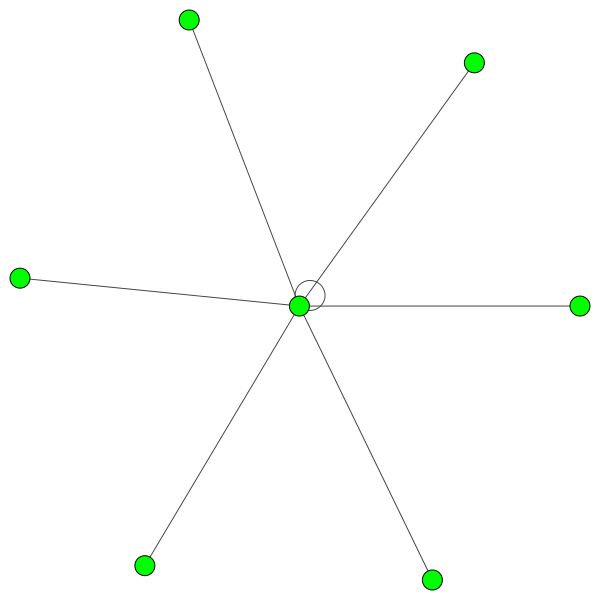
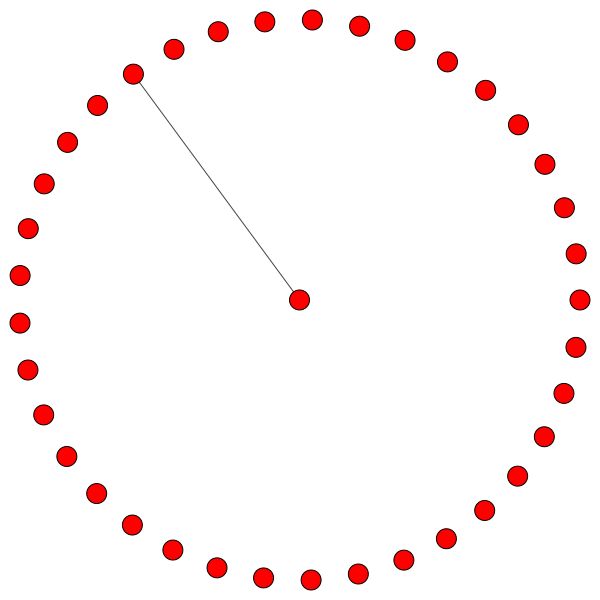
Des règles similaires tiennent pour les petits quartiers. Remarquez également les bords autonomes:
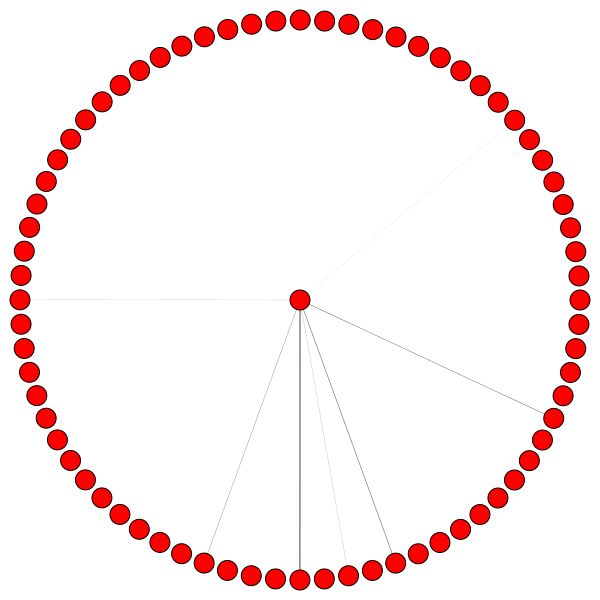
D'un autre côté, PPI apprend des modèles d'attention beaucoup plus intéressants:
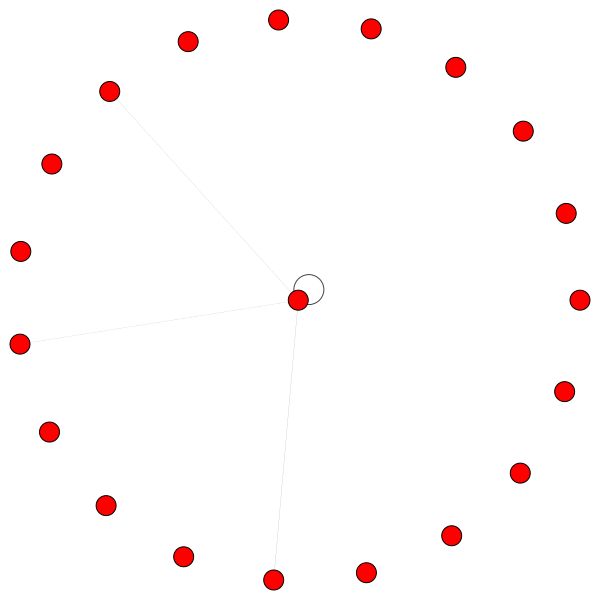
Sur la gauche, nous pouvons voir que 6 voisins reçoivent une quantité d'attention non négligeable et à droite, nous pouvons voir que toute l'attention est concentrée sur un seul voisin .
Enfin 2 modèles plus intéressants - un fort bord de soi à gauche et à droite, nous pouvons voir qu'un seul voisin reçoit une majeure partie d'attention tandis que le reste est également distribué dans le reste du quartier:
Remarque importante: toutes les visualisations PPI ne sont possibles que pour la première couche GAT. Pour une raison quelconque, les coefficients d'attention pour les deuxième et troisième couches sont presque tous 0 (même si j'ai obtenu les résultats publiés).
Une autre façon de comprendre que GAT n'apprend pas les modèles d'attention intéressants sur Cora (c'est-à-dire qu'il apprend l'attention de la constante) est de traiter les poids d'attention du quartier du nœud comme distribution de probabilité, de calcul de l'entropie et d'accumuler les informations dans le quartier de chaque nœud.
Nous aimerions que les distributions d'attention de Gat soient biaisées. Vous pouvez voir dans Orange à quoi ressemble l'histogramme pour les distributions uniformes idéales, et vous pouvez voir en bleu clair les distributions apprises - elles sont exactement les mêmes!
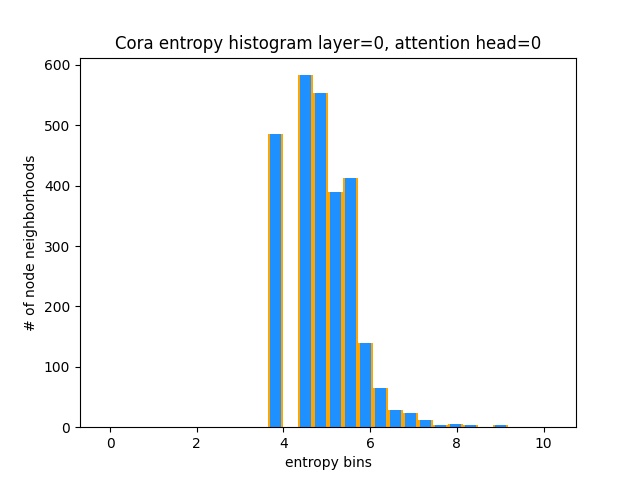
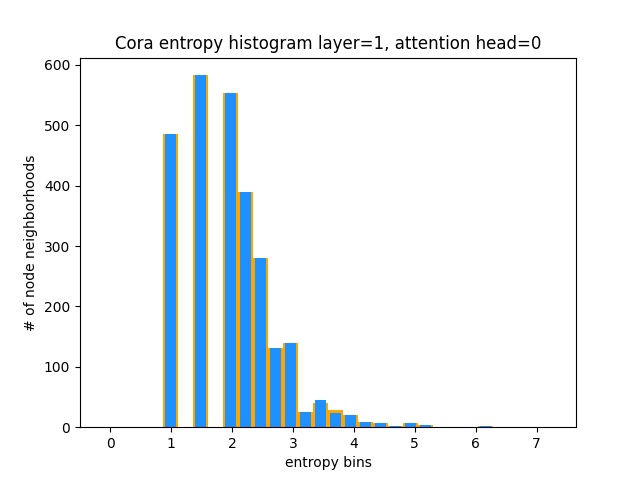
Je n'ai tracé qu'une seule tête d'attention de la première couche (sur 8) car elles sont toutes les mêmes!
D'un autre côté, PPI apprend des modèles d'attention beaucoup plus intéressants:
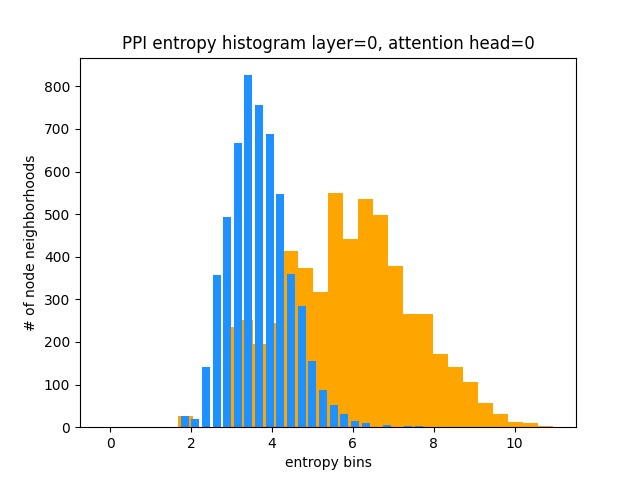
Comme prévu, l'histogramme d'entropie de distribution uniforme se trouve à droite (orange) car les distributions uniformes ont l'entropie la plus élevée.
Ok, nous avons vu l'attention! Qu'y a-t-il d'autre à visualiser? Eh bien, visualisons les intérêts appris à partir de la dernière couche de Gat. La sortie de GAT est un tenseur de forme = (2708, 7) où 2708 est le nombre de nœuds dans CORA et 7 est le nombre de classes. Une fois que nous projetons ces vecteurs à 7 dimmas en 2D, en utilisant T-SNE, nous obtenons ceci:

Nous pouvons voir que les nœuds avec la même étiquette / classe sont à peu près regroupés - avec ces représentations, il est facile de former un classificateur simple sur le dessus qui nous dira à quelle classe appartient au nœud.
Remarque: j'ai également essayé UMAP mais je n'ai pas obtenu de meilleurs résultats + il a beaucoup de dépendances si vous souhaitez utiliser leur intrigue util.
Nous avons donc parlé de ce que sont GNNS et de ce qu'ils peuvent faire pour vous (entre autres).
Faisons courir cette chose! Suivez les étapes suivantes:
git clone https://github.com/gordicaleksa/pytorch-GATcd path_to_repoconda env create à partir du répertoire de projet (cela créera un tout nouvel environnement conda).activate pytorch-gat (pour exécuter des scripts à partir de votre console ou configurer l'interprète dans votre IDE) C'est ça! Il devrait fonctionner à l'exécution du fichier Environment.yml à l'exécution de la boîte qui traite des dépendances.
Le package Pytorch PIP sera livré avec une version de CUDA / CUDNN avec, mais il est fortement recommandé d'installer un CUDA à l'échelle du système, principalement en raison des pilotes GPU. Je recommande également d'utiliser le programme d'installation de MiniConda comme moyen d'obtenir Conda sur votre système. Suivez les points 1 et 2 de cette configuration et utilisez les versions les plus à jour de MiniConda et Cuda / Cudnn pour votre système.
Exécutez simplement jupyter notebook de votre console Anaconda et cela ouvrira une session dans votre navigateur par défaut.
Ouvrez The Annotated GAT.ipynb et vous êtes prêt à jouer!
Remarque: Si vous obtenez DLL load failed while importing win32api: The specified module could not be found
Faites simplement pip uninstall pywin32 , puis pip install pywin32 ou conda install pywin32 devrait le réparer!
Vous avez juste besoin de lier l'environnement Python que vous avez créé dans la section Configuration.
FYI, ma mise en œuvre du GAT obtient les résultats publiés:
82-83% sur les nœuds de test0.973 (et en fait encore plus élevé) Tout ce qui est nécessaire pour former Gat sur Cora est déjà configuré. Pour l'exécuter (à partir de la console), appelez simplement:
python training_script_cora.py
Vous pourriez également potentiellement:
--should_visualize - pour visualiser vos données graphiques--should_test - pour évaluer GAT sur la partie test des données--enable_tensorboard - pour commencer à enregistrer les métriques (précision, perte) Le code est bien commenté afin que vous puissiez (espérons) comprendre comment la formation elle-même fonctionne.
Le script sera:
models/checkpoints/models/binaries/runs/ , il suffit d'exécuter tensorboard --logdir=runs de votre anaconda pour le visualiser Il en va de même pour la formation sur PPI, il suffit d'exécuter python training_script_ppi.py . PPI est beaucoup plus averti du GPU, donc --force_cpu vous n'avez pas de GPU fort avec au moins 8 gb Vous pouvez également essayer de réduire la taille du lot à 1 ou de rendre le modèle plus mince.
Vous pouvez visualiser les mesures pendant la formation, en appelant tensorboard --logdir=runs à partir de votre console et en collant le http://localhost:6006/ url dans votre navigateur:
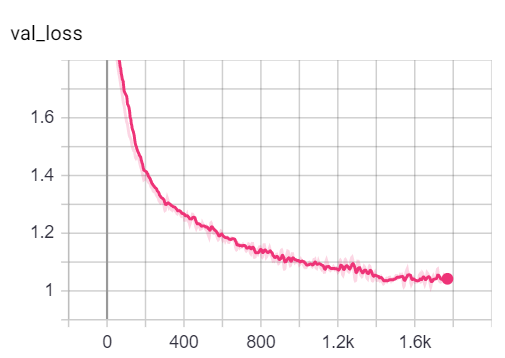
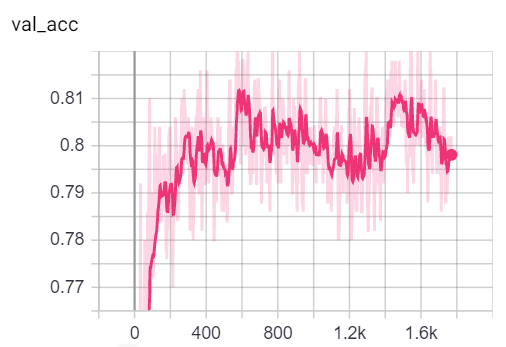
Remarque: la scission de train de Cora semble être beaucoup plus difficile que les divisions de validation et de test en examinant les mesures de perte et de précision.
Cela dit, la majeure partie du plaisir réside dans le script playground.py .
J'ai ajouté 3 implémentations GAT - certains sont conceptuellement plus faciles à comprendre que certains sont plus efficaces. La plus intéressante et la plus difficile à comprendre est la mise en œuvre 3. La mise en œuvre 1 et l'implémentation 2 diffèrent dans des détails subtils mais font essentiellement la même chose.
Conseils sur la façon d'approcher le code:
Si vous souhaitez profiler les 3 implémentations, il suffit de définir la variable playground_fn sur PLAYGROUND.PROFILE_GAT dans playground.py .
Vous vous souciez de 2 paramètres:
store_cache - Définir sur True si vous souhaitez enregistrer les résultats du profilage de mémoire / temps après l'avoir exécutéskip_if_profiling_info_cached - réglé sur True si vous souhaitez tirer les informations de profilage du cache Les résultats seront stockés dans data/ en memory.dict et timing.dict DICTIONNAIRES (PIRCHLE).
Remarque: L'implémentation # 3 est de loin la plus optimisée - vous pouvez voir les détails du code.
J'ai également ajouté profile_sparse_matrix_formats si vous souhaitez familiariser avec différents formats de matrice clairsemés comme COO , CSR , CSC , LIL , etc.
Si vous souhaitez visualiser les incorporations T-SNE, l'attention ou les intégres définissent la variable playground_fn sur PLAYGROUND.VISUALIZE_GAT et définissez la visualization_type sur:
VisualizationType.ATTENTION - Si vous souhaitez visualiser l'attention dans les quartiers de nœudVisualizationType.EMBEDDING - Si vous souhaitez visualiser les intégres (via T-SNE)VisualizationType.ENTROPY - Si vous souhaitez visualiser les histogrammes d'entropie Et vous obtiendrez des visualisations folles comme celles-ci (option VisualizationType.ATTENTION ):
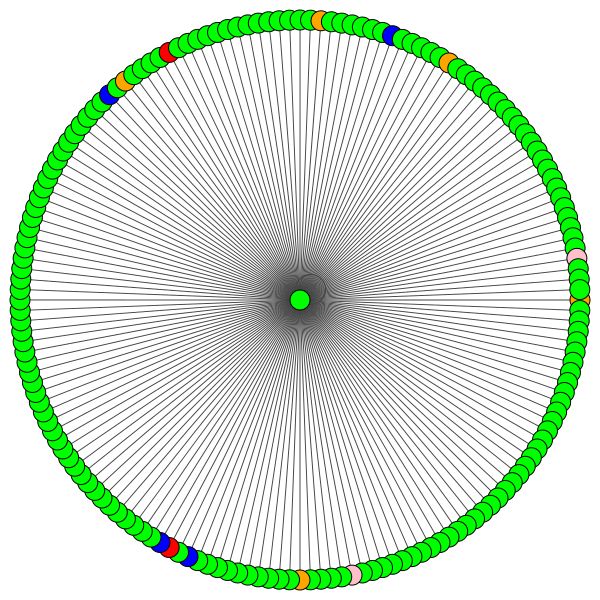
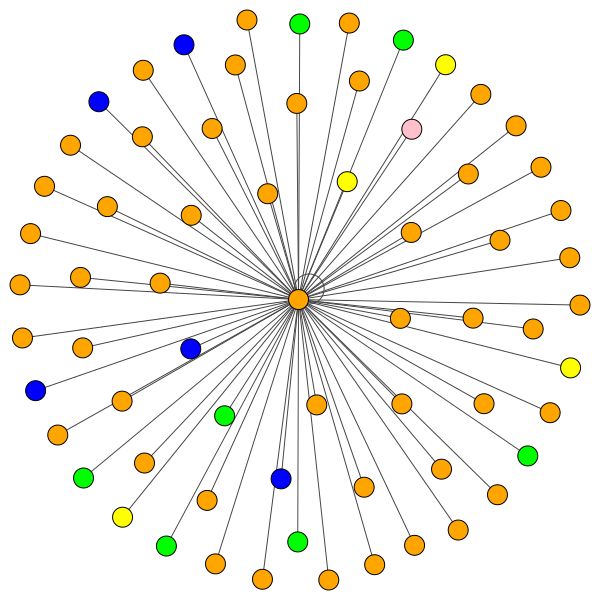
À gauche, vous pouvez voir le nœud avec le plus haut degré de l'ensemble de données CORA.
Si vous vous demandez pourquoi ceux-ci ressemblent à un cercle, c'est parce que j'ai utilisé la mise en page layout_reingold_tilford_circular qui est particulièrement bien adaptée aux graphiques comme des arbres (puisque nous visualisons un nœud et ses voisins, ce sous-graphique est effectivement un arbre m-ary ).
Mais vous pouvez également utiliser différents algorithmes de dessin comme kamada kawai (à droite), etc.
N'hésitez pas à passer par le code et à jouer avec l'attention de différentes couches GAT, à tracer différents quartiers de nœuds ou des têtes d'attention. Vous pouvez également modifier facilement le nombre de couches dans votre GAT, bien que les GNN peu profonds aient tendance à effectuer le meilleur des ensembles de données de graphiques homophiles en petit monde.
Si vous souhaitez visualiser CORA / PPI, définissez simplement le playground_fn sur PLAYGROUND.VISUALIZE_DATASET et vous obtiendrez les résultats de cette lecture.
Les exigences de HW dépendent fortement des données du graphique que vous utilisez. Si vous voulez juste jouer avec Cora , vous êtes prêt à aller avec un GPU GBS 2+ .
Il faut (sur Cora Citation Network):
Comparez cela au matériel nécessaire même pour le plus petit des transformateurs!
D'un autre côté, l'ensemble de données PPI est beaucoup plus averti par le GPU. Vous aurez besoin d'un GPU avec plus de 8 Gbs de VRAM, ou vous pouvez réduire la taille du lot à 1 et rendre le modèle "plus mince" et ainsi essayer de réduire la consommation de VRAM.
sparse API de PytorchSi vous avez une idée de la façon de mettre en œuvre GAT à l'aide de l'API clairsemée de Pytorch, n'hésitez pas à soumettre un PR. Personnellement, j'ai eu des difficultés avec leur API, c'est en version bêta, et il est discutable de savoir s'il est possible de rendre une implémentation aussi efficace que mon implémentation 3 en l'utilisant.
Deuxièmement, je ne sais toujours pas pourquoi le GAT obtient des résultats rapportés sur PPI alors qu'il y a des problèmes numériques évidents dans les couches plus profondes, telles que manifestes par tous les coefficients d'attention égaux à 0.
Si vous avez des difficultés à comprendre Gat, j'ai fait un aperçu approfondi du document dans cette vidéo:
J'ai également réalisé une vidéo de cette récompense (en me concentrant sur les points de douleur potentiels) et un blog pour commencer avec le graphique ML en général! ❤️
J'ai d'autres vidéos qui pourraient vous aider à comprendre GNNS:
J'ai trouvé ces reposs utiles (tout en développant celui-ci):
Si vous trouvez ce code utile, veuillez citer ce qui suit:
@misc{Gordić2020PyTorchGAT,
author = {Gordić, Aleksa},
title = {pytorch-GAT},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-GAT}},
}


