pytorch GAT
1.0.0
Este repo contém uma implementação de Pytorch do papel GAT original (: Link: Veličković et al.).
O objetivo é facilitar o início de tocar e aprender sobre GAT e GNNs em geral.
Redes neurais gráficas são uma família de redes neurais que estão lidando com sinais definidos em gráficos!
Os gráficos podem modelar muitos fenômenos naturais interessantes, então você os verá usados em qualquer lugar de:
E todo o caminho para a física de partículas em geral Hedron Collider (LHC), a detecção de notícias falsas e a lista continua!
O GAT é um representante dos GNNs espaciais (convolucionais). Como os CNNs tiveram um tremendo sucesso no campo da visão computacional, os pesquisadores decidiram generalizá -lo para gráficos e aqui estamos nós! ?
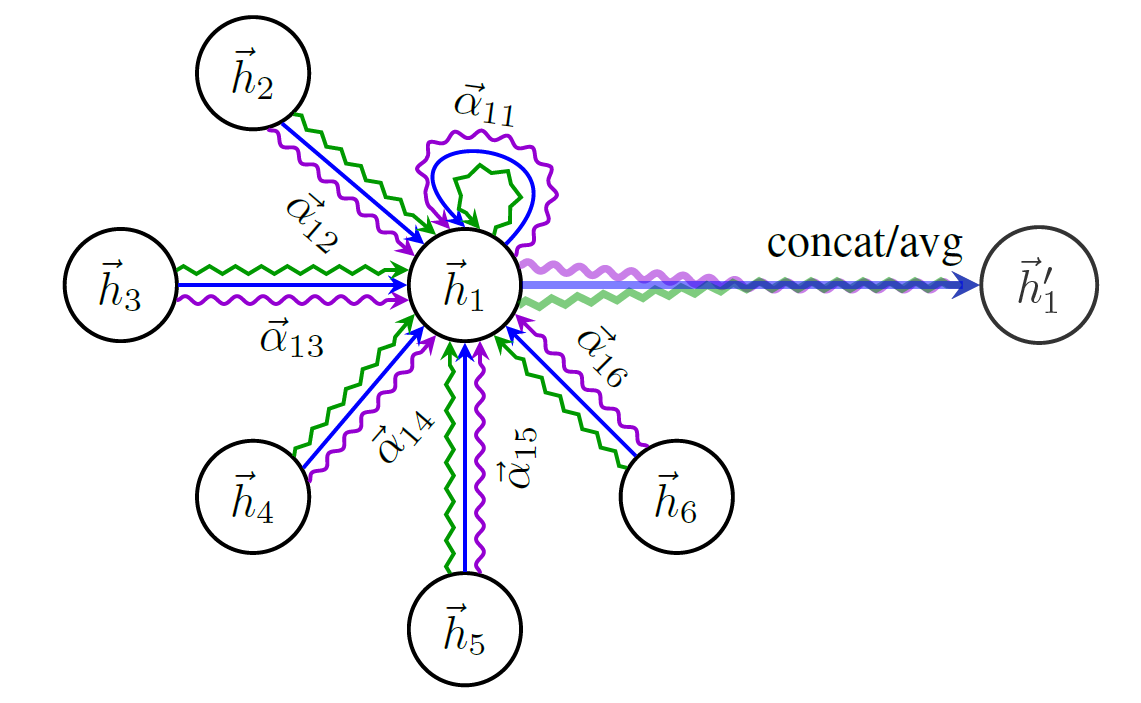
Aqui está um esquema da estrutura de Gat:
Você não pode simplesmente começar a falar sobre GNNs sem mencionar o conjunto de dados de gráficos mais famoso - Cora .
Os nós em Cora representam trabalhos de pesquisa e os links são, você adivinhou, citações entre esses trabalhos.
Eu adicionei um utilitário para visualizar Cora e fazer análise básica de rede. Aqui está como Cora se parece:

O tamanho do nó corresponde ao seu grau (ou seja, o número de arestas dentro/saída). A espessura da borda corresponde aproximadamente ao quão "popular" ou "conectado" essa borda é ( a borda intermediária é o termo nerd, confira o código.)
E aqui está um enredo mostrando a distribuição de graduação em Cora:
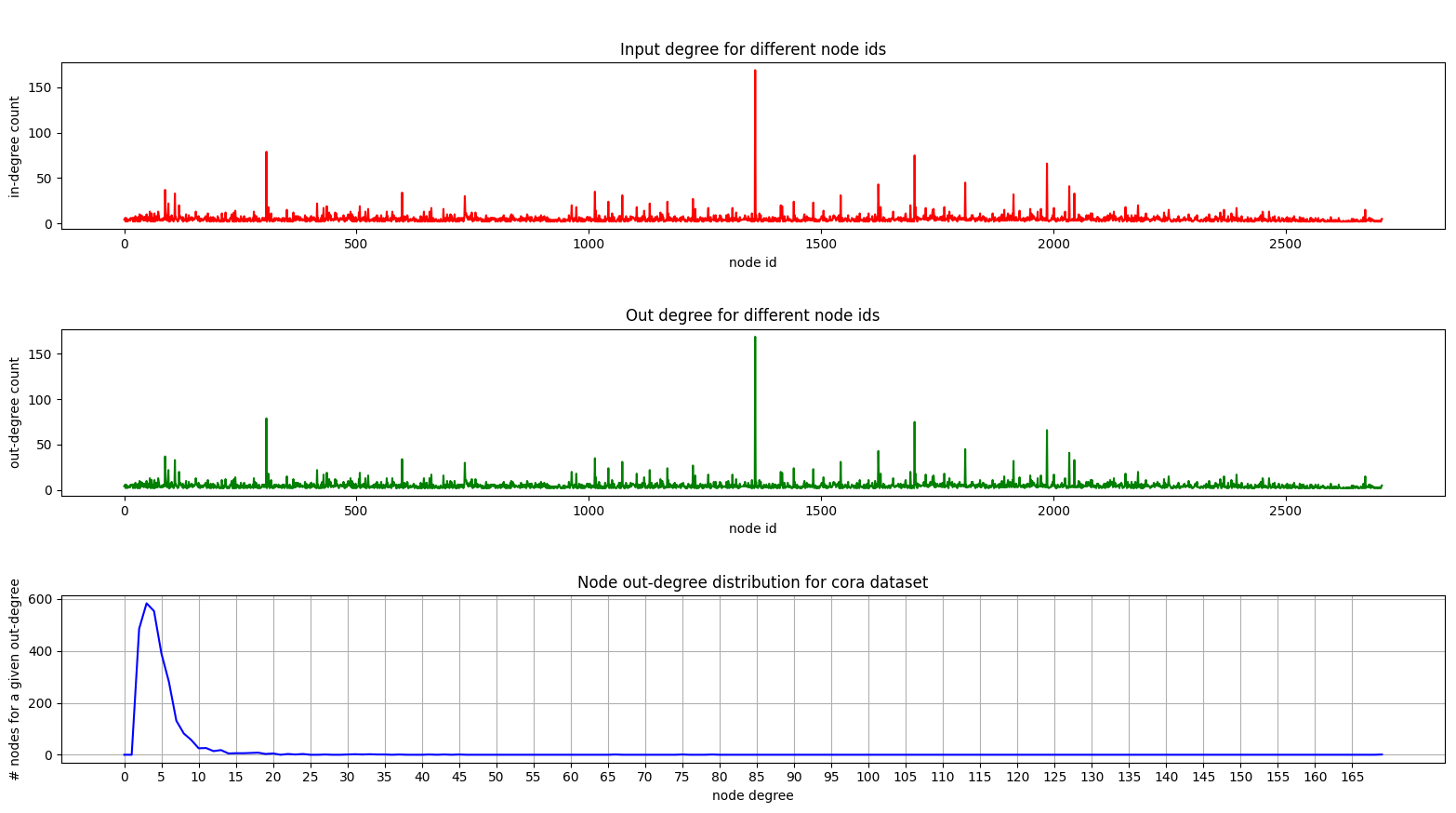
As parcelas dentro e fora do grau são as mesmas, pois estamos lidando com um gráfico não direcionado.
No gráfico inferior (distribuição de graus), você pode ver um pico interessante acontecendo na faixa [2, 4] . Isso significa que a maioria dos nós tem um pequeno número de arestas, mas há um nó que tem 169 arestas! (o grande nó verde)
Depois de termos um modelo GAT totalmente treinado, podemos visualizar a atenção que certos "nós" aprenderam.
Os nós usam atenção para decidir como agregar o bairro, conversa suficiente, vamos ver:
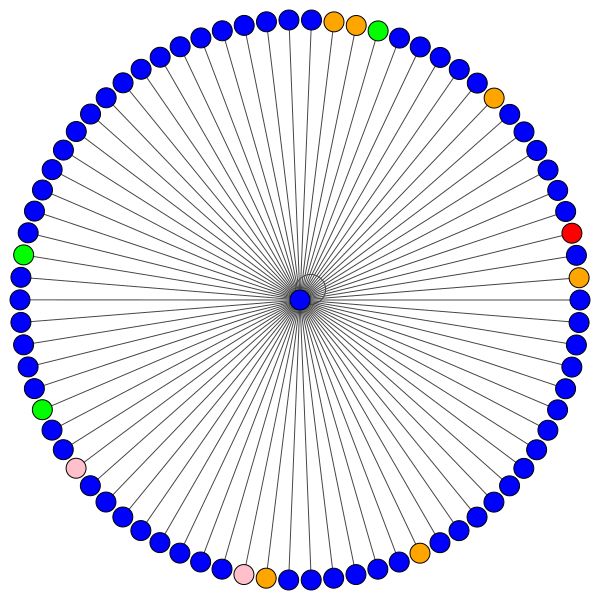
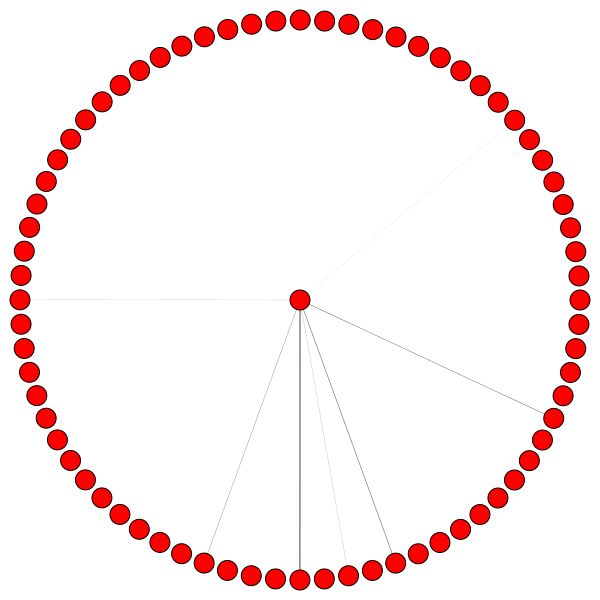
Este é um dos nós de Cora que tem mais bordas (citações). As cores representam os nós da mesma classe. Você pode ver claramente 2 coisas desta trama:
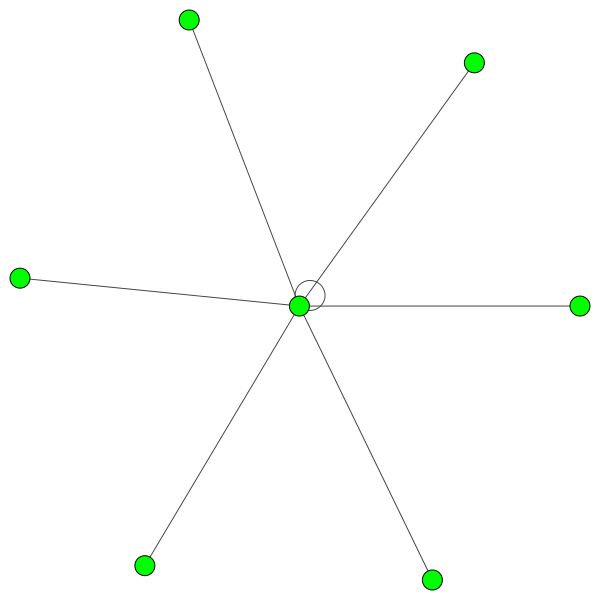
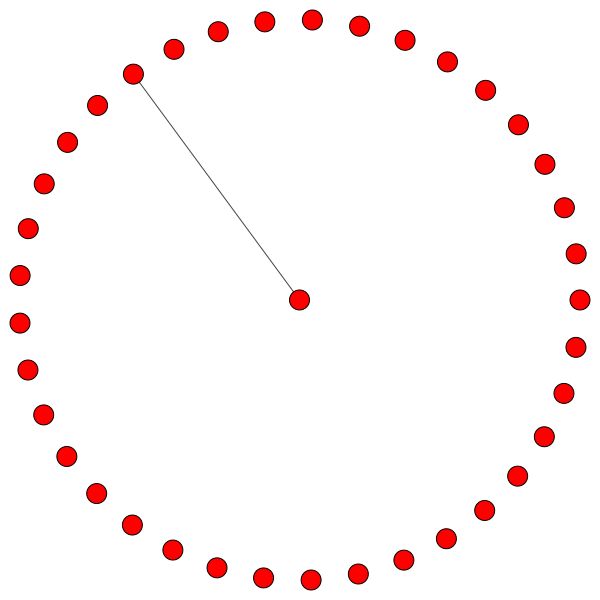
Regras semelhantes se mantêm para bairros menores. Observe também as bordas de si:
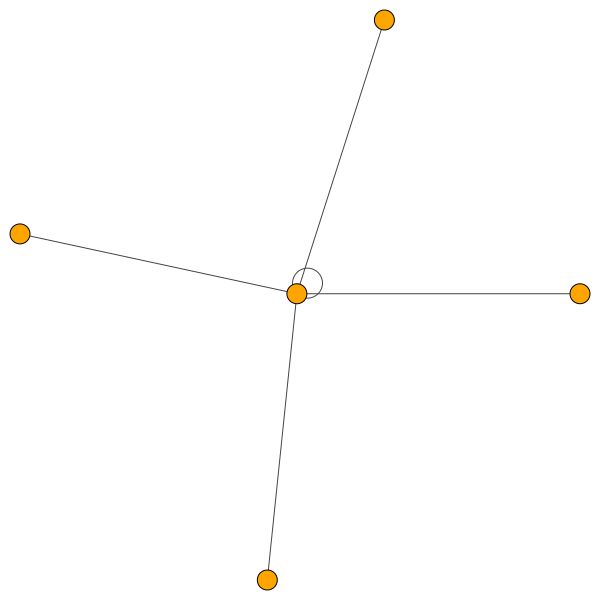
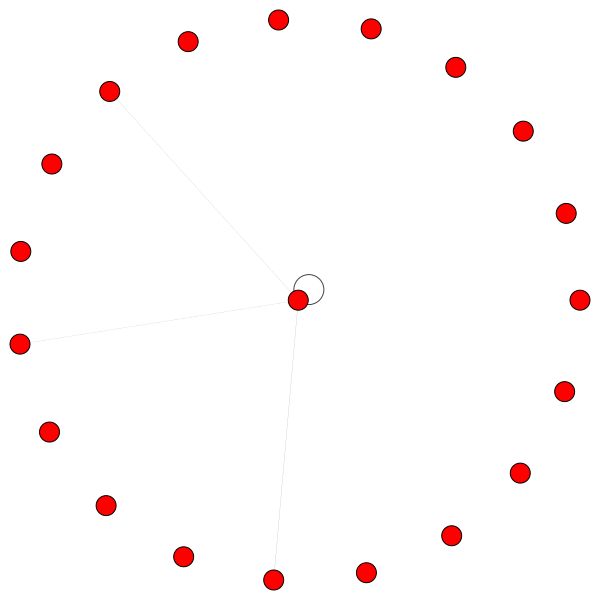
Por outro lado, o PPI está aprendendo padrões de atenção muito mais interessantes:
À esquerda, podemos ver que 6 vizinhos estão recebendo uma quantidade de atenção não negligenciada e, à direita, podemos ver que toda a atenção está focada em um único vizinho .
Finalmente, 2 padrões mais interessantes - uma forte vantagem própria à esquerda e à direita, podemos ver que um único vizinho está recebendo uma maior parte da atenção, enquanto o restante é igualmente distribuído pelo resto do bairro:
NOTA IMPORTANTE: Todas as visualizações PPI são possíveis apenas para a primeira camada GAT. Por alguma razão, os coeficientes de atenção para a segunda e terceira camadas são quase todos 0s (mesmo que eu tenha alcançado os resultados publicados).
Outra maneira de entender que o GAT não está aprendendo padrões de atenção interessantes em Cora (ou seja, que está aprendendo constante atenção) é tratar os pesos de atenção do bairro do nó como uma distribuição de probabilidade, calculando a entropia e acumulando as informações em todo o bairro de todos os nó.
Adoraríamos que as distribuições de atenção de Gat fossem distorcidas. Você pode ver em Orange como o histograma se parece com distribuições uniformes ideais, e pode ver em azul claro as distribuições aprendidas - elas são exatamente as mesmas!
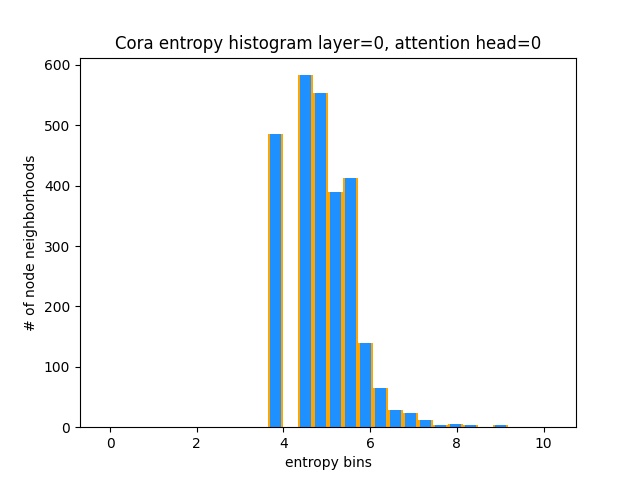
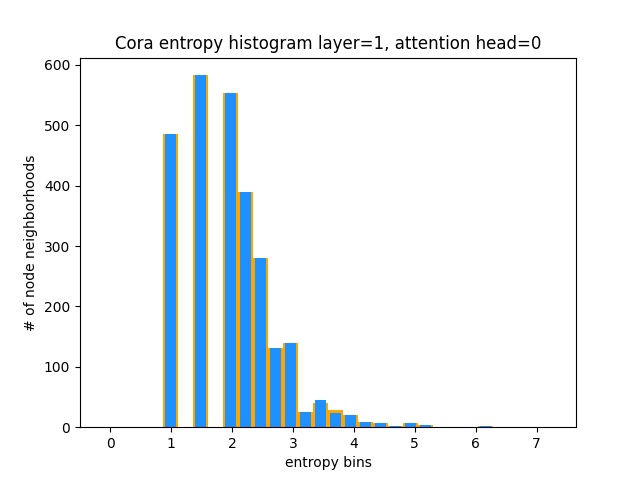
Plotei apenas uma única atenção da primeira camada (de 8) porque eles são todos iguais!
Por outro lado, o PPI está aprendendo padrões de atenção muito mais interessantes:
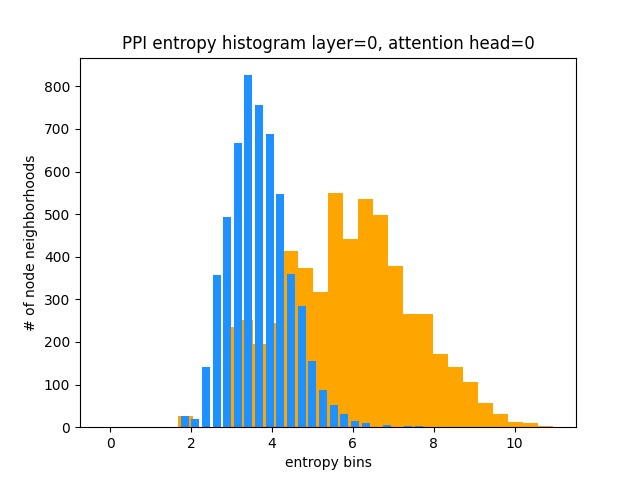
Como esperado, o histograma de entropia de distribuição uniforme está à direita (laranja), pois as distribuições uniformes têm a entropia mais alta.
OK, vimos atenção! O que mais há para visualizar? Bem, vamos visualizar as incorporações instruídas da última camada de Gat. A saída de GAT é um tensor de forma = (2708, 7), onde 2708 é o número de nós em Cora e 7 é o número de classes. Depois de projetarmos esses vetores 7-DIM em 2D, usando T-SNE, conseguimos isso:

Podemos ver que os nós com o mesmo rótulo/classe estão agrupados aproximadamente - com essas representações, é fácil treinar um classificador simples na parte superior que nos dirá a qual classe a qual o nó pertence.
Nota: eu tentei umap também, mas não obtive resultados mais agradáveis + ele tem muitas dependências se você quiser usar o util da plotagem.
Por isso, conversamos sobre o que são GNNs e o que eles podem fazer por você (entre outras coisas).
Vamos fazer isso funcionando! Siga os próximos passos:
git clone https://github.com/gordicaleksa/pytorch-GATcd path_to_repoconda env create From Project Directory (isso criará um novo ambiente do CONDA).activate pytorch-gat (para executar scripts do seu console ou configurar o intérprete em seu IDE) É isso! Ele deve funcionar fora do arquivo de execução do ambiente.YML, que lida com dependências.
O pacote Pytorch Pip será incluído com alguma versão do CUDA/CUDNN com ele, mas é altamente recomendável que você instale um CUDA em todo o sistema, com antecedência, principalmente por causa dos drivers de GPU. Eu também recomendo o uso do Miniconda Installer como uma maneira de obter o CONDA no seu sistema. Siga os pontos 1 e 2 desta configuração e use as versões mais atualizadas do Miniconda e Cuda/Cudnn para o seu sistema.
Basta executar jupyter notebook seu console Anaconda e ele abrirá uma sessão no seu navegador padrão.
Abra The Annotated GAT.ipynb e você estará pronto para jogar!
NOTA: Se você receber DLL load failed while importing win32api: The specified module could not be found
Basta pip uninstall pywin32 e, em seguida, pip install pywin32 ou conda install pywin32 deve corrigi -lo!
Você só precisa vincular o ambiente Python que você criou na seção de configuração.
Para sua informação, minha implementação do GAT alcança os resultados publicados:
82-83% nos nós de teste0.973 micro-F1 (e na verdade até mais alto) Tudo o necessário para treinar Gat em Cora já está configurado. Para executá -lo (do console), basta ligar:
python training_script_cora.py
Você também pode potencialmente:
--should_visualize -para visualizar seus dados do gráfico--should_test -para avaliar o GAT na parte de teste dos dados--enable_tensorboard -para começar a salvar métricas (precisão, perda) O código é bem comentado para que você possa (espero) entender como o treinamento em si funciona.
O script irá:
models/checkpoints/models/binaries/runs/ , basta executar tensorboard --logdir=runs da sua anaconda para visualizá -lo O mesmo vale para o treinamento no PPI, basta executar python training_script_ppi.py . O PPI é muito mais faminto por GPU, por isso, se você não tiver uma GPU forte com pelo menos 8 GBs, precisará adicionar o sinalizador --force_cpu para treinar GAT na CPU. Como alternativa, você pode tentar reduzir o tamanho do lote para 1 ou tornar o modelo mais esbelto.
Você pode visualizar as métricas durante o treinamento, ligando para tensorboard --logdir=runs do seu console e colando o http://localhost:6006/ url no seu navegador:
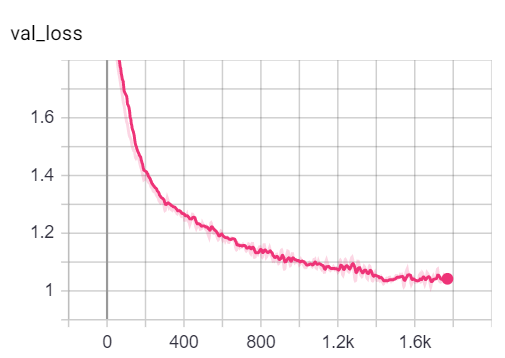
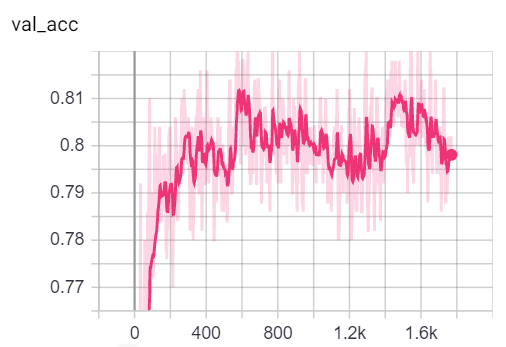
NOTA: A divisão do trem de Cora parece ser muito mais difícil do que as divisões de validação e teste, analisando as métricas de perda e precisão.
Dito isto, a maior parte da diversão está realmente no script playground.py .
Eu adicionei 3 implementações GAT - algumas são conceitualmente mais fáceis de entender que alguns são mais eficientes. O mais interessante e mais difícil de entender é a implementação 3. A implementação 1 e a implementação 2 diferem em detalhes sutis, mas basicamente fazem a mesma coisa.
Conselhos sobre como abordar o código:
Se você deseja perfilar as três implementações, basta definir a variável playground_fn como PLAYGROUND.PROFILE_GAT no playground.py .
Existem 2 parâmetros com os quais você pode se importar:
store_cache - defina como True se você deseja salvar os resultados de criação de memória/tempo depois de executá -loskip_if_profiling_info_cached - defina como True se você quiser puxar as informações de criação de criação de cache Os resultados serão armazenados em data/ em memory.dict e timing.dict dicionários (picles).
Nota: A implementação nº 3 é de longe a mais otimizada - você pode ver os detalhes do código.
Eu também adicionei profile_sparse_matrix_formats se você deseja obter alguma familiaridade com diferentes formatos escassos de matriz, como COO , CSR , CSC , LIL , etc.
Se você deseja visualizar incorporações T-SNE, atenção ou incorporação define a variável playground_fn como PLAYGROUND.VISUALIZE_GAT e defina o visualization_type como:
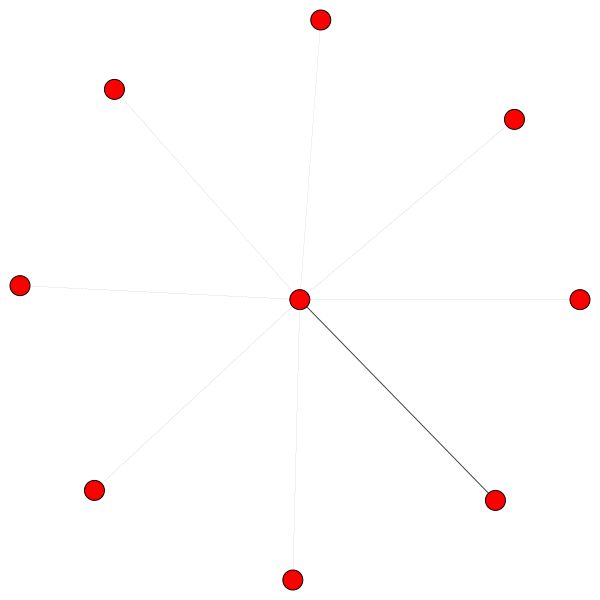
VisualizationType.ATTENTION - Se você deseja visualizar a atenção nos bairros dos nóVisualizationType.EMBEDDING - Se você deseja visualizar as incorporações (via T -Sne)VisualizationType.ENTROPY - Se você deseja visualizar os histogramas de entropia E você terá visualizações loucas como essas (opção VisualizationType.ATTENTION ):
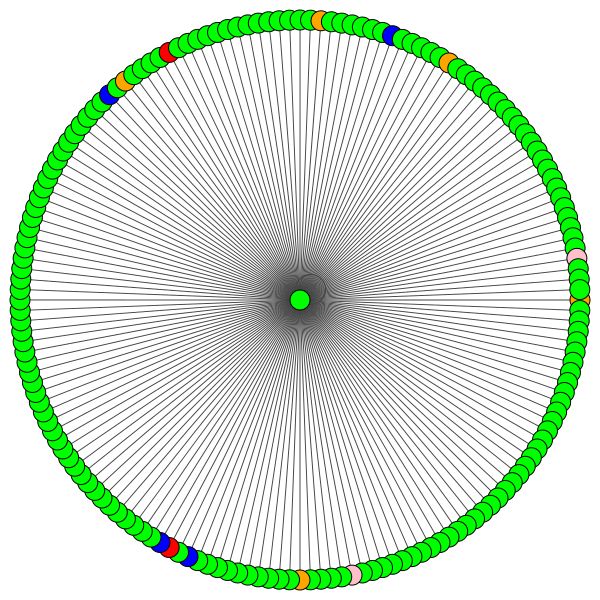
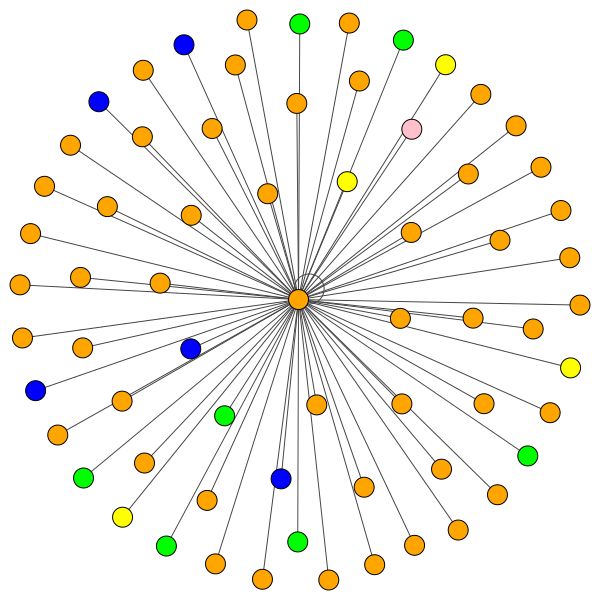
À esquerda, você pode ver o nó com o mais alto grau em todo o conjunto de dados CORA.
Se você está se perguntando por que eles parecem um círculo, é porque eu usei o layout layout_reingold_tilford_circular que é particularmente adequado para gráficos de árvores (já que estamos visualizando um nó e seus vizinhos, esse subgrafista é efetivamente uma árvore m-ary ).
Mas você também pode usar algoritmos de desenho diferentes como kamada kawai (à direita), etc.
Sinta -se à vontade para passar pelo código e brincar com a planejamento da atenção de diferentes camadas de GAT, traçando diferentes bairros de nó ou cabeças de atenção. Você também pode alterar facilmente o número de camadas no seu GAT, embora os GNNs rasos tendam a executar o melhor em conjuntos de dados de gráficos homofílicos do mundo pequeno.
Se você deseja visualizar Cora/PPI, basta definir o playground_fn como PLAYGROUND.VISUALIZE_DATASET e você obterá os resultados deste ReadMe.
Os requisitos de HW são altamente dependentes dos dados do gráfico que você usará. Se você quer apenas brincar com Cora , está pronto para ir com uma GPU de 2+ GBs .
É preciso (na rede de citação de Cora):
Compare isso com o hardware necessário, mesmo para o menor dos transformadores!
Por outro lado, o conjunto de dados PPI é muito mais faminto por GPU. Você precisará de uma GPU com mais de 8 GBs de VRAM, ou poderá reduzir o tamanho do lote para 1 e tornar o modelo "mais magro" e, assim, tentar reduzir o consumo de VRAM.
sparse API de PytorchSe você tiver uma idéia de como implementar o GAT usando a API esparsa de Pytorch, sinta -se à vontade para enviar um PR. Pessoalmente, tive dificuldades com a API deles, está na versão beta e é questionável se é possível tornar uma implementação tão eficiente quanto minha implementação 3 usando -a.
Em segundo lugar, ainda não sei por que o GAT está alcançando resultados relatados no PPI, enquanto existem alguns problemas numéricos óbvios em camadas mais profundas, manifestadas por todos os coeficientes de atenção iguais a 0.
Se você está tendo dificuldades para entender o GAT, fiz uma visão geral aprofundada do artigo neste vídeo:
Também fiz um vídeo de passagem deste repositório (com foco nos potenciais pontos problemáticos) e um blog para começar com o Gráfico ML em geral! ❤️
Tenho mais alguns vídeos que podem ajudá -lo a entender os GNNs:
Achei esses repositórios úteis (enquanto desenvolveu este):
Se você achar esse código útil, cite o seguinte:
@misc{Gordić2020PyTorchGAT,
author = {Gordić, Aleksa},
title = {pytorch-GAT},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-GAT}},
}


