Customer Purchase Predection
1.0.0
$ git clone https://github.com/krvaibhaw/Customer-Purchase-Predection.git
$ cd Customer-Purchase-Predection
$ pip install requirements.txt
$ python model.py <data folder path>/<file.csv>
Пример :
$ python model.py data/activity_data.csv
Мы начали оценку, загрузив набор данных активности клиента для веб -сайта, используя аргумент командной строки. Для исследования мы использовали набор данных онлайн -активности клиентов для веб -сайта, включающие такие параметры, как тип трафика, регион, продолжительность, связанная с продуктом, связанный с продуктом, месяц и т. Д.
if len ( sys . argv ) != 2 :
sys . exit ( "Usage: python shopping.py data" )
evidence , labels = load_data ( sys . argv [ 1 ])Необходимо преобразовать категориальные функции в числовые, поскольку все алгоритмы машинного обучения интерпретируют только числовые значения. Шаг.
month_index = dict ( Jan = 0 , Feb = 1 , Mar = 2 , Apr = 3 , May = 4 , June = 5 ,
Jul = 6 , Aug = 7 , Sep = 8 , Oct = 9 , Nov = 10 , Dec = 11 )
( month_index [ row [ "Month" ]],
1 if row [ "VisitorType" ] == "Returning_Visitor" else 0 ,
1 if row [ "Weekend" ] == "TRUE" else 0 )
labels . append ( 1 if row [ "Revenue" ] == "TRUE" else 0 )Процедура включает в себя принятие набора данных и разделение его на два подмножества. Первое подмножество используется для соответствия модели и называется обучающим набором данных. Второе подмножество не используется для обучения модели; Вместо этого входной элемент набора данных предоставляется модели, а затем прогнозируются и сравниваются с ожидаемыми значениями. Этот второй набор данных называется тестовым набором данных. И затем мы готовим данные обучения и тестирования для модели, используя функцию train_test_split () из модуля Sklearn.
from sklearn . model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split (
evidence , labels , test_size = TEST_SIZE
)Затем мы создаем модель AUR K-Nearest соседей (KNN), используя модель Sklearn, которую мы установили в разделе «Установка требований». Алгоритм KNN предполагает, что подобные вещи существуют в непосредственной близости. Другими словами, похожие вещи рядом друг с другом.
def train_model ( evidence , labels ):
model = KNeighborsClassifier ( n_neighbors = 1 )
model . fit ( evidence , labels )
return modelДанные обучения будут использоваться для обучения модели KNN (K-Nearest соседей). И тестовые данные будут использоваться для проверки модели. Это будет предсказать этикетки для данных невидимых векторов.
model = train_model ( X_train , y_train )
predictions = model . predict ( X_test )Наконец, модель затем оценивается. Оценка модели направлена на оценку точности обобщения модели на будущих (невидимых/вне выборки) данных.
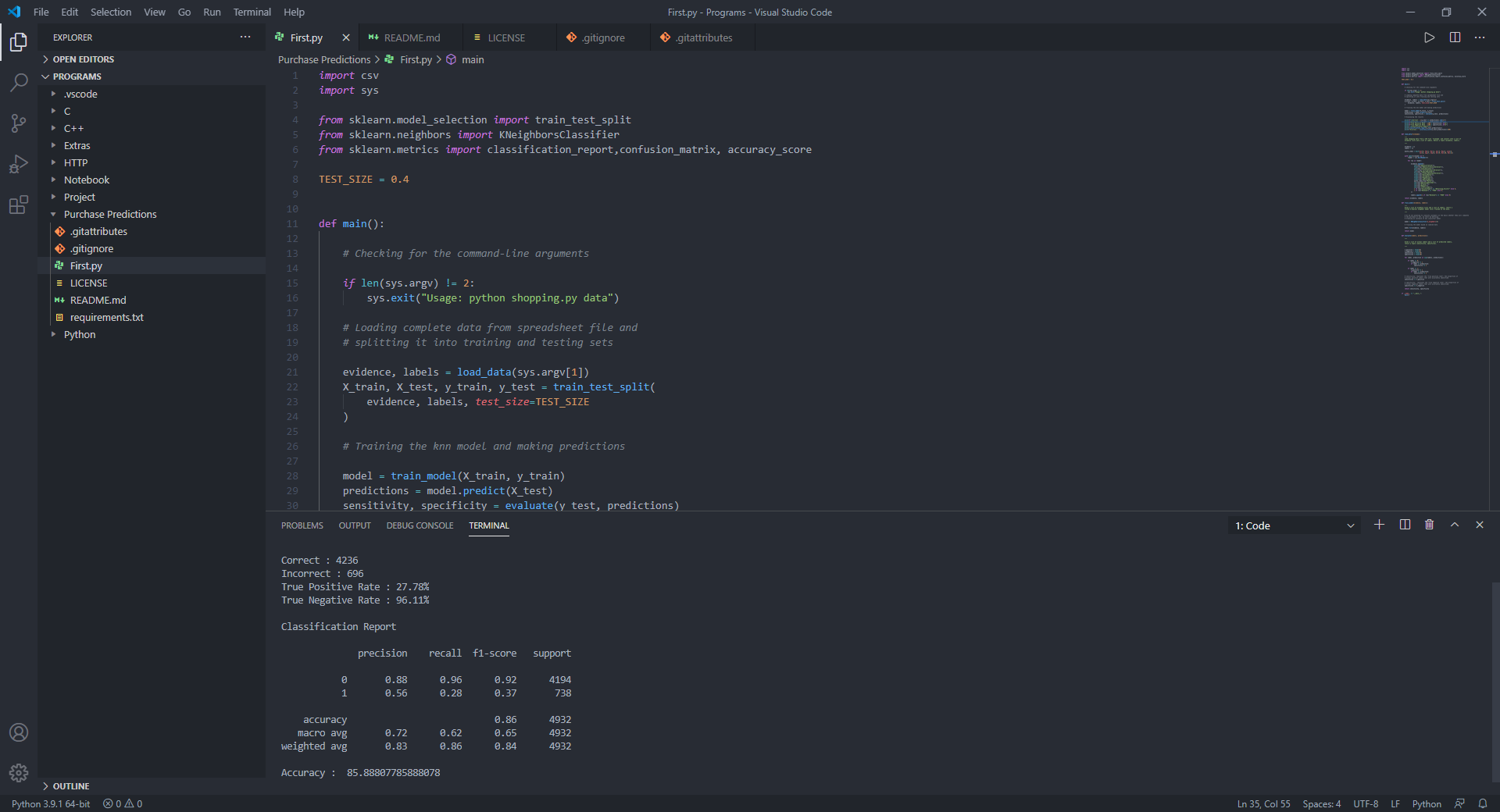
sensitivity , specificity = evaluate ( y_test , predictions )
# Displaying the results
print ( f"Correct: { ( y_test == predictions ). sum () } " )
print ( f"Incorrect: { ( y_test != predictions ). sum () } " )
print ( f"True Positive Rate: { 100 * sensitivity :.2f } %" )
print ( f"True Negative Rate: { 100 * specificity :.2f } %" )
# Displaying the classification report for model evaluation
print ( " n Classification Report n " )
print ( classification_report ( y_test , predictions ))
print ( "Accuracy : " , accuracy_score ( y_test , predictions ) * 100 )Для исследования я использовал набор данных онлайн -активности клиента для веб -сайта, включающий такие параметры, как тип трафика, регион, продолжительность, связанная с продуктом, связанный с продуктом, месяц и т. Д.
Вклад в развитие технологий машинного обучения, этот проект может быть полезен для веб -сайта онлайн -покупок, которые процветают для повышения их вовлечения клиентов.
Будущий объем проекта включает в себя то, что он может быть реализован в более широком масштабе в дополнение к другим параметрам взаимодействия с клиентами, таких как система обмена сообщениями, включающая снижение цены, в частности заинтересованных товаров и т. Д.
Во время обычных покупок в Интернете наиболее распространенное явление, которое наблюдается, что не все пользователи в конечном итоге будут покупать некоторые вещи. Как правило, большинство посетителей, вероятно, не заканчивают покупкой во время этой веб -сессии. Таким образом, для веб -сайта AE Commerce было бы полезно предсказать, намерен ли пользователь совершить покупку или нет, отобразить различное содержимое и соответственно, что -то вроде предложений скидки или купонов и т. Д., Если веб -сайт подозревает, если пользователь не намеревается завершить покупку.
Чтобы решить эту проблему, мы продолжим, выбив классификатор K-Nearest для классификации пользователей в двух предопределенных классах IE, независимо от того, выполнят ли они покупку или не основаны на таких функциях, как пользователи покупки на выходных, какой веб-браузер они используют, сколько страниц они посещали, и т. Д.


