Customer Purchase Predection
1.0.0
$ git clone https://github.com/krvaibhaw/Customer-Purchase-Predection.git
$ cd Customer-Purchase-Predection
$ pip install requirements.txt
$ python model.py <data folder path>/<file.csv>
Exemplo :
$ python model.py data/activity_data.csv
Iniciamos a avaliação carregando o conjunto de dados de atividades do cliente para um site usando o argumento da linha de comando. Para o estudo, utilizamos o conjunto de dados de atividades on -line do cliente para um site, envolvendo parâmetros como tipo de tráfego, região, duração relacionada ao produto, produto relacionado ao produto, mês etc.
if len ( sys . argv ) != 2 :
sys . exit ( "Usage: python shopping.py data" )
evidence , labels = load_data ( sys . argv [ 1 ])É necessário converter os recursos categóricos em numéricos, porque todos os algoritmos de aprendizado de máquina interpreta apenas valores numéricos. A etapa do NENT envolve a seleção de recursos com base na importância do recurso, seguida pela substituição dos valores de valores da string.
month_index = dict ( Jan = 0 , Feb = 1 , Mar = 2 , Apr = 3 , May = 4 , June = 5 ,
Jul = 6 , Aug = 7 , Sep = 8 , Oct = 9 , Nov = 10 , Dec = 11 )
( month_index [ row [ "Month" ]],
1 if row [ "VisitorType" ] == "Returning_Visitor" else 0 ,
1 if row [ "Weekend" ] == "TRUE" else 0 )
labels . append ( 1 if row [ "Revenue" ] == "TRUE" else 0 )O procedimento envolve tomar um conjunto de dados e dividi -lo em dois subconjuntos. O primeiro subconjunto é usado para se ajustar ao modelo e é chamado de conjunto de dados de treinamento. O segundo subconjunto não é usado para treinar o modelo; Em vez disso, o elemento de entrada do conjunto de dados é fornecido ao modelo, então as previsões são feitas e comparadas aos valores esperados. Este segundo conjunto de dados é referido como o conjunto de dados de teste. E então preparamos os dados de treinamento e teste para o modelo usando a função Train_test_split () no módulo Sklearn.
from sklearn . model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split (
evidence , labels , test_size = TEST_SIZE
)Em seguida, criamos o modelo AUR K-Darest Neighbours (KNN) usando o modelo Sklearn que instalamos na seção de instalação de requisitos. O algoritmo KNN assume que coisas semelhantes existem nas proximidades. Em outras palavras, coisas semelhantes estão próximas uma da outra.
def train_model ( evidence , labels ):
model = KNeighborsClassifier ( n_neighbors = 1 )
model . fit ( evidence , labels )
return modelOs dados de treinamento serão usados para treinar o modelo KNN (vizinhos mais parecidos). E os dados do teste serão usados para validar o modelo. Ele preverá os rótulos dos vetores de recursos invisíveis.
model = train_model ( X_train , y_train )
predictions = model . predict ( X_test )Finalmente, o modelo é então avaliado. A avaliação do modelo visa estimar a precisão da generalização de um modelo em dados futuros (invisíveis/fora da amostra).
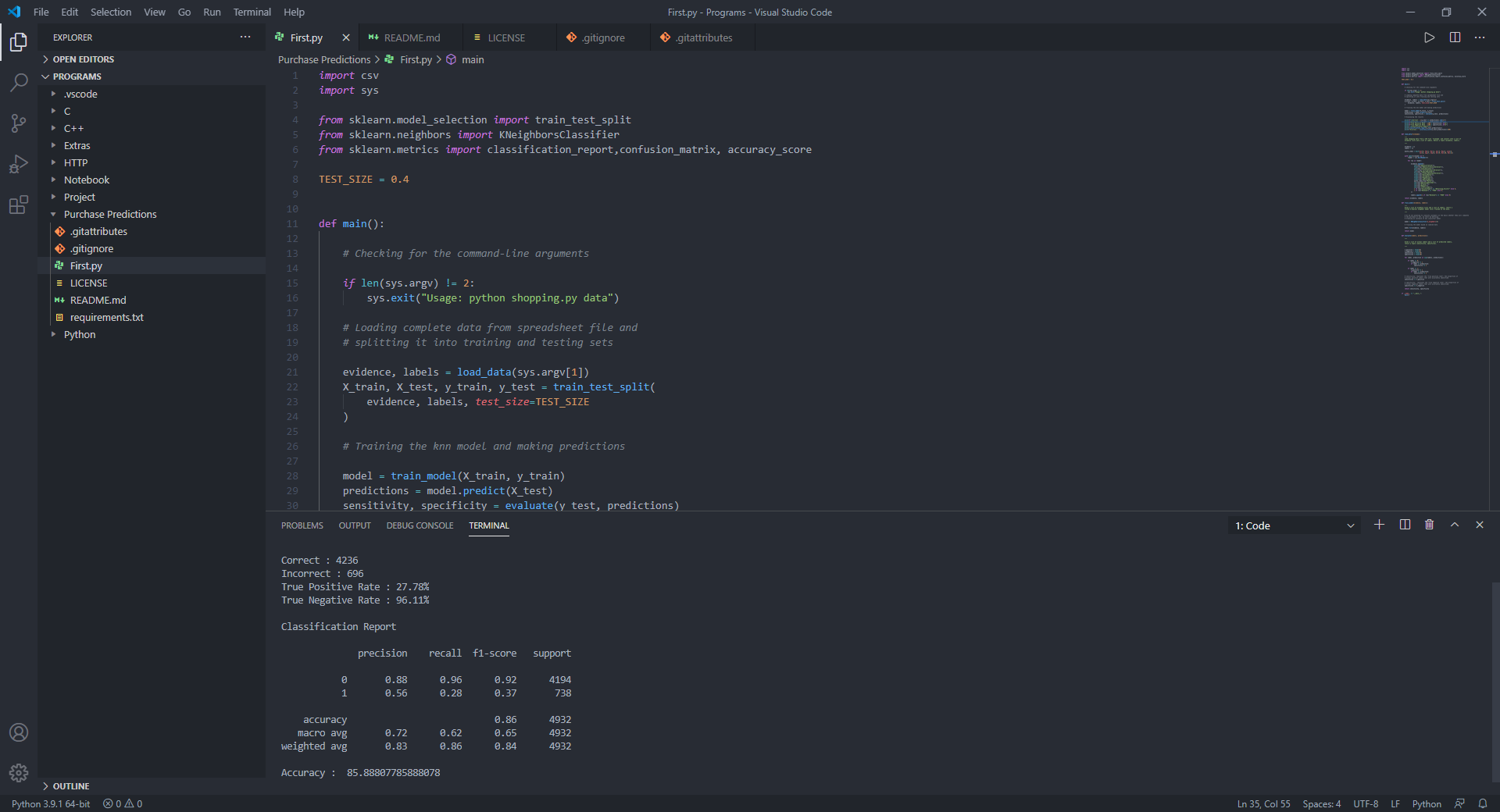
sensitivity , specificity = evaluate ( y_test , predictions )
# Displaying the results
print ( f"Correct: { ( y_test == predictions ). sum () } " )
print ( f"Incorrect: { ( y_test != predictions ). sum () } " )
print ( f"True Positive Rate: { 100 * sensitivity :.2f } %" )
print ( f"True Negative Rate: { 100 * specificity :.2f } %" )
# Displaying the classification report for model evaluation
print ( " n Classification Report n " )
print ( classification_report ( y_test , predictions ))
print ( "Accuracy : " , accuracy_score ( y_test , predictions ) * 100 )Para o estudo, usei o conjunto de dados de atividades on -line do cliente para um site, envolvendo parâmetros como tipo de tráfego, região, duração relacionada ao produto, produto relacionado ao produto, mês etc.
Contribuindo para o avanço das tecnologias de aprendizado de máquina, este projeto pode ser útil para o site de compras on -line que está prosperando para aumentar o envolvimento do cliente.
O escopo futuro do projeto inclui que ele pode ser implementado em uma escala maior, além de outros parâmetros de engajamento do cliente, como o sistema de mensagens que envolvem a queda de preços em particular item interessado, etc.
Durante as compras normais on -line, a ocorrência mais comum observada que nem todos os usuários acabarão comprando algumas coisas. Geralmente, a maioria dos visitantes provavelmente não acaba passando pela compra durante a sessão da web. Portanto, seria benéfico para o site do AE Commerce prever se um usuário pretende fazer uma compra ou não e exibir conteúdos diferentes e oferece de acordo, algo como ofertas ou cupons com desconto, etc., se o site suspeitar se o usuário não tiver a intenção de concluir a compra.
Para resolver esse problema, prosseguimos, abalando um classificador mais antigo para classificar os usuários em dois IE predefinidos, se eles concluirão a compra ou não com base em recursos como se os usuários estão comprando em um fim de semana, que navegador da web estão usando, quantas páginas eles visitaram etc.


