Customer Purchase Predection
1.0.0
$ git clone https://github.com/krvaibhaw/Customer-Purchase-Predection.git
$ cd Customer-Purchase-Predection
$ pip install requirements.txt
$ python model.py <data folder path>/<file.csv>
Contoh :
$ python model.py data/activity_data.csv
Kami memulai evaluasi dengan memuat dataset aktivitas pelanggan untuk situs web menggunakan argumen baris perintah. Untuk penelitian ini, kami telah menggunakan dataset aktivitas online pelanggan untuk situs web, yang melibatkan parameter seperti jenis lalu lintas, wilayah, durasi terkait produk, terkait produk, bulan, dll.
if len ( sys . argv ) != 2 :
sys . exit ( "Usage: python shopping.py data" )
evidence , labels = load_data ( sys . argv [ 1 ])Perlu untuk mengubah fitur kategorikal menjadi numerik karena semua algoritma pembelajaran mesin hanya menginterpretasikan nilai numerik. Langkah NEXT melibatkan pemilihan fitur berdasarkan kepentingan fitur diikuti dengan mengganti nilai -nilai nilai numerik string.
month_index = dict ( Jan = 0 , Feb = 1 , Mar = 2 , Apr = 3 , May = 4 , June = 5 ,
Jul = 6 , Aug = 7 , Sep = 8 , Oct = 9 , Nov = 10 , Dec = 11 )
( month_index [ row [ "Month" ]],
1 if row [ "VisitorType" ] == "Returning_Visitor" else 0 ,
1 if row [ "Weekend" ] == "TRUE" else 0 )
labels . append ( 1 if row [ "Revenue" ] == "TRUE" else 0 )Prosedur ini melibatkan pengambilan dataset dan membaginya menjadi dua himpunan bagian. Subset pertama digunakan agar sesuai dengan model dan disebut sebagai dataset pelatihan. Subset kedua tidak digunakan untuk melatih model; Sebaliknya, elemen input dari dataset disediakan untuk model, maka prediksi dibuat dan dibandingkan dengan nilai yang diharapkan. Dataset kedua ini disebut sebagai dataset pengujian. Dan kemudian kami menyiapkan fungsi pelatihan dan pengujian untuk model menggunakan fungsi train_test_split () dari modul SKLEARN.
from sklearn . model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split (
evidence , labels , test_size = TEST_SIZE
)Kemudian kami membuat model AUR K-Nearest Neighbors (KNN) dengan menggunakan model SKLEARN yang telah kami instal di bagian Instalasi Persyaratan. Algoritma KNN mengasumsikan bahwa hal -hal serupa ada dalam jarak dekat. Dengan kata lain, hal serupa dekat satu sama lain.
def train_model ( evidence , labels ):
model = KNeighborsClassifier ( n_neighbors = 1 )
model . fit ( evidence , labels )
return modelData pelatihan akan digunakan untuk melatih model KNN (K-Nearest Nearbors). Dan data uji akan digunakan untuk memvalidasi model. Ini akan memprediksi label untuk vektor fitur yang tidak terlihat.
model = train_model ( X_train , y_train )
predictions = model . predict ( X_test )Akhirnya, model kemudian dievaluasi. Evaluasi model bertujuan untuk memperkirakan akurasi generalisasi model pada data (tidak terlihat/out-sampel) di masa depan.
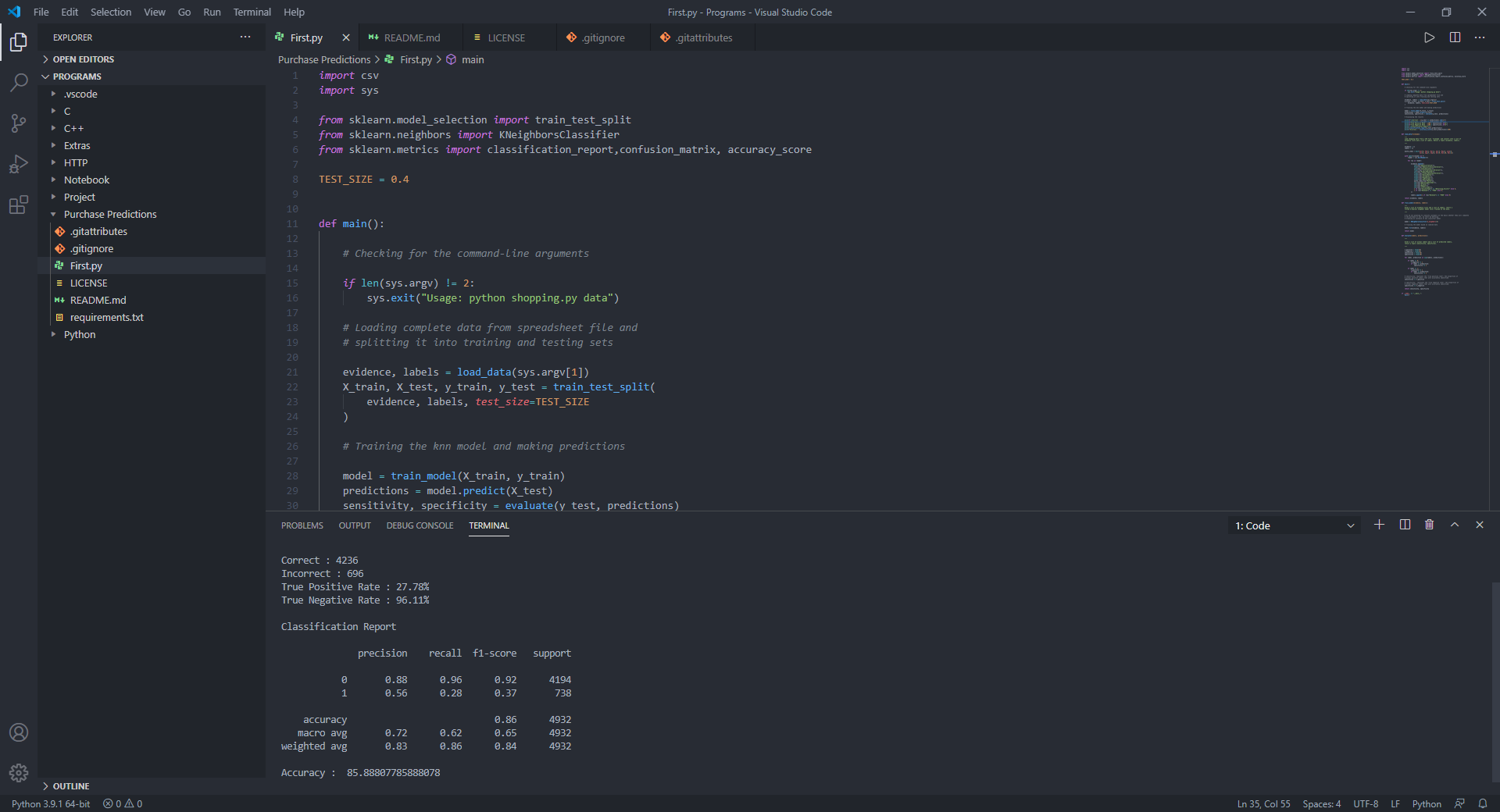
sensitivity , specificity = evaluate ( y_test , predictions )
# Displaying the results
print ( f"Correct: { ( y_test == predictions ). sum () } " )
print ( f"Incorrect: { ( y_test != predictions ). sum () } " )
print ( f"True Positive Rate: { 100 * sensitivity :.2f } %" )
print ( f"True Negative Rate: { 100 * specificity :.2f } %" )
# Displaying the classification report for model evaluation
print ( " n Classification Report n " )
print ( classification_report ( y_test , predictions ))
print ( "Accuracy : " , accuracy_score ( y_test , predictions ) * 100 )Untuk penelitian ini saya telah menggunakan dataset aktivitas online pelanggan untuk situs web, yang melibatkan parameter seperti jenis lalu lintas, wilayah, durasi terkait produk, terkait produk, bulan, dll.
Berkontribusi pada kemajuan teknologi pembelajaran mesin, proyek ini mungkin bermanfaat untuk situs web belanja online yang berkembang untuk meningkatkan keterlibatan pelanggan mereka.
Lingkup proyek di masa depan termasuk bahwa dapat diimplementasikan pada skala yang lebih besar di samping parameter keterlibatan pelanggan lainnya seperti sistem pesan yang melibatkan penurunan harga khususnya item yang tertarik, dll.
Selama belanja normal online, kejadian paling umum yang diamati bahwa tidak semua pengguna akan akhirnya membeli beberapa barang. Secara umum, sebagian besar pengunjung kemungkinan tidak akan melalui pembelian selama sesi web itu. Jadi akan bermanfaat bagi situs web AE Commerce untuk memprediksi apakah pengguna bermaksud melakukan pembelian atau tidak dan menampilkan konten yang berbeda dan menawarkannya, sesuatu seperti penawaran diskon atau kupon, dll, jika situs web tersebut mencurigai jika pengguna tidak dimaksudkan untuk menyelesaikan pembelian.
Untuk mengatasi masalah ini, kami melanjutkan dengan menggulung classifier K-nearest untuk mengklasifikasikan pengguna dalam dua kelas IE yang telah ditentukan, apakah mereka akan menyelesaikan pembelian atau tidak berdasarkan fitur seperti apakah pengguna berbelanja di akhir pekan, browser web apa yang mereka gunakan, berapa banyak halaman yang telah mereka kunjungi, dll.


