Customer Purchase Predection
1.0.0
$ git clone https://github.com/krvaibhaw/Customer-Purchase-Predection.git
$ cd Customer-Purchase-Predection
$ pip install requirements.txt
$ python model.py <data folder path>/<file.csv>
例 :
$ python model.py data/activity_data.csv
コマンドライン引数を使用して、Webサイトの顧客アクティビティデータセットをロードすることにより、評価を開始しました。この調査では、トラフィックタイプ、地域、製品関連の期間、製品関連、月などのパラメーターを含む、Webサイトに顧客オンラインアクティビティデータセットを利用しています。
if len ( sys . argv ) != 2 :
sys . exit ( "Usage: python shopping.py data" )
evidence , labels = load_data ( sys . argv [ 1 ])すべての機械学習アルゴリズムが数値値のみを解釈するため、カテゴリの特徴を数値に変換する必要があります。
month_index = dict ( Jan = 0 , Feb = 1 , Mar = 2 , Apr = 3 , May = 4 , June = 5 ,
Jul = 6 , Aug = 7 , Sep = 8 , Oct = 9 , Nov = 10 , Dec = 11 )
( month_index [ row [ "Month" ]],
1 if row [ "VisitorType" ] == "Returning_Visitor" else 0 ,
1 if row [ "Weekend" ] == "TRUE" else 0 )
labels . append ( 1 if row [ "Revenue" ] == "TRUE" else 0 )この手順では、データセットを取り、2つのサブセットに分割することが含まれます。最初のサブセットはモデルの適合に使用され、トレーニングデータセットと呼ばれます。 2番目のサブセットは、モデルのトレーニングに使用されません。代わりに、データセットの入力要素がモデルに提供され、予測が行われ、期待値と比較されます。この2番目のデータセットは、テストデータセットと呼ばれます。次に、SklearnモジュールからTRAIN_TEST_SPLIT()関数を使用して、モデルのトレーニングデータとテストデータを準備します。
from sklearn . model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split (
evidence , labels , test_size = TEST_SIZE
)次に、要件インストールセクションにインストールしたSklearnモデルを使用して、AUR K-Nearest Neighbors(KNN)モデルを作成します。 KNNアルゴリズムは、同様のものが近接して存在することを前提としています。言い換えれば、同様のことが互いに近くにあります。
def train_model ( evidence , labels ):
model = KNeighborsClassifier ( n_neighbors = 1 )
model . fit ( evidence , labels )
return modelトレーニングデータは、KNN(K-nearest Neighbors)モデルのトレーニングに使用されます。テストデータは、モデルの検証に使用されます。指定されていない機能ベクトルのラベルが予測されます。
model = train_model ( X_train , y_train )
predictions = model . predict ( X_test )最後に、モデルが評価されます。モデル評価は、将来(目に見えない/サンプル外)データに関するモデルの一般化精度を推定することを目的としています。
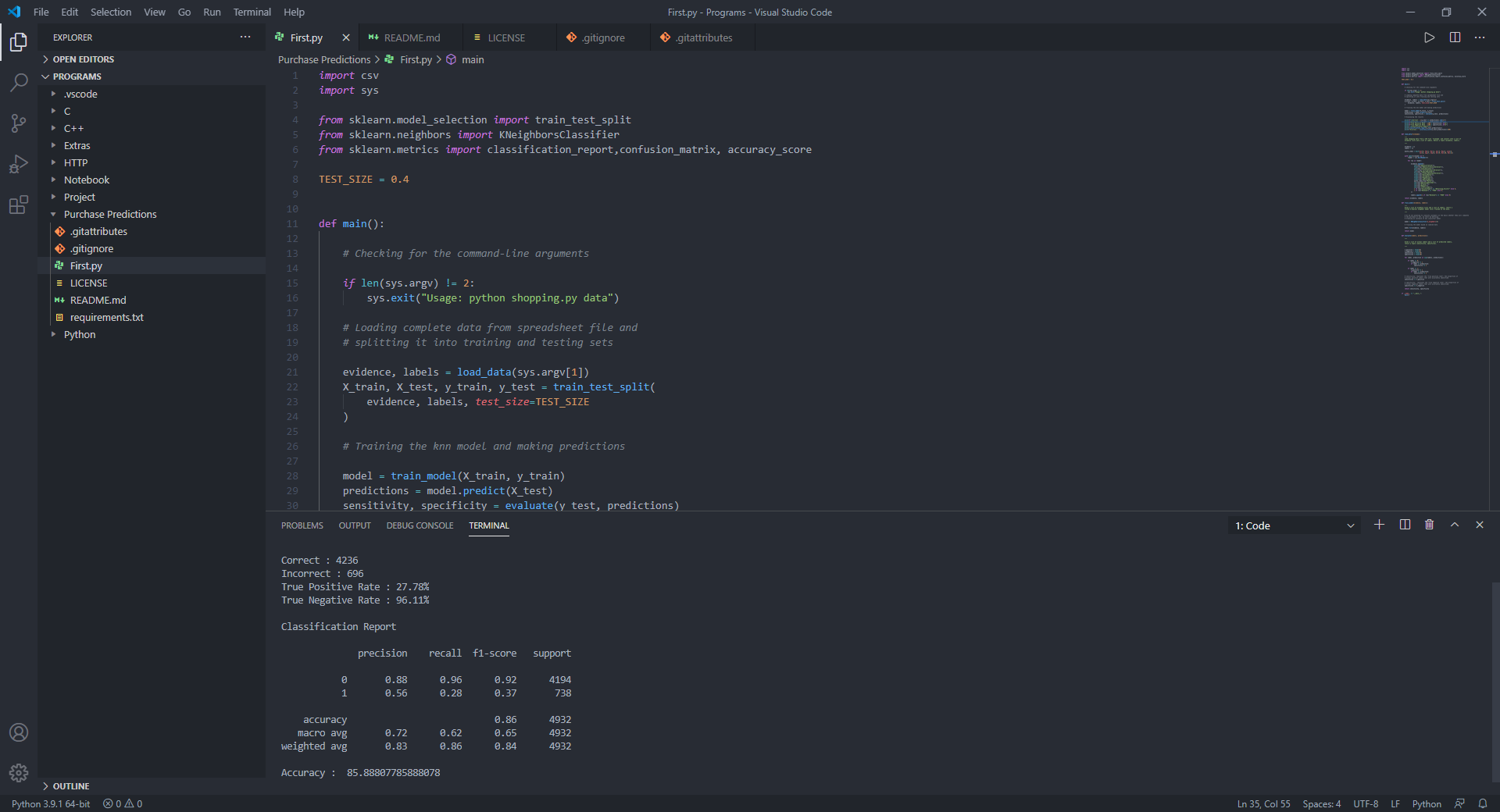
sensitivity , specificity = evaluate ( y_test , predictions )
# Displaying the results
print ( f"Correct: { ( y_test == predictions ). sum () } " )
print ( f"Incorrect: { ( y_test != predictions ). sum () } " )
print ( f"True Positive Rate: { 100 * sensitivity :.2f } %" )
print ( f"True Negative Rate: { 100 * specificity :.2f } %" )
# Displaying the classification report for model evaluation
print ( " n Classification Report n " )
print ( classification_report ( y_test , predictions ))
print ( "Accuracy : " , accuracy_score ( y_test , predictions ) * 100 )この調査では、トラフィックタイプ、地域、製品関連の期間、製品関連、月などのパラメーターを含む、ウェブサイトに顧客オンラインアクティビティデータセットを使用しました。
機械学習テクノロジーの進歩に貢献して、このプロジェクトは、顧客エンゲージメントを増やすために繁栄しているオンラインショッピングWebサイトに役立つ可能性があります。
プロジェクトの将来の範囲には、特に関心のあるアイテムなどの価格の下落を含むメッセージングシステムなど、他の顧客エンゲージメントパラメーターに加えて、より大規模に実装できることが含まれます。
オンラインでの通常のショッピング中、すべてのユーザーがいくつかのものを購入するわけではないことが観察される最も一般的な発生。一般的に、訪問者の大部分は、そのWebセッション中に購入を行うことにならない可能性があります。そのため、AE Commerce Webサイトがユーザーが購入するかどうかを予測し、さまざまなコンテンツを表示し、それに応じて提供して提供すること、割引オファーやクーポンなど、ユーザーが購入を完了する予定がないかどうかを疑う場合は有益です。
この問題を解決するために、2つの事前定義されたクラスIEのユーザーを分類するためのK-Nearest分類器を拡大することで、ユーザーが週末に買い物をしているかどうか、使用しているWebブラウザー、訪問したページの数などに基づいて購入を完了するかどうかにかかわらず進みます。


