Customer Purchase Predection
1.0.0
$ git clone https://github.com/krvaibhaw/Customer-Purchase-Predection.git
$ cd Customer-Purchase-Predection
$ pip install requirements.txt
$ python model.py <data folder path>/<file.csv>
Beispiel :
$ python model.py data/activity_data.csv
Wir haben mit der Bewertung begonnen, indem wir den Kundenaktivitätsdatensatz für eine Website mithilfe des Befehlszeilenarguments geladen haben. Für die Studie haben wir Kunden -Online -Aktivitätsdatensatz für eine Website verwendet, die Parameter wie Verkehrstyp, Region, produktbezogene Dauer, produktbezogene, Monat usw. umfasst.
if len ( sys . argv ) != 2 :
sys . exit ( "Usage: python shopping.py data" )
evidence , labels = load_data ( sys . argv [ 1 ])Es ist notwendig, kategorische Merkmale in numerisch umzuwandeln, da alle Algorithmen für maschinelles Lernen nur numerische Werte interpretieren. Der Schritt -Schritt umfasst die Merkmalsauswahl auf der Grundlage der Merkmals Bedeutung, gefolgt vom Ersetzen der numerischen Werte der Zeichenfolge.
month_index = dict ( Jan = 0 , Feb = 1 , Mar = 2 , Apr = 3 , May = 4 , June = 5 ,
Jul = 6 , Aug = 7 , Sep = 8 , Oct = 9 , Nov = 10 , Dec = 11 )
( month_index [ row [ "Month" ]],
1 if row [ "VisitorType" ] == "Returning_Visitor" else 0 ,
1 if row [ "Weekend" ] == "TRUE" else 0 )
labels . append ( 1 if row [ "Revenue" ] == "TRUE" else 0 )Die Prozedur umfasst die Einnahme eines Datensatzes und die Aufteilung in zwei Teilmengen. Die erste Teilmenge wird zum Modell des Modells verwendet und als Trainingsdatensatz bezeichnet. Die zweite Teilmenge wird nicht verwendet, um das Modell zu trainieren; Stattdessen wird dem Modell das Eingabeelement des Datensatzes bereitgestellt, dann werden Vorhersagen getroffen und mit den erwarteten Werten verglichen. Dieser zweite Datensatz wird als Testdatensatz bezeichnet. Und dann bereiten wir die Trainings- und Testdaten für das Modell mit der Funktion "train_test_split () aus dem Sklearn -Modul vor.
from sklearn . model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split (
evidence , labels , test_size = TEST_SIZE
)Anschließend erstellen wir das AUR K-Nearest Nachbarmodell (KNN) mit dem Sklearn-Modell, das wir im Abschnitt "Anforderungsinstallation" installiert haben. Der KNN -Algorithmus geht davon aus, dass ähnliche Dinge in unmittelbarer Nähe existieren. Mit anderen Worten, ähnliche Dinge liegen nahe zueinander.
def train_model ( evidence , labels ):
model = KNeighborsClassifier ( n_neighbors = 1 )
model . fit ( evidence , labels )
return modelDie Trainingsdaten werden verwendet, um das KNN-Modell (K-Nearest Nachbarn) zu trainieren. Und die Testdaten werden verwendet, um das Modell zu validieren. Es wird die Etiketten für die angegebenen unsichtbaren Feature -Vektoren vorhersagen.
model = train_model ( X_train , y_train )
predictions = model . predict ( X_test )Schließlich wird das Modell dann bewertet. Die Modellbewertung zielt darauf ab, die Verallgemeinerungsgenauigkeit eines Modells zu zukünftigen Daten (unsichtbare/außerhalb der Stichprobe) abzuschätzen.
sensitivity , specificity = evaluate ( y_test , predictions )
# Displaying the results
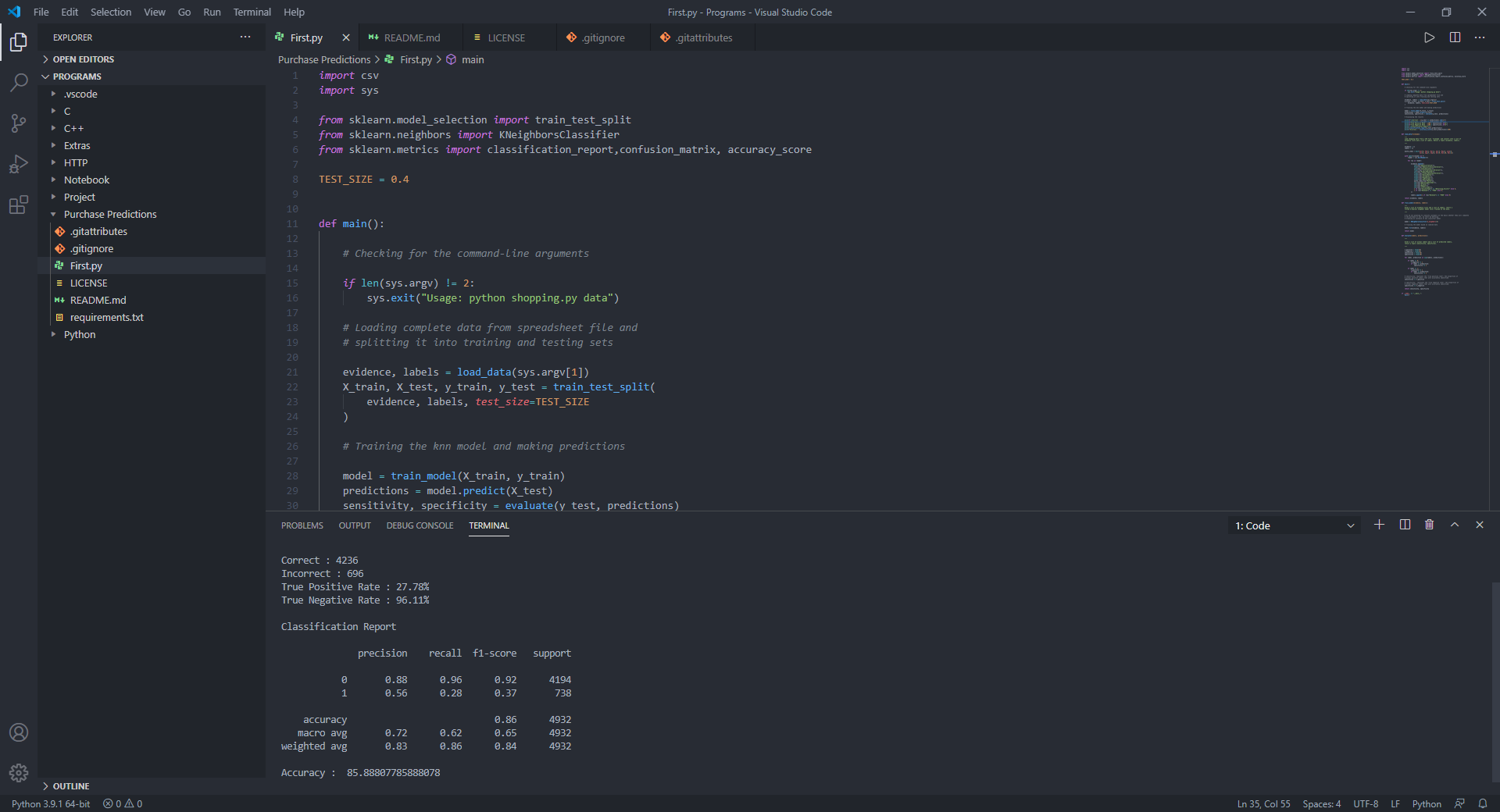
print ( f"Correct: { ( y_test == predictions ). sum () } " )
print ( f"Incorrect: { ( y_test != predictions ). sum () } " )
print ( f"True Positive Rate: { 100 * sensitivity :.2f } %" )
print ( f"True Negative Rate: { 100 * specificity :.2f } %" )
# Displaying the classification report for model evaluation
print ( " n Classification Report n " )
print ( classification_report ( y_test , predictions ))
print ( "Accuracy : " , accuracy_score ( y_test , predictions ) * 100 )Für die Studie habe ich den Kunden -Online -Aktivitätsdatensatz für eine Website verwendet, das Parameter wie Verkehrstyp, Region, produktbezogene Dauer, produktbezogene, Monat usw. umfasst.
Dieses Projekt ist bei der Weiterentwicklung maschineller Lerntechnologien bei der Online -Einkaufswebsite hilfreich, die für die Steigerung ihres Kundenbetriebs gedeiht.
Zukünftiger Umfang des Projekts umfasst, dass es zusätzlich zu anderen Kundenbindungsparametern wie Messaging -Systemen in größerem Maßstab implementiert werden kann, das bei einem bestimmten interessierten Artikel usw. einen Preisabfall beinhaltet, usw.
Während des normalen Online -Einkaufs ist das häufigste Ereignis, das beobachtet wird, dass nicht alle Benutzer einige Dinge kaufen. Im Allgemeinen durchlaufen die meisten Besucher während dieser Websitzung wahrscheinlich nicht den Kauf. Daher wäre es für die AE Commerce -Website von Vorteil, vorherzusagen, ob ein Benutzer einen Kauf tätigen oder nicht, und unterschiedliche Inhalte und Angebote entsprechend, so etwas wie Rabattangebote oder Gutscheine usw. anzeigen, wenn die Website vermutet, ob der Benutzer nicht beabsichtigt ist, den Kauf abzuschließen.
Um dieses Problem zu lösen, gehen wir mit einem K-Nearest-Klassifikator für die Klassifizierung von Benutzern in zwei vordefinierten Klassen vor, dh, ob sie den Kauf abschließen oder nicht, basierend auf Funktionen, z. B. ob die Benutzer an einem Wochenende einkaufen, welchen Webbrowser sie verwenden, wie viele Seiten sie besucht haben usw. usw.


