Customer Purchase Predection
1.0.0
$ git clone https://github.com/krvaibhaw/Customer-Purchase-Predection.git
$ cd Customer-Purchase-Predection
$ pip install requirements.txt
$ python model.py <data folder path>/<file.csv>
예 :
$ python model.py data/activity_data.csv
명령 줄 인수를 사용하여 웹 사이트의 고객 활동 데이터 세트를로드하여 평가를 시작했습니다. 이 연구를 위해, 우리는 트래픽 유형, 지역, 제품 관련 기간, 제품 관련, 월 등과 같은 매개 변수를 포함하는 웹 사이트에 고객 온라인 활동 데이터 세트를 사용했습니다.
if len ( sys . argv ) != 2 :
sys . exit ( "Usage: python shopping.py data" )
evidence , labels = load_data ( sys . argv [ 1 ])모든 머신 러닝 알고리즘은 숫자 값 만 해석하기 때문에 범주 형 기능을 숫자로 변환해야합니다 .next 단계에는 기능 중요성을 기반으로 한 기능 선택과 문자열 값 숫자 값을 대체합니다.
month_index = dict ( Jan = 0 , Feb = 1 , Mar = 2 , Apr = 3 , May = 4 , June = 5 ,
Jul = 6 , Aug = 7 , Sep = 8 , Oct = 9 , Nov = 10 , Dec = 11 )
( month_index [ row [ "Month" ]],
1 if row [ "VisitorType" ] == "Returning_Visitor" else 0 ,
1 if row [ "Weekend" ] == "TRUE" else 0 )
labels . append ( 1 if row [ "Revenue" ] == "TRUE" else 0 )절차에는 데이터 세트를 가져 와서 두 개의 서브 세트로 나누는 것이 포함됩니다. 첫 번째 서브 세트는 모델에 맞는 데 사용되며 교육 데이터 세트라고합니다. 두 번째 서브 세트는 모델을 훈련시키는 데 사용되지 않습니다. 대신, 데이터 세트의 입력 요소가 모델에 제공되면 예측이 이루어지고 예상 값과 비교됩니다. 이 두 번째 데이터 세트는 테스트 데이터 세트라고합니다. 그런 다음 Sklearn 모듈에서 TRAIN_TEST_SPLIT () 함수를 사용하여 모델에 대한 교육 및 테스트 데이터를 준비합니다.
from sklearn . model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split (
evidence , labels , test_size = TEST_SIZE
)그런 다음 요구 사항 설치 섹션에 설치 한 Sklearn 모델을 사용하여 AUR K-NAREARTES 이웃 (KNN) 모델을 만듭니다. KNN 알고리즘은 비슷한 것들이 가까이에 있다고 가정합니다. 다시 말해, 비슷한 것들이 서로 가까이 있습니다.
def train_model ( evidence , labels ):
model = KNeighborsClassifier ( n_neighbors = 1 )
model . fit ( evidence , labels )
return model교육 데이터는 KNN (K-Nearest Neighbors) 모델을 훈련시키는 데 사용됩니다. 테스트 데이터는 모델을 검증하는 데 사용됩니다. 주어진 보이지 않는 기능 벡터에 대한 레이블을 예측합니다.
model = train_model ( X_train , y_train )
predictions = model . predict ( X_test )마지막으로 모델이 평가됩니다. 모델 평가는 미래 (보이지 않는/샘플 외) 데이터에 대한 모델의 일반화 정확도를 추정하는 것을 목표로합니다.
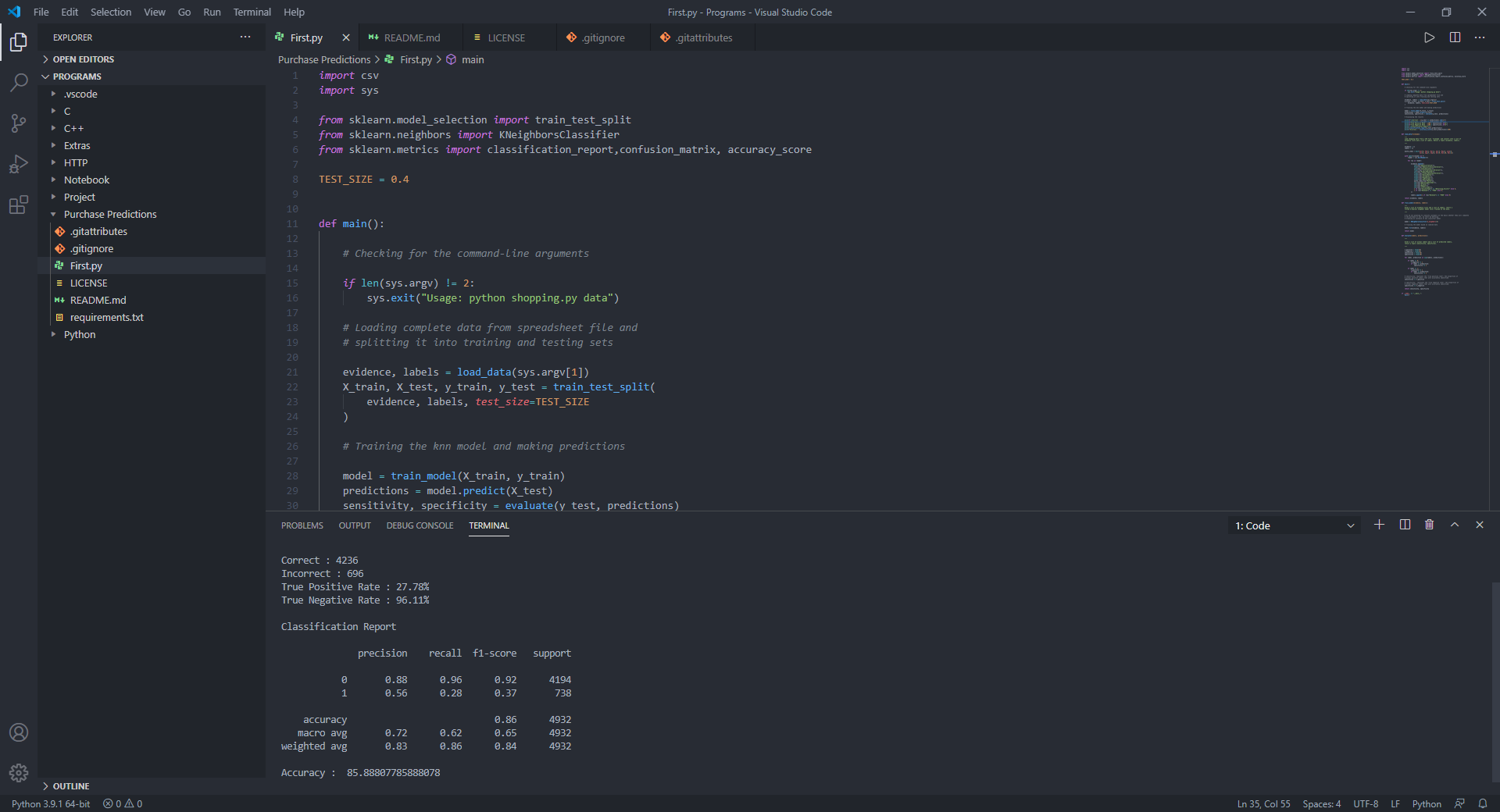
sensitivity , specificity = evaluate ( y_test , predictions )
# Displaying the results
print ( f"Correct: { ( y_test == predictions ). sum () } " )
print ( f"Incorrect: { ( y_test != predictions ). sum () } " )
print ( f"True Positive Rate: { 100 * sensitivity :.2f } %" )
print ( f"True Negative Rate: { 100 * specificity :.2f } %" )
# Displaying the classification report for model evaluation
print ( " n Classification Report n " )
print ( classification_report ( y_test , predictions ))
print ( "Accuracy : " , accuracy_score ( y_test , predictions ) * 100 )연구의 경우 트래픽 유형, 지역, 제품 관련 기간, 제품 관련, 월 등과 같은 매개 변수와 관련된 웹 사이트에 고객 온라인 활동 데이터 세트를 사용했습니다.
기계 학습 기술의 발전에 기여한이 프로젝트는 고객 참여를 높이기 위해 번성하는 온라인 쇼핑 웹 사이트에 도움이 될 수 있습니다.
프로젝트의 향후 범위에는 특정 관심있는 항목의 가격 하락과 관련된 메시징 시스템과 같은 다른 고객 참여 매개 변수 외에도 더 큰 규모로 구현할 수 있습니다.
온라인 쇼핑 중에는 모든 사용자가 일부 물건을 구매하게되는 것은 아닙니다. 일반적으로, 대부분의 방문자는 해당 웹 세션에서 구매를 거치지 않을 것입니다. 따라서 AE Commerce 웹 사이트에서 사용자가 구매를 완료하지 않은 경우 웹 사이트가 의심되는 경우, 사용자가 구매를하고 다른 내용을 표시 할 것인지, 다른 컨텐츠를 표시 할 것인지, 그에 따라 할인 제안 또는 쿠폰 등을 표시하는지 예측하는 것이 좋습니다.
이 문제를 해결하기 위해, 우리는 사용자가 주말에 쇼핑하는지 여부, 사용중인 웹 브라우저, 방문한 페이지 수 등과 같은 기능을 기반으로 구매를 완료할지 여부에 관계없이 두 개의 사전 정의 된 클래스 IE에서 사용자를 분류하기위한 K-NAREARTEST CLASEFIER를 불렀습니다.


