Многоподобный TD-TSR
Проверьте его на исходном коде нашей статьи: многопрофильные таблицы извлечения из изображений документов с использованием многоэтапного трубопровода для обнаружения таблиц и распознавания структуры таблицы
Описание
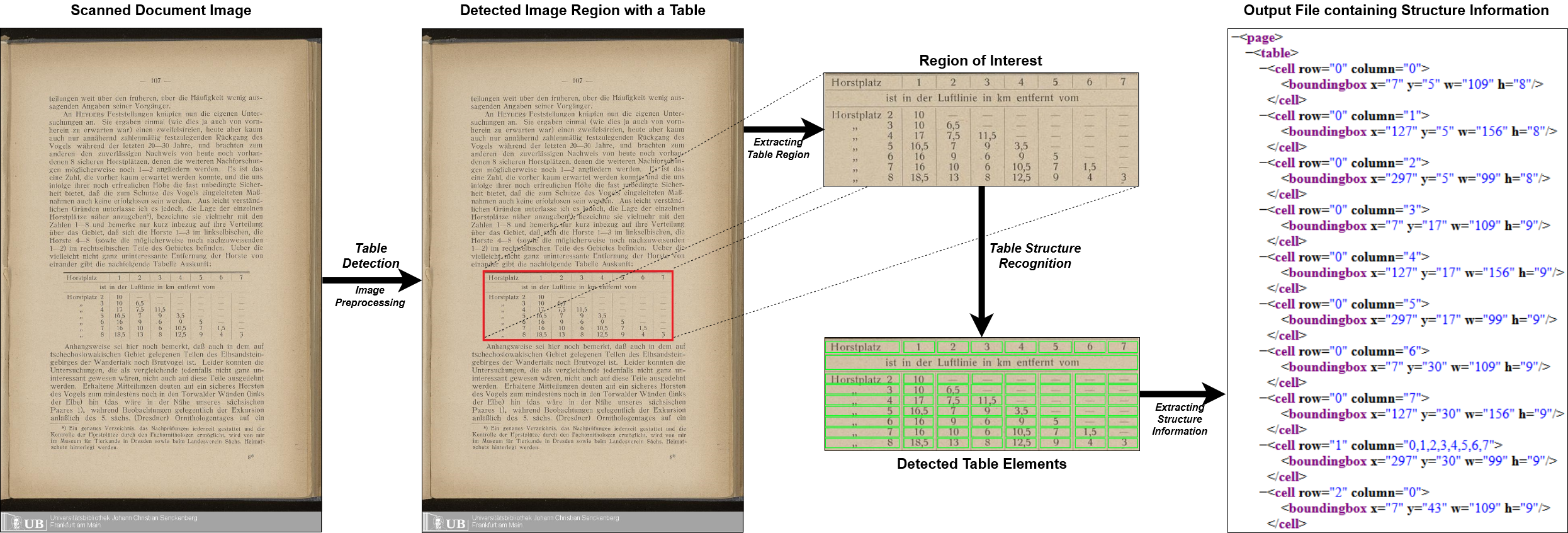
Многоподобный TD-TSR весь трубопровод
Поскольку глобальные тенденции смещаются в сторону промышленности, управляемых данными, спрос на автоматизированные алгоритмы, которые могут преобразовать цифровые изображения отсканированных документов в читаемую информацию о машине. Помимо возможности оцифровки данных для применения инструментов анализа данных, существует также масштабное улучшение автоматизации процессов, что ранее потребовало бы ручного проверки документов. Хотя введение технологий оптического распознавания символов (OCR) в основном решало задачу преобразования читаемых человеком символов из изображений в машиночитаемые символы, задача извлечения семантики таблицы была менее сосредоточена на за эти годы. Распознавание таблиц состоит из двух основных задач, а именно обнаружения таблицы и распознавания структуры таблицы. Большая часть предыдущей работы по этой проблеме фокусируется либо задачей, либо не предлагая сквозного решения или не обращая внимания на реальные условия применения, такие как повернутые изображения или шумовые артефакты внутри изображения документа. Недавняя работа показывает четкую тенденцию к глубокому обучению подходов в сочетании с использованием передачи обучения для задачи распознавания структуры таблицы из -за отсутствия достаточно больших наборов данных. В этой статье мы представляем многоэтажный трубопровод с именем с несколькими типами-TD-TSR, который предлагает сквозное решение для проблемы распознавания таблиц. Он использует современные модели глубокого обучения для обнаружения таблиц и различает 3 различных типа таблиц на основе границ таблиц. Для распознавания структуры таблицы мы используем детерминированный алгоритм, не управляемый данными, который работает на всех типах таблиц. Мы дополнительно представляем два алгоритма. Один для невозможных таблиц и один для граничных таблиц, которые являются основой алгоритма распознавания структуры использованных таблиц. Мы оцениваем многопрофильный набор данных о распознавании структуры таблиц ICDAR 2019 и достигаем нового современного.
Много типа-TD-TSR на полностью граничащих таблицах
Для TSR на полностью приоритетных таблицах мы используем операцию эрозии и дилатации, чтобы извлечь изображение ячейки сетки с рядовой колонкой без какого-либо текста или символов. Эрозионные ядра, как правило, являются тонкими вертикальными и горизонтальными полосками, которые длиннее общего размера шрифта, но короче, чем размер наименьшей ячейки сетки и, в частности, не должны быть шириной, чем наименьшая ширина границы стола. Использование этих ограничений размера ядра приводит к тому, что операция эрозии удаляет все шрифты и символы из таблицы при сохранении границ таблицы. Чтобы восстановить исходную форму линии, алгоритм применяет операцию дилатации, используя один и тот же размер ядра на каждом из двух разрушенных изображений, создавая изображение с вертикальной и второй с горизонтальными линиями. Наконец, алгоритм объединяет оба изображения с использованием битовой `` `или операции или повторной инвертирования значений пикселей, чтобы получить растровое изображение. Затем мы используем функцию контуров на изображении сетки, чтобы извлечь ограничительные коробки для каждой ячейки сетки.
Много типа TD-TSR на невозможных таблицах
Алгоритм TSR для невозможных таблиц работает аналогично тем, что для граничащих таблиц, но использует операцию эрозии по -другому. Ядро эрозии, в целом, является тонкой полосой с разницей, что горизонтальный размер горизонтального ядра включает в себя полную ширину изображения и вертикальный размер вертикального ядра полной высоты изображения. Алгоритм скользит оба ядра независимо по всему изображению слева направо для вертикального ядра и сверху вниз для горизонтального ядра. Во время этого процесса он ищет пустые строки и столбцы, которые не содержат никаких символов или шрифта. Полученные изображения инвертируются и объединяются с помощью битовой операции `` `и` `, создавая окончательный вывод. Выход-это изображение сетки сетки, аналогичное тому, что от TSR для граничащих таблиц, где перекрывающиеся области двух полученных изображений представляют собой ограничительные коробки для каждой ячейки сетки.
Много типа TD-TSR на частично граничащих таблицах
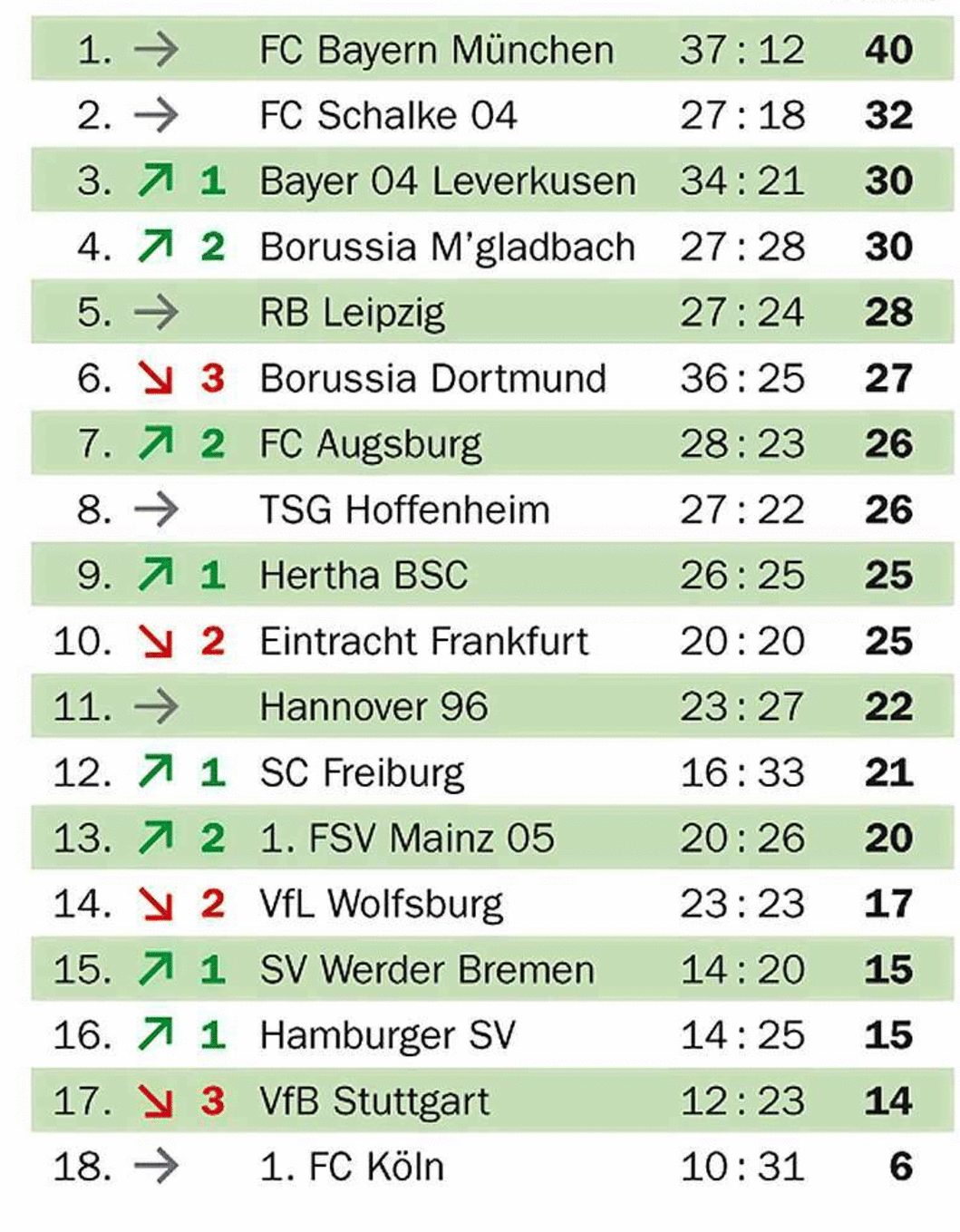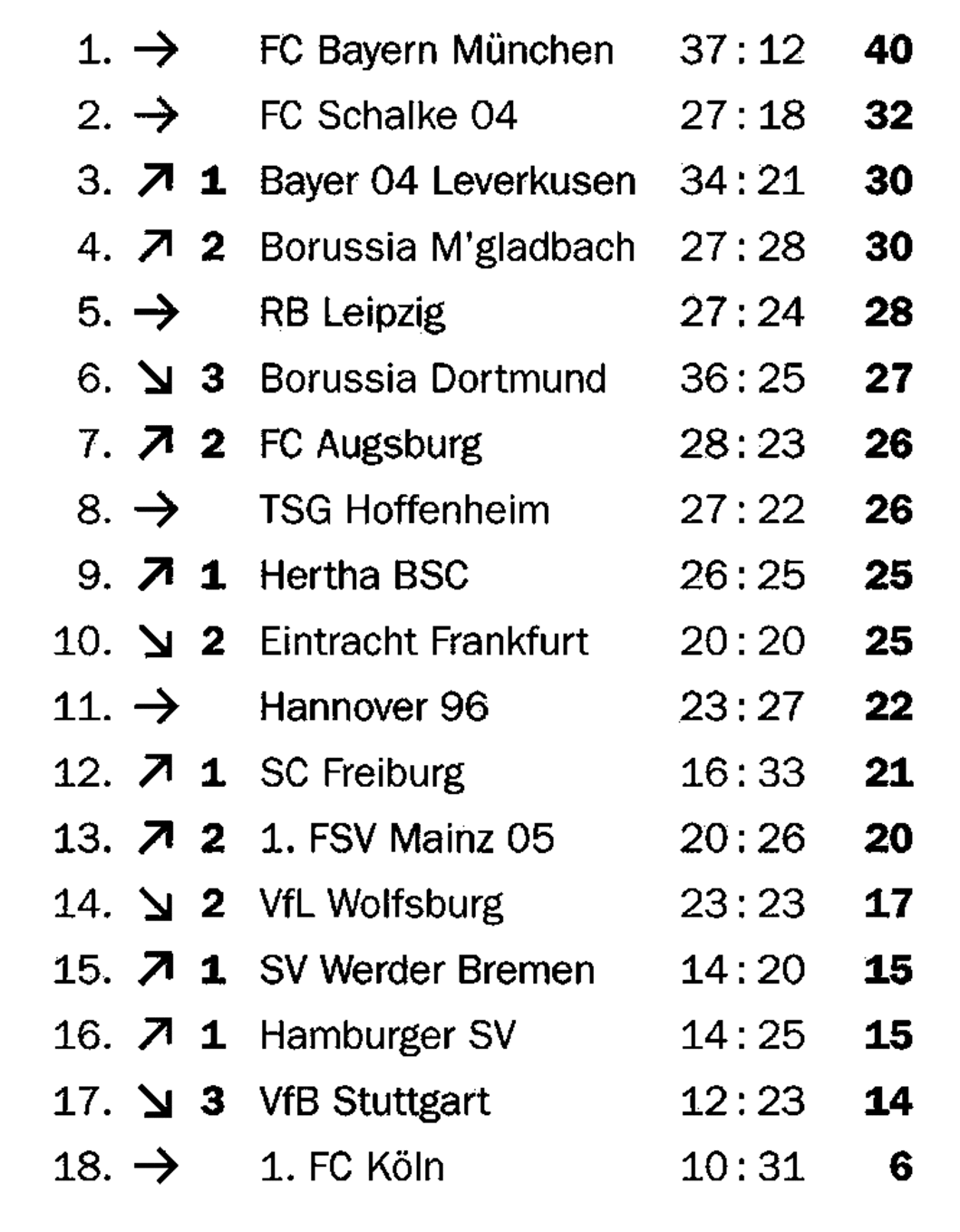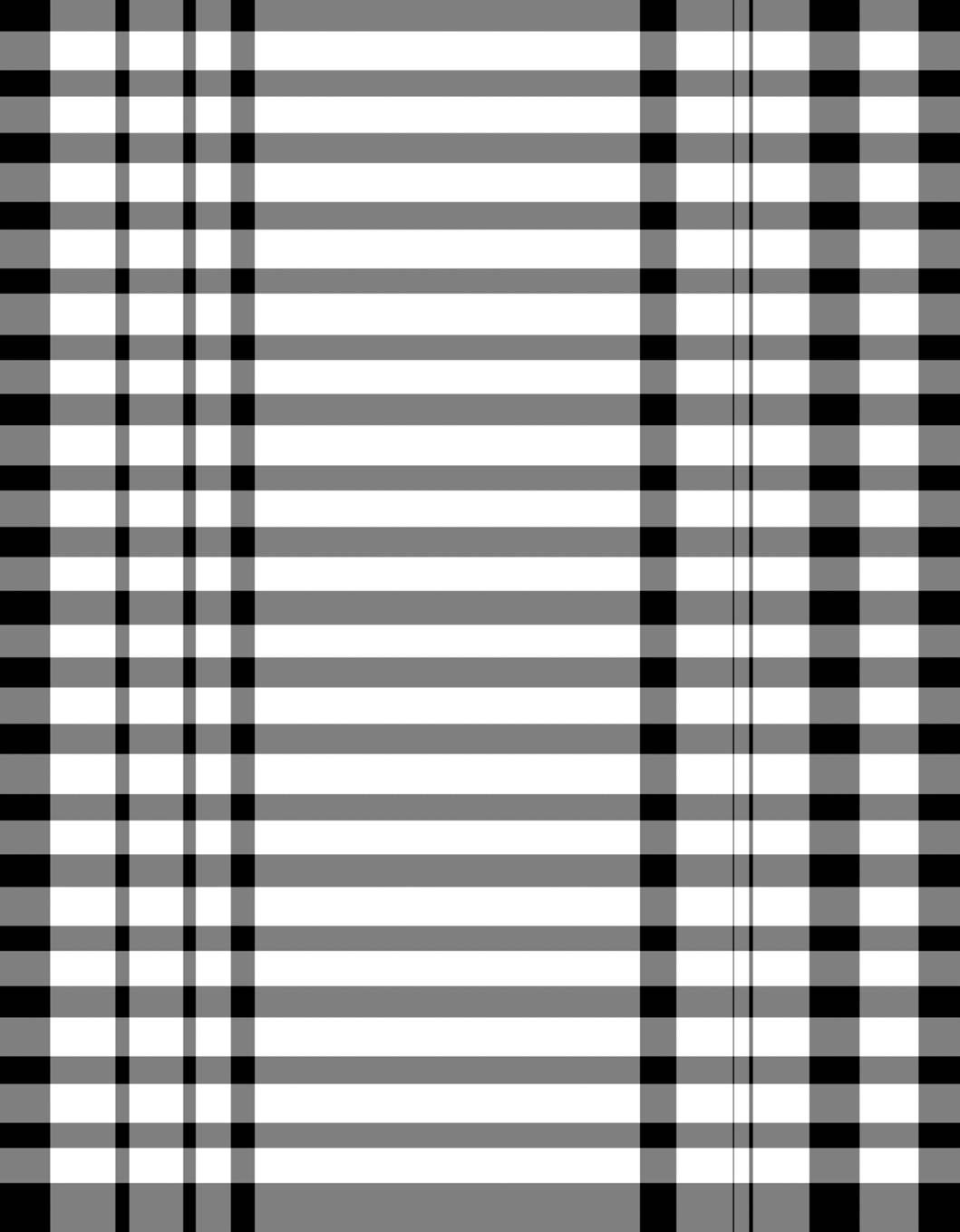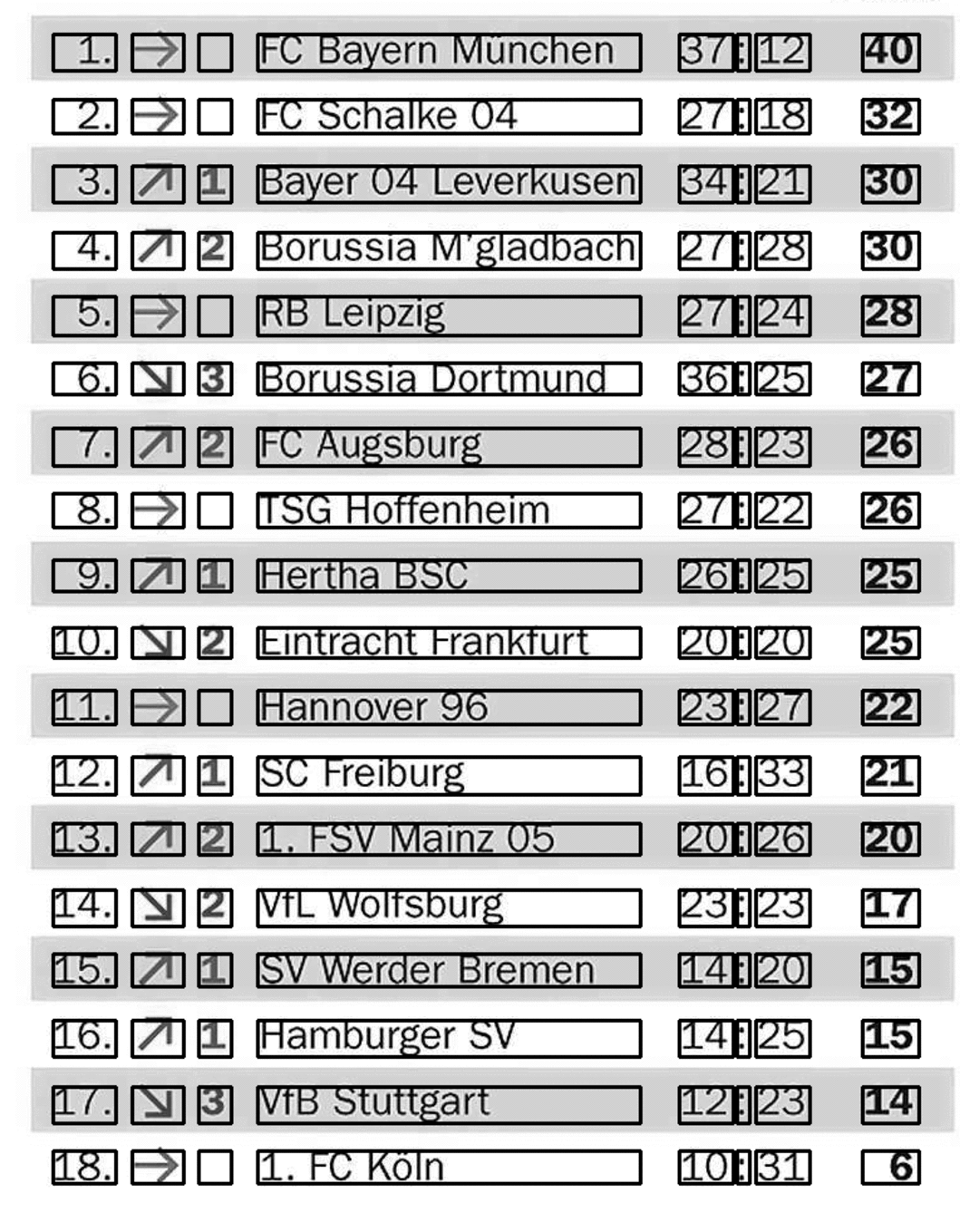
Основной целью наших алгоритмов для граничащих и невозроченных таблиц является создание изображения ячейки сетки путем добавления границ в невозможном корпусе и обнаружения линий в гранитованном случае. Если таблица только частично граничит, то обезболиваемый алгоритм предотвращается добавлять границы в ортогональном направлении к существующим границам, в то время как граничный алгоритм может найти только существующие границы. Оба подхода приводят к неполным изображениям ячейки сетки.
TSR для частично граничащих таблиц использует тот же алгоритм эрозии, что и в граничащих таблицах для обнаружения существующих границ, но без использования их для создания ячейки сетки, но для удаления границ из изображения таблицы, чтобы получить банкновую таблицу. Это позволяет применять алгоритм для невозгорелых таблиц для создания изображения и контуров сетки по аналогии с вариантами, обсуждаемыми выше. Ключевой особенностью этого подхода является то, что он работает как с граничащими, так и с невозможными таблицами: он не зависит от типа.
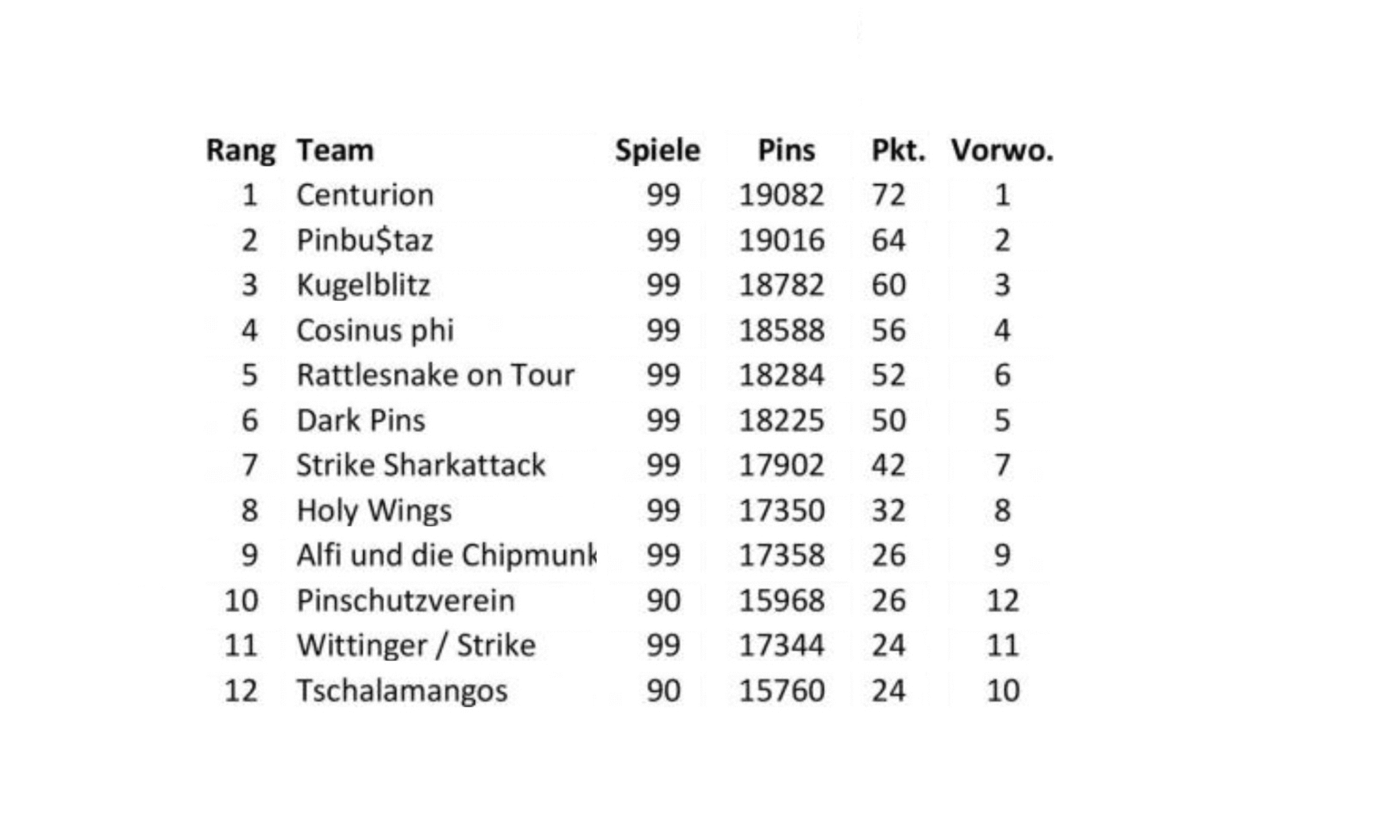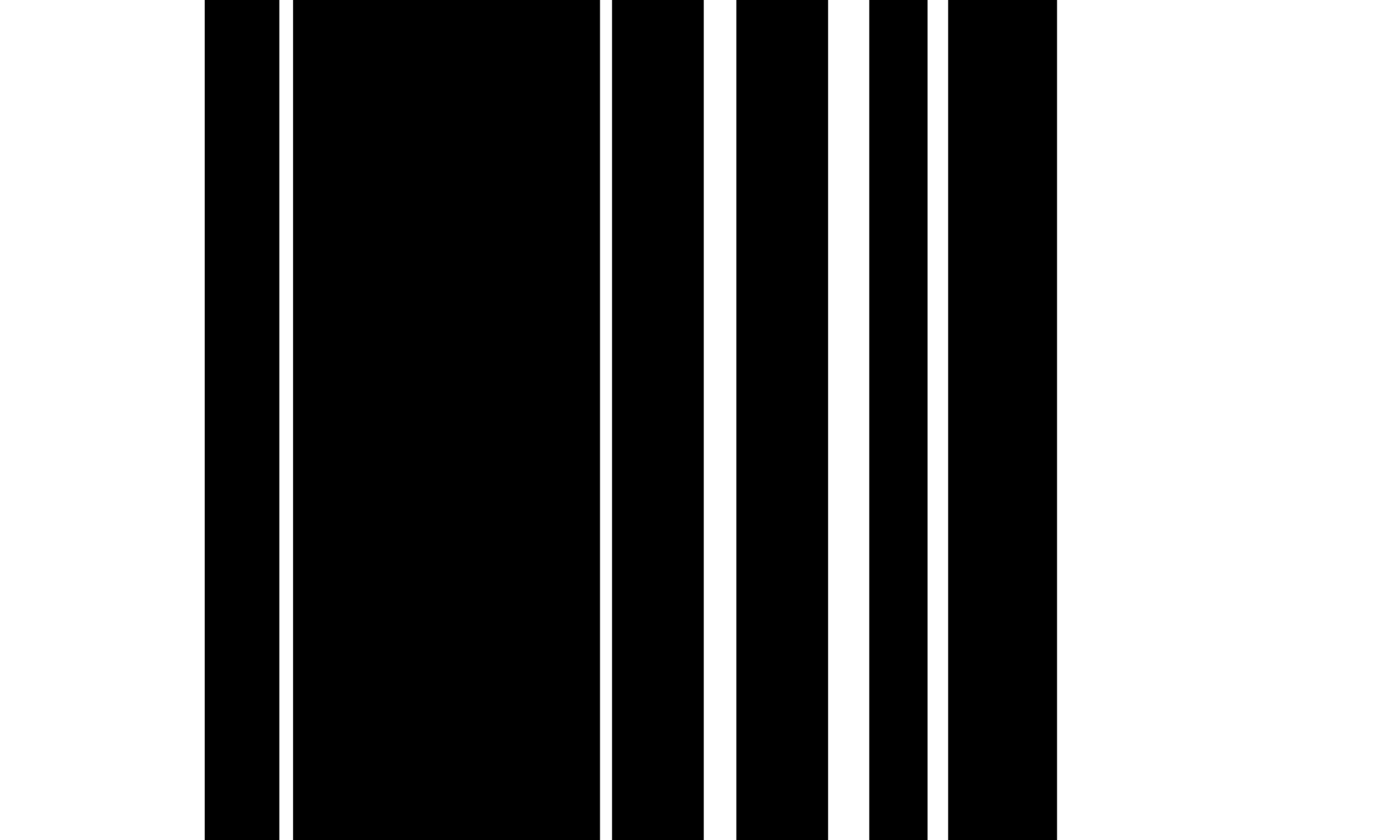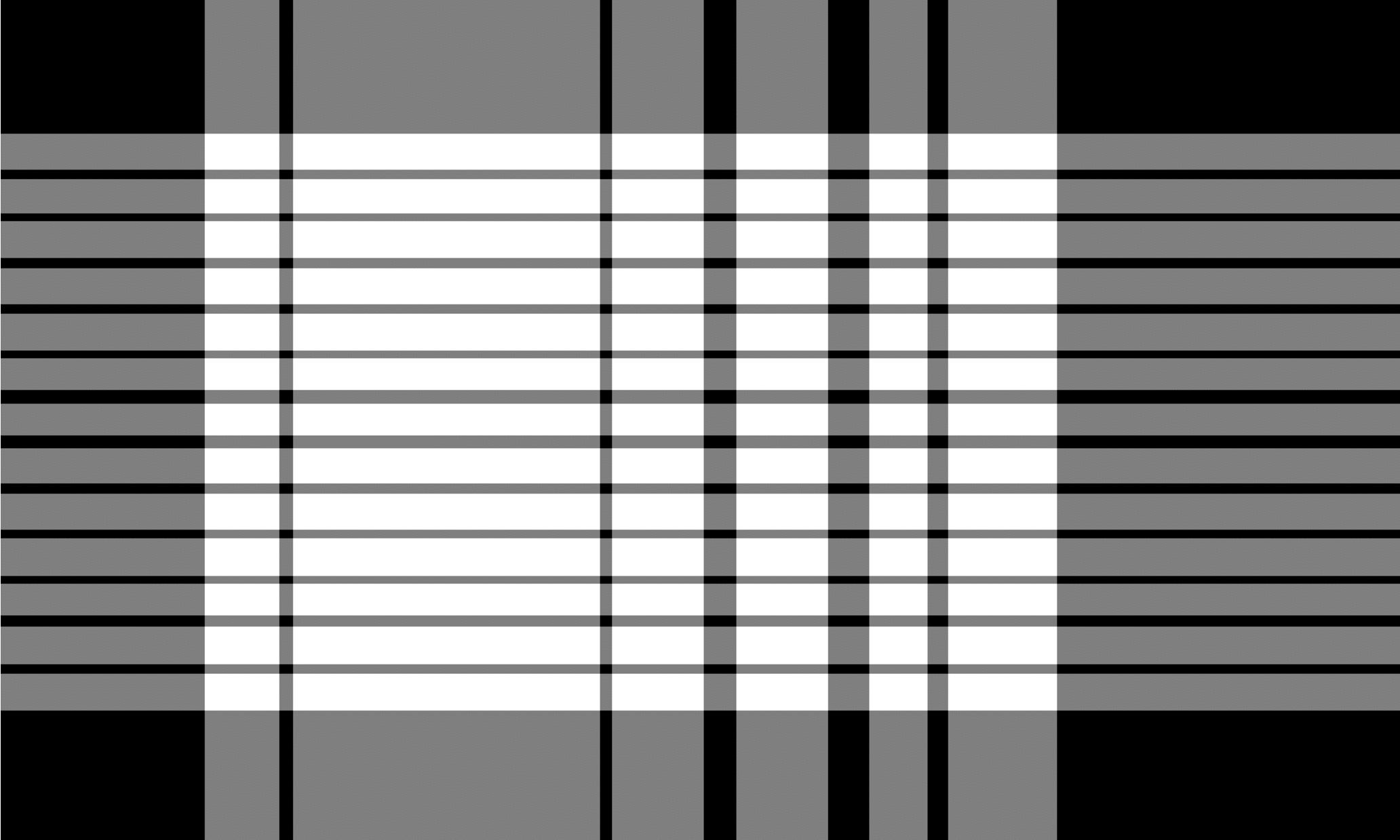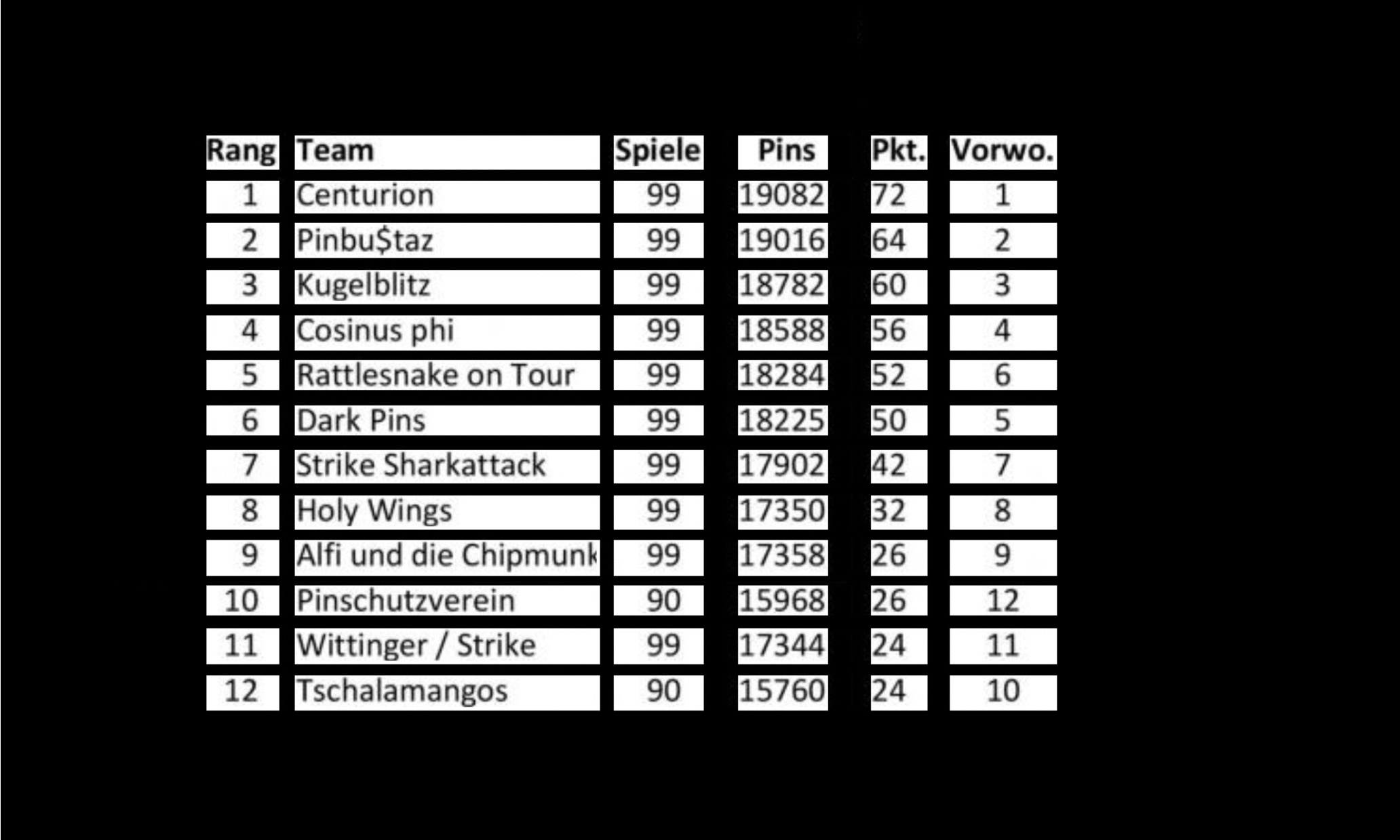
Результаты распознавания структуры таблицы
ICDAR 19 (трек B2)
| Iou | Iou | Iou | Iou | Взвешен |
|---|
| Команда | 0,6 | 0,7 | 0,8 | 0,9 | Средний |
| Cascadetabnet | 0,438 | 0,354 | 0,19 | 0,036 | 0,232 |
| NLPR-PAL | 0,365 | 0,305 | 0,195 | 0,035 | 0,206 |
| Многоподобный TD-TSR | 0,589 | 0,404 | 0,137 | 0,015 | 0,253 |
Инструкции
Конфигурации
Исходный код разработан в соответствии с следующими библиотечными зависимостями
- Pytorch = 1,7,0
- TOCHVISION = 0,8,1
- Cuda = 10,1
- Pyyaml = 5,1
ДЕТЕКТРН 2
Модель обнаружения таблицы основана на Detectron2, следуйте этому руководству по установке для настройки.
Предварительная обработка выравнивания изображений
Для шага предварительной обработки выравнивания изображения есть один сценарий:
Чтобы применить алгоритм предварительной обработки выравнивания изображения ко всем изображениям в одной папке, вам нужно выполнить:
со следующими параметрами
-
--folder входной папки, включая изображения документов -
--output вывода выходной папки для изображений Deskewed
Распознавание структуры таблицы (TSR)
Для распознавания структуры таблицы мы предлагаем простой сценарий для разных подходов
Чтобы применить алгоритм распознавания структуры таблицы ко всем изображениям в одной папке, вам нужно выполнить:
со следующими параметрами
-
--folder в входной папке, включая изображения таблиц -
--type type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--img_output выходной папки для обработанных изображений -
--xml_output выходной папки для файлов XML, включая ограничительные поля
Обнаружение таблицы и распознавание структуры таблицы (TD & TSR)
Чтобы привлечь обнаружение таблицы с использованием сопоставления структуры таблицы
Чтобы применить алгоритм распознавания структуры таблицы ко всем изображениям в одной папке, вам нужно выполнить:
со следующими параметрами
-
--folder в входной папке, включая изображения таблиц -
--type type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--tsr_img_output выходной папки для обработанных таблиц изображений -
--td_img_output POALPER POALPER для вырезанных таблиц. -
--xml_output выходной папки -
--config путь файла конфигурации Detectron2 для обнаружения таблицы -
--yaml пух файла detectron2 yaml для обнаружения таблицы -
--weights веса веса модели Detectron2 для обнаружения таблиц
Оценка
Чтобы оценить алгоритм распознавания структуры таблицы, мы предоставляем следующий сценарий:
Чтобы применить оценку, изображения таблиц и их метки в XML-формате должны быть тем же именем и должны лежать в одной папке. Оценка может быть начата с помощью:
со следующим параметром
-
--dataset DataSet Palp, содержащий табличные изображения и метки в формате .xml
Получите данные
- Набор данных тестирования для распознавания структуры таблицы, включая таблицы и аннотации, можно загрузить здесь
- Обнаружение таблицы Detectron2 Веса модели и файлы конфигурации могут быть загружены здесь
Цитирование
@misc{fischer2021multitypetdtsr,
title={Multi-Type-TD-TSR - Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations},
author={Pascal Fischer and Alen Smajic and Alexander Mehler and Giuseppe Abrami},
year={2021},
eprint={2105.11021},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


