Multi-types-td-tsr
Vérifiez-le sur le code source de notre article: Tables d'extraction de TD-TD-TD-TD-TDSR à partir d'images de document à l'aide d'un pipeline à plusieurs étapes pour la détection de table et la reconnaissance de la structure du tableau
Description
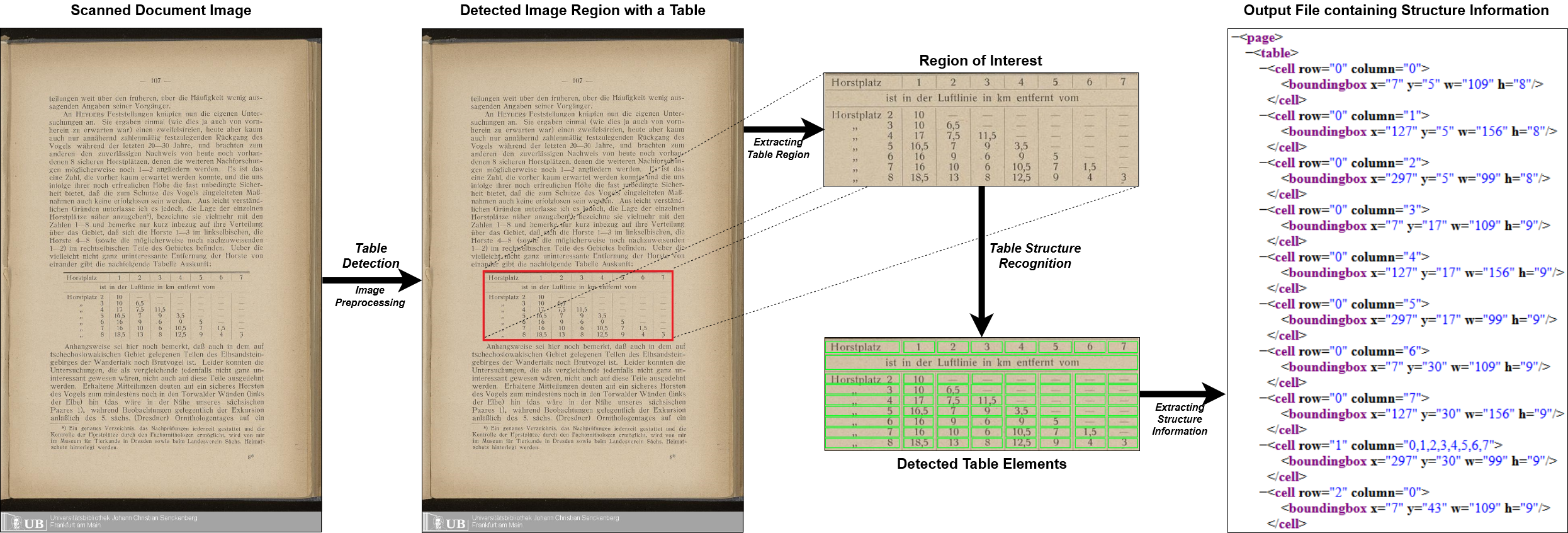
Multi-types-td-tsr tout le pipeline
Alors que les tendances mondiales se déplacent vers les industries basées sur les données, la demande d'algorithmes automatisés qui peuvent convertir des images numériques de documents numérisés en informations lisibles par la machine se développe rapidement. Outre la possibilité de numérisation des données pour l'application d'outils d'analyse de données, il existe également une amélioration massive de l'automatisation des processus, qui nécessiterait auparavant une inspection manuelle des documents. Bien que l'introduction des technologies de reconnaissance des caractères optiques (OCR) ait principalement résolu la tâche de convertir des caractères lisibles par l'homme à partir d'images en caractères lisibles par la machine, la tâche d'extraire la sémantique de table a été moins axée sur les années. La reconnaissance des tables se compose de deux tâches principales, à savoir la détection de table et la reconnaissance de la structure de la table. La plupart des travaux antérieurs sur ce problème se concentrent sur la tâche sans offrir une solution de bout en bout ou en faisant attention à des conditions d'application réelles telles que des images rotatives ou des artefacts de bruit à l'intérieur de l'image du document. Des travaux récents montrent une tendance claire vers les approches d'apprentissage en profondeur couplées à l'utilisation de l'apprentissage du transfert pour la tâche de reconnaissance de la structure de la table en raison du manque d'ensembles de données suffisamment importants. Dans cet article, nous présentons un pipeline à plusieurs étapes nommé Multi-Type-TD-TSR, qui offre une solution de bout en bout pour le problème de la reconnaissance de la table. Il utilise des modèles d'apprentissage en profondeur de pointe pour la détection de table et différencie 3 types de tableaux différents en fonction des bordures des tableaux. Pour la reconnaissance de la structure du tableau, nous utilisons un algorithme déterministe non entraîné par les données, qui fonctionne sur tous les types de table. Nous présentons également deux algorithmes. Un pour les tables non conformes et une pour les tables bordées, qui sont la base de l'algorithme de reconnaissance de la structure de la table utilisée. Nous évaluons le TD-TD-TD-TD-TD-TDS sur le jeu de données de reconnaissance de la structure de table ICDAR 2019 et réalisons un nouveau de pointe.
Multi-types-td-tsr sur des tables entièrement bordées
Pour TSR sur les tables entièrement bordées, nous utilisons l'opération d'érosion et de dilatation pour extraire l'image de cellule de grille de colonne de ligne sans aucun texte ni caractères. Les grains d'érosion sont généralement minces verticales et horizontales qui sont plus longues que la taille globale de la police mais plus courtes que la taille de la plus petite cellule de grille et, en particulier, ne doivent pas être plus larges que la plus petite largeur de bordure de table. L'utilisation de ces contraintes de taille du noyau entraîne l'opération d'érosion en supprimant toutes les polices et caractères de la table tout en préservant les bordures de la table. Afin de restaurer la forme de ligne d'origine, l'algorithme applique l'opération de dilatation en utilisant la même taille du noyau sur chacune des deux images érodées, produisant une image avec verticale et une seconde avec des lignes horizontales. Enfin, l'algorithme combine les deux images en utilisant un fonctionnement `` `` ou '' du bit-sage et en réinversant les valeurs de pixels pour obtenir une image de cellule raster. Nous utilisons ensuite la fonction Contours sur l'image de la grille pour extraire les boîtes à délimitation pour chaque cellule de grille.
Multi-types-TD-TSR sur des tables non conformes
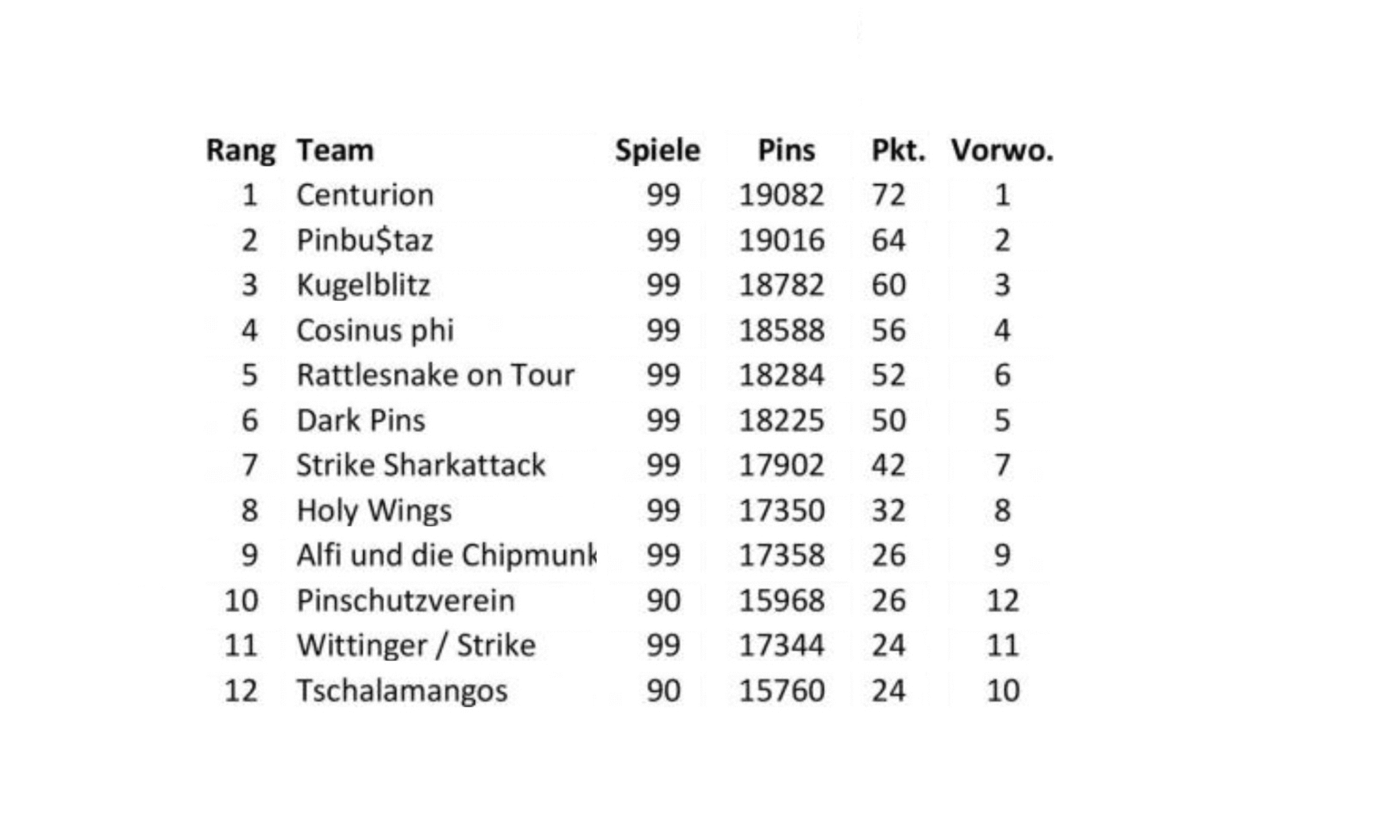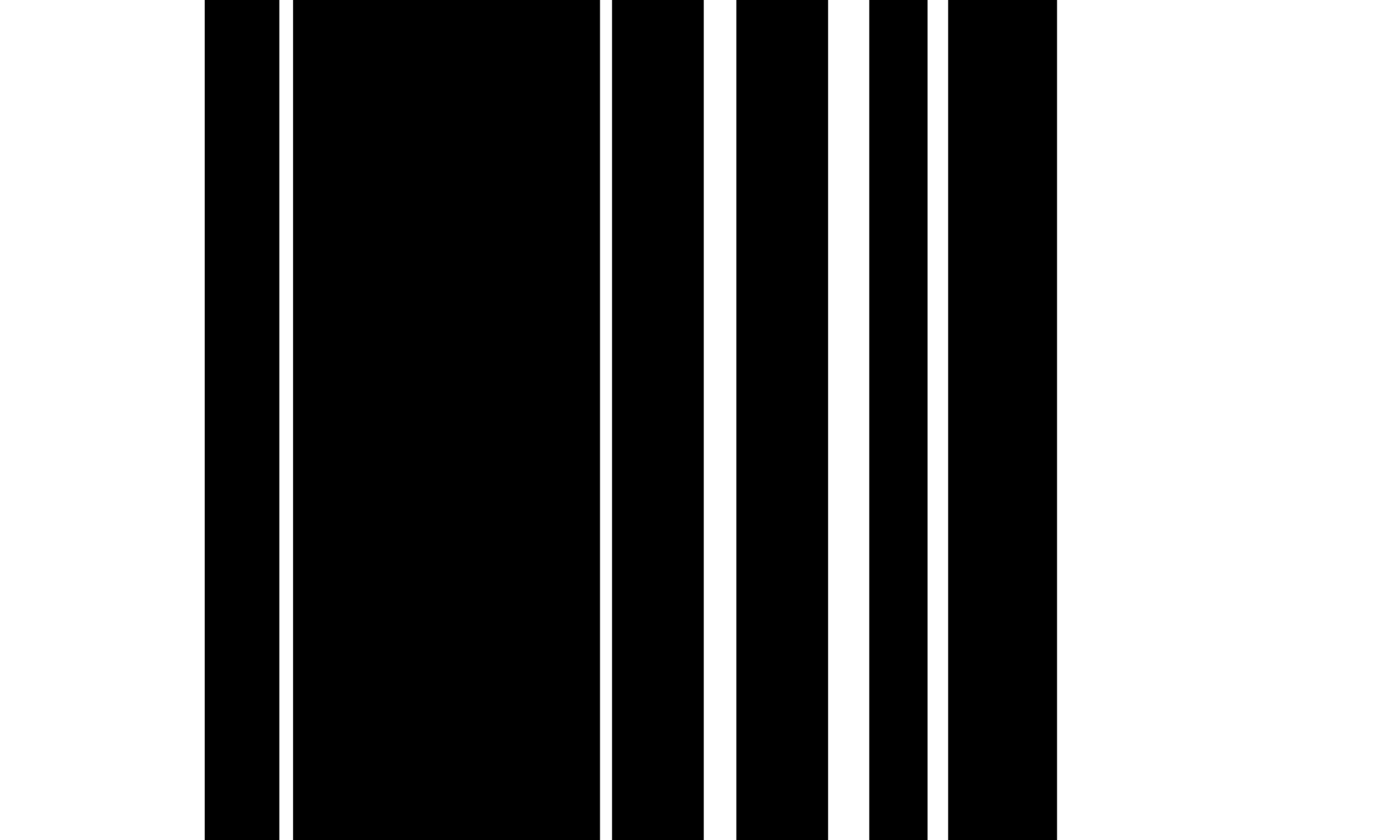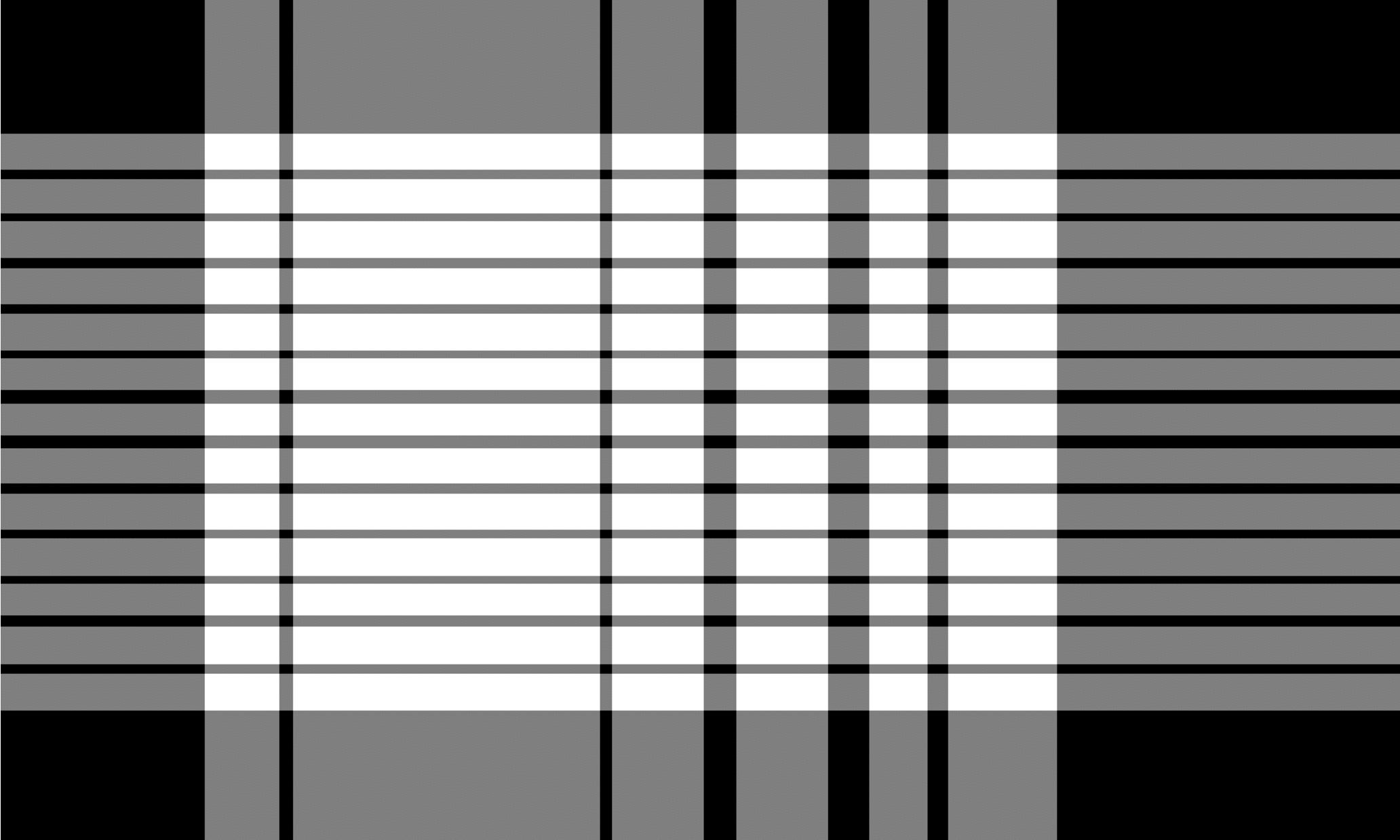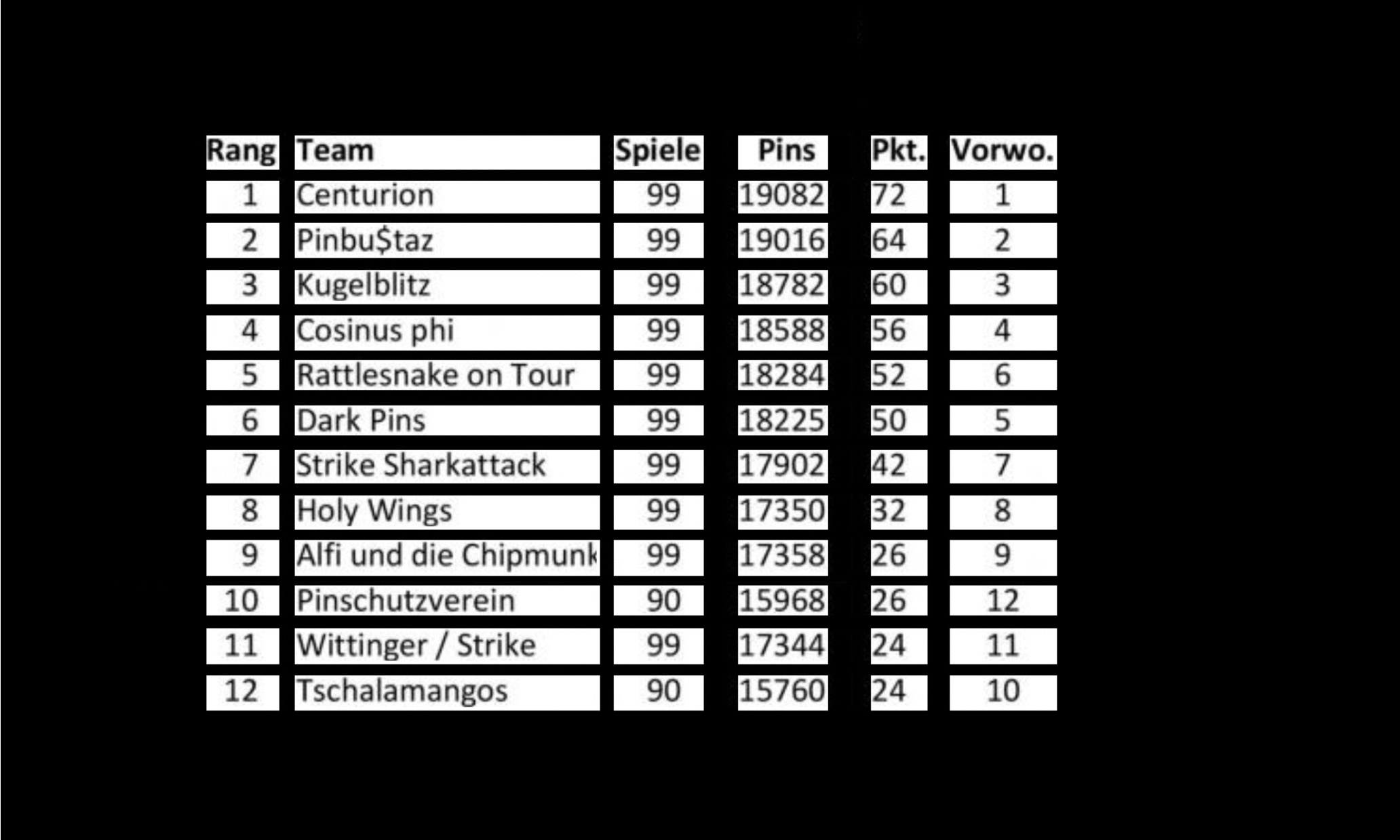
L'algorithme TSR pour les tables non conformes fonctionne de manière similaire à celle des tables bordées mais utilise l'opération d'érosion d'une manière différente. Le noyau d'érosion est en général une mince bande avec la différence que la taille horizontale du noyau horizontal comprend la largeur d'image complète et la taille verticale du noyau vertical la hauteur de l'image complète. L'algorithme glisse les deux noyaux indépendamment sur toute l'image de gauche à droite pour le noyau vertical, et de haut en bas pour le noyau horizontal. Au cours de ce processus, il recherche des lignes et des colonnes vides qui ne contiennent aucun caractères ou police. Les images résultantes sont inversées et combinées par une opération `` et '' bit-sage, produisant la sortie finale. La sortie est une image de cellule de grille similaire à celle de TSR pour les tables bordées, où les zones qui se chevauchent des deux images résultantes représentent les boîtes à délimitation pour chaque cellule de grille.
Multi-types-TD-TSR sur des tables partiellement bordées
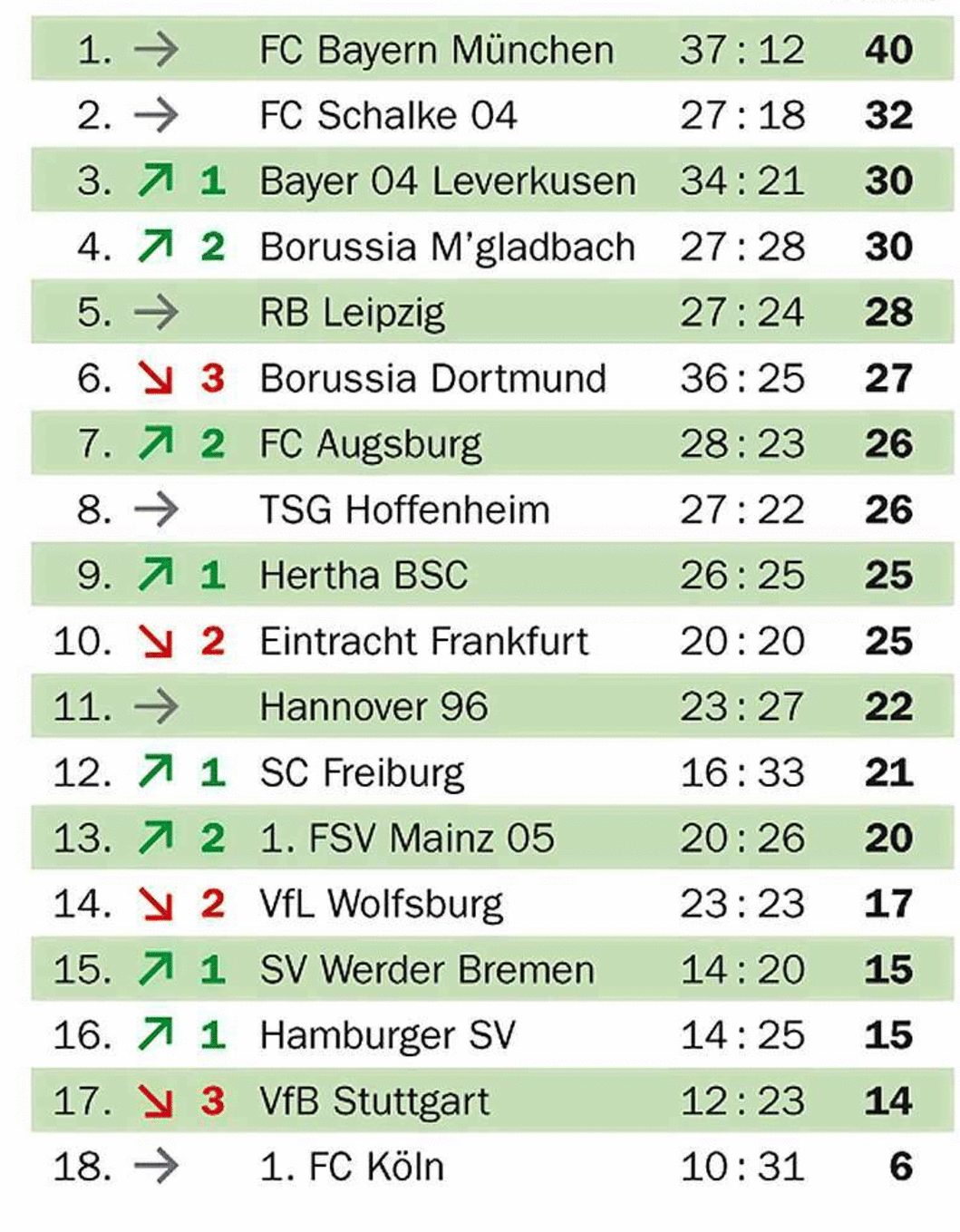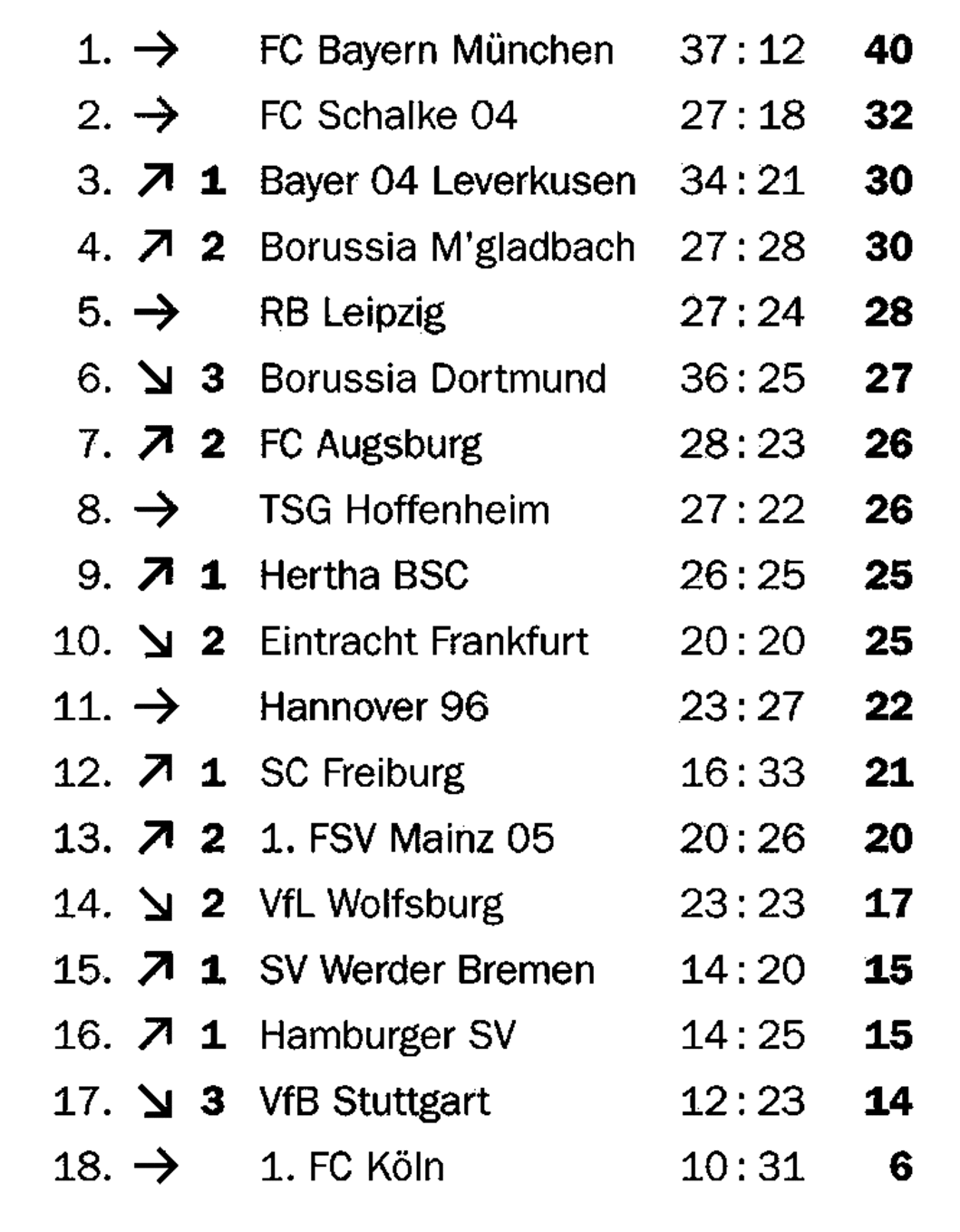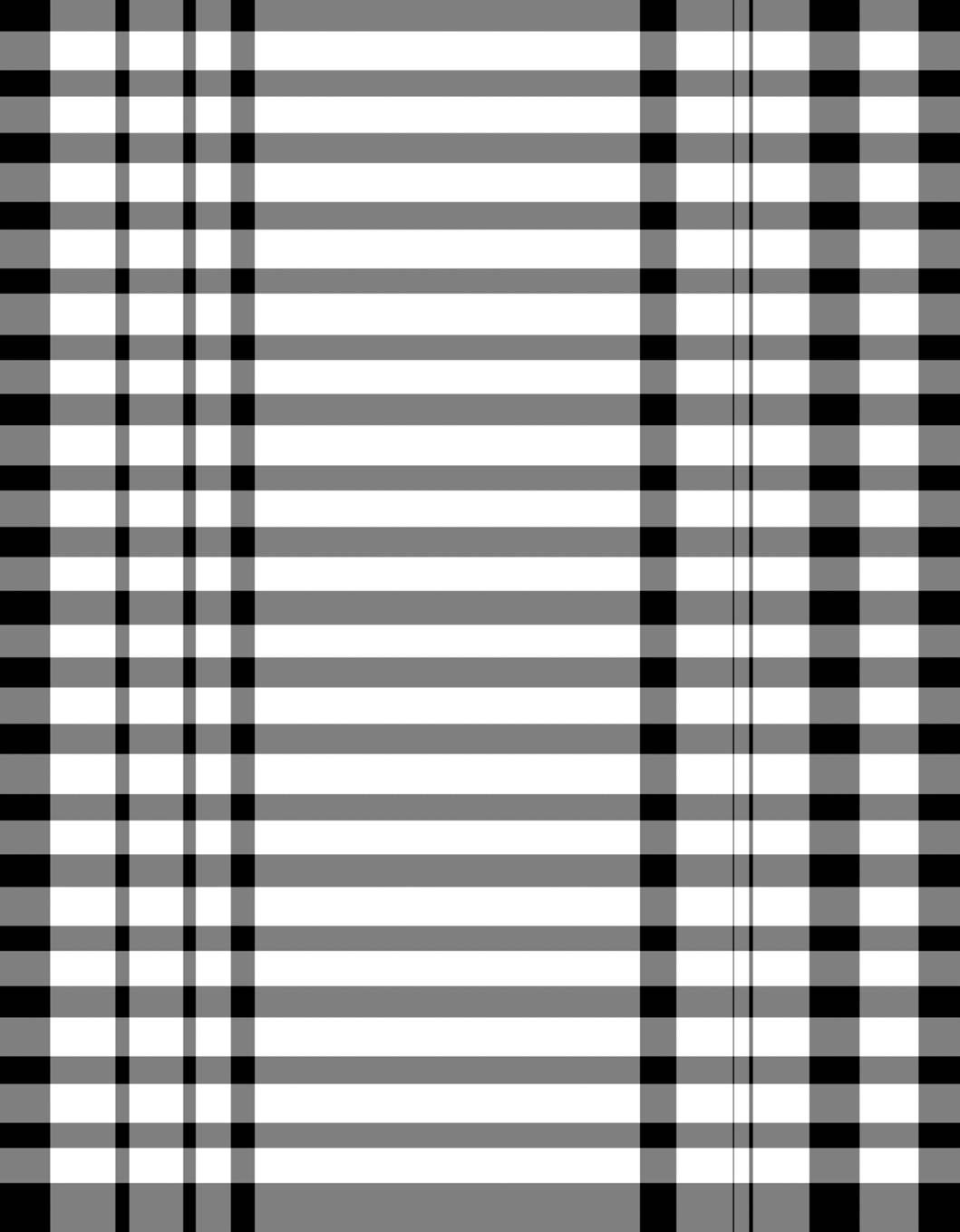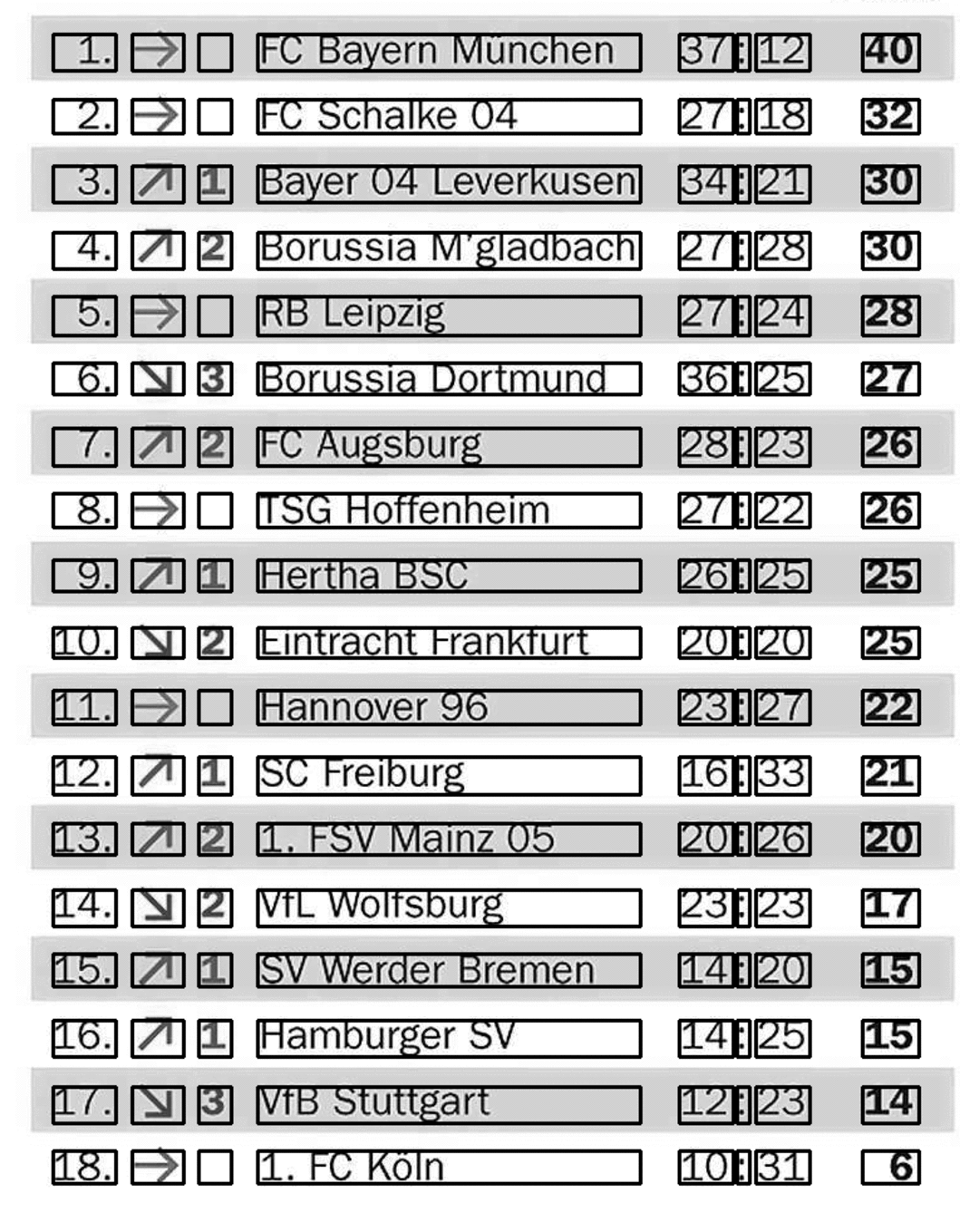
L'objectif principal de nos algorithmes pour les tables bordées et non conformes est de créer une image de cellule de grille en ajoutant des frontières dans le cas non conformément et en détectant les lignes dans le cas bordé. Si une table n'est que partiellement bordée, l'algorithme non conforme est empêché d'ajouter des frontières dans la direction orthogonale aux bordures existantes, tandis que l'algorithme bordé ne peut trouver que les frontières existantes. Les deux approches entraînent des images de cellules de grille incomplètes.
TSR pour les tables partiellement bordées utilise le même algorithme d'érosion que dans les tables bordées pour détecter les bordures existantes, mais sans les utiliser pour créer une cellule de grille, mais pour supprimer les frontières de l'image de la table pour obtenir une table non conforme. Cela permet d'appliquer l'algorithme pour les tables non conformes pour créer l'image et les contours des cellules de grille par analogie avec les variantes discutées ci-dessus. Une caractéristique clé de cette approche est qu'elle fonctionne avec des tables à la fois bordées et non conformes: elle est indépendante du type.
Résultats de reconnaissance de la structure de table
ICDAR 19 (piste B2)
| Iou | Iou | Iou | Iou | Pondéré |
|---|
| Équipe | 0.6 | 0.7 | 0.8 | 0.9 | Moyenne |
| Cascadetabnet | 0,438 | 0,354 | 0,19 | 0,036 | 0,232 |
| NLPR-PAL | 0,365 | 0,305 | 0.195 | 0,035 | 0,206 |
| Multi-types-td-tsr | 0,589 | 0,404 | 0,137 | 0,015 | 0,253 |
Instructions
Configurations
Le code source est développé dans les dépendances de bibliothèque suivantes
- Pytorch = 1,7,0
- TorchVision = 0,8.1
- Cuda = 10,1
- Pyyaml = 5,1
DÉTECTRON 2
Le modèle de détection de table est basé sur Detectron2 Suivez ce guide d'installation de la configuration.
Alignement d'image Pré-traitement
Pour l'étape de prétraitement de l'alignement de l'image, il y a un script disponible:
Pour appliquer l'algorithme de prétraitement d'alignement de l'image à toutes les images d'un dossier, vous devez exécuter:
avec les paramètres suivants
-
--folder le dossier d'entrée, y compris les images de documents -
--output le dossier de sortie pour les images deskewed
Reconnaissance de la structure du tableau (TSR)
Pour la reconnaissance de la structure du tableau, nous proposons un script simple pour différentes approches
Pour appliquer un algorithme de reconnaissance de structure de table à toutes les images dans un dossier, vous devez exécuter:
avec les paramètres suivants
-
--folder Chemin de fracture du dossier d'entrée, y compris les images de table -
--type de type de reconnaissance de la structure de table type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--img_output Chemin de dossier de sortie pour les images traitées -
--xml_output Tath du dossier de sortie pour les fichiers XML, y compris les boîtes de délimitation
Détection de table et reconnaissance de la structure du tableau (TD & TSR)
Pour appuyer la détection de la table avec une structure de table suivie de reconnaissance
Pour appliquer un algorithme de reconnaissance de structure de table à toutes les images dans un dossier, vous devez exécuter:
avec les paramètres suivants
-
--folder Chemin de fracture du dossier d'entrée, y compris les images de table -
--type de type de reconnaissance de la structure de table type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--tsr_img_output PATAINE DE FORD DE SORTIE POUR LES IMAGES DE TABLE traitée -
--td_img_output PATAINE DE FORD DE SORTIE POUR LES COUVERSES DE TABLE PRODUITES -
--xml_output Path de dossier de sortie pour les fichiers XML pour les tables et les cellules, y compris les boîtes de délimitation -
--config du chemin du fichier de configuration Detectron2 pour la détection de table -
--yaml d'eux du fichier yaml de détectron2 pour détection de table -
--weights Chemin de poids des poids du modèle Detectron2 pour la détection de table
Évaluation
Pour évaluer l'algorithme de reconnaissance de la structure de la table, nous fournissons le script suivant:
Pour appliquer l'évaluation, les images de table et leurs étiquettes en format XML doivent être le même nom et devraient se trouver dans un seul dossier. L'évaluation pourrait être lancée par:
avec le paramètre suivant
-
--dataset DataSet Dataset Chedal contenant des images et des étiquettes de table au format .xml
Obtenir des données
- L'ensemble de données de test pour la reconnaissance de la structure de la table, y compris les images de table et les annotations, peut être téléchargée ici
- Détection de table Detectron2 Les poids et les fichiers de configuration du modèle peuvent être téléchargés ici
Citation
@misc{fischer2021multitypetdtsr,
title={Multi-Type-TD-TSR - Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations},
author={Pascal Fischer and Alen Smajic and Alexander Mehler and Giuseppe Abrami},
year={2021},
eprint={2105.11021},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


