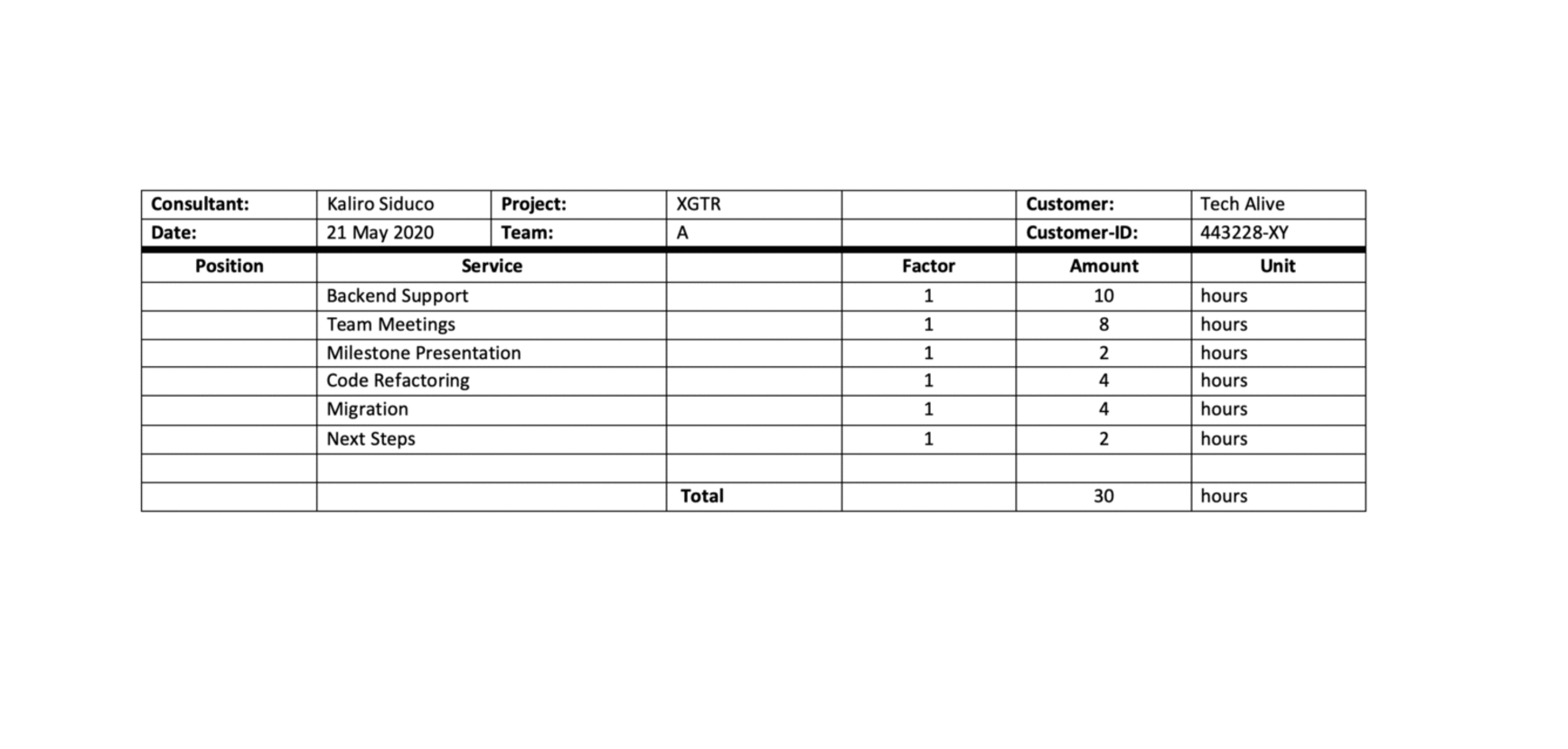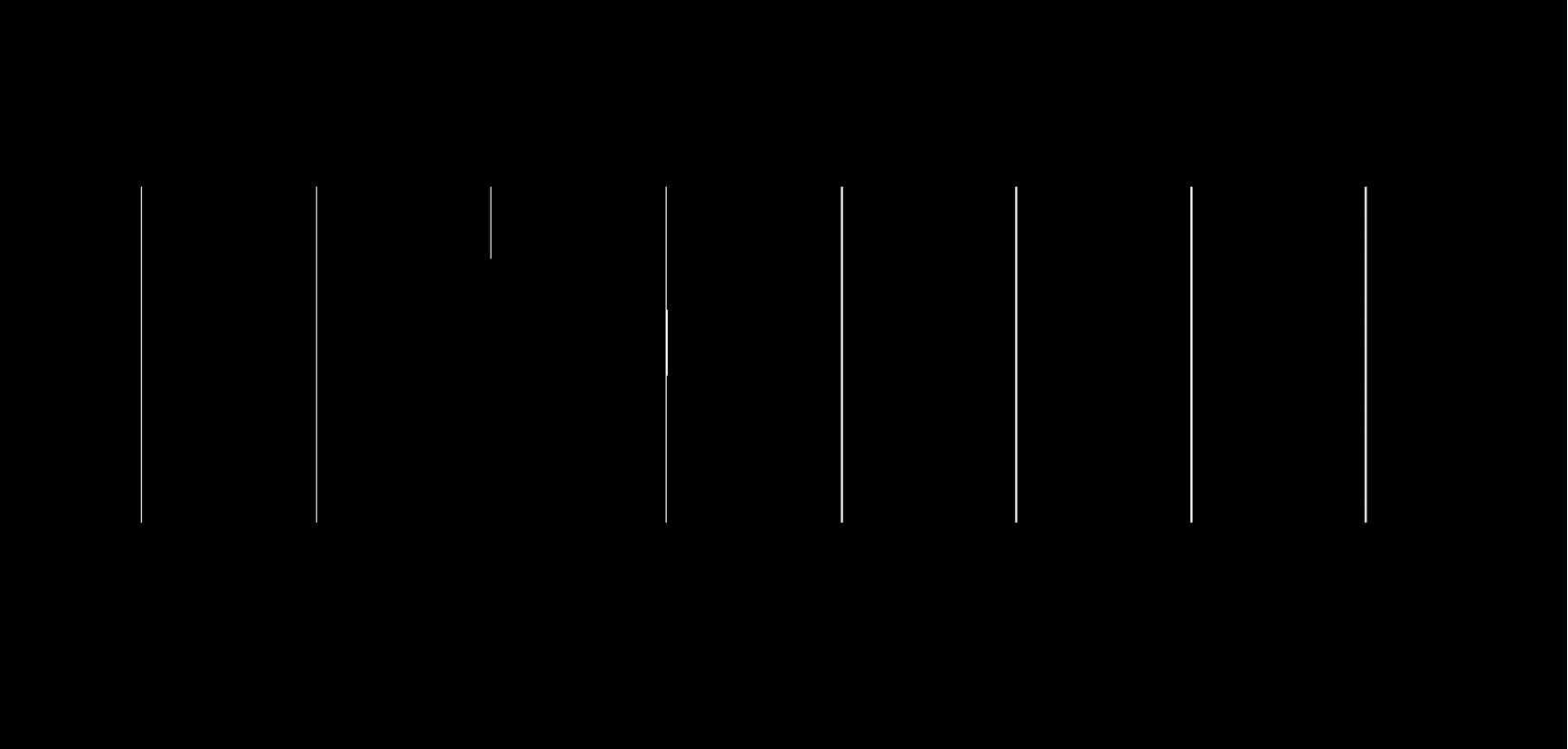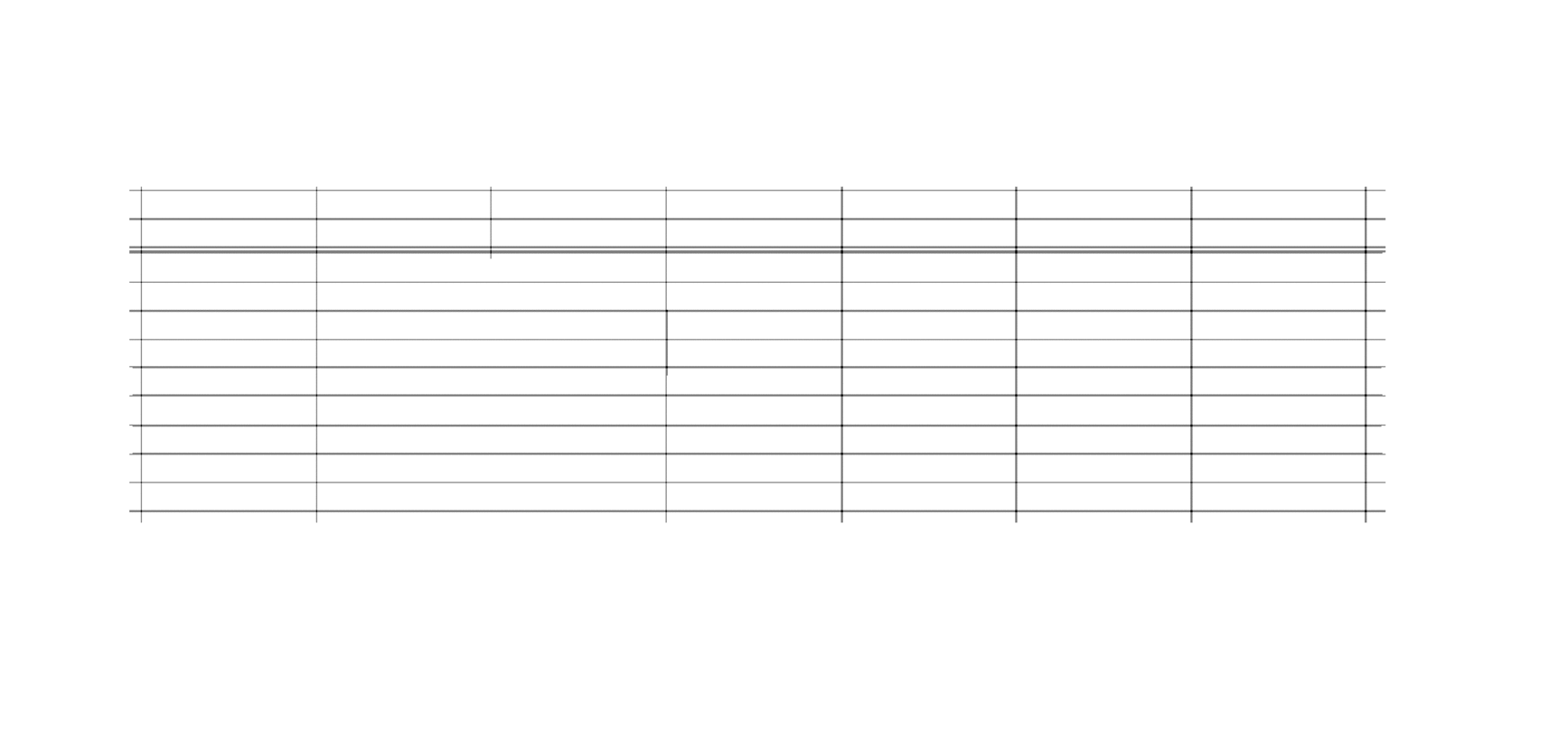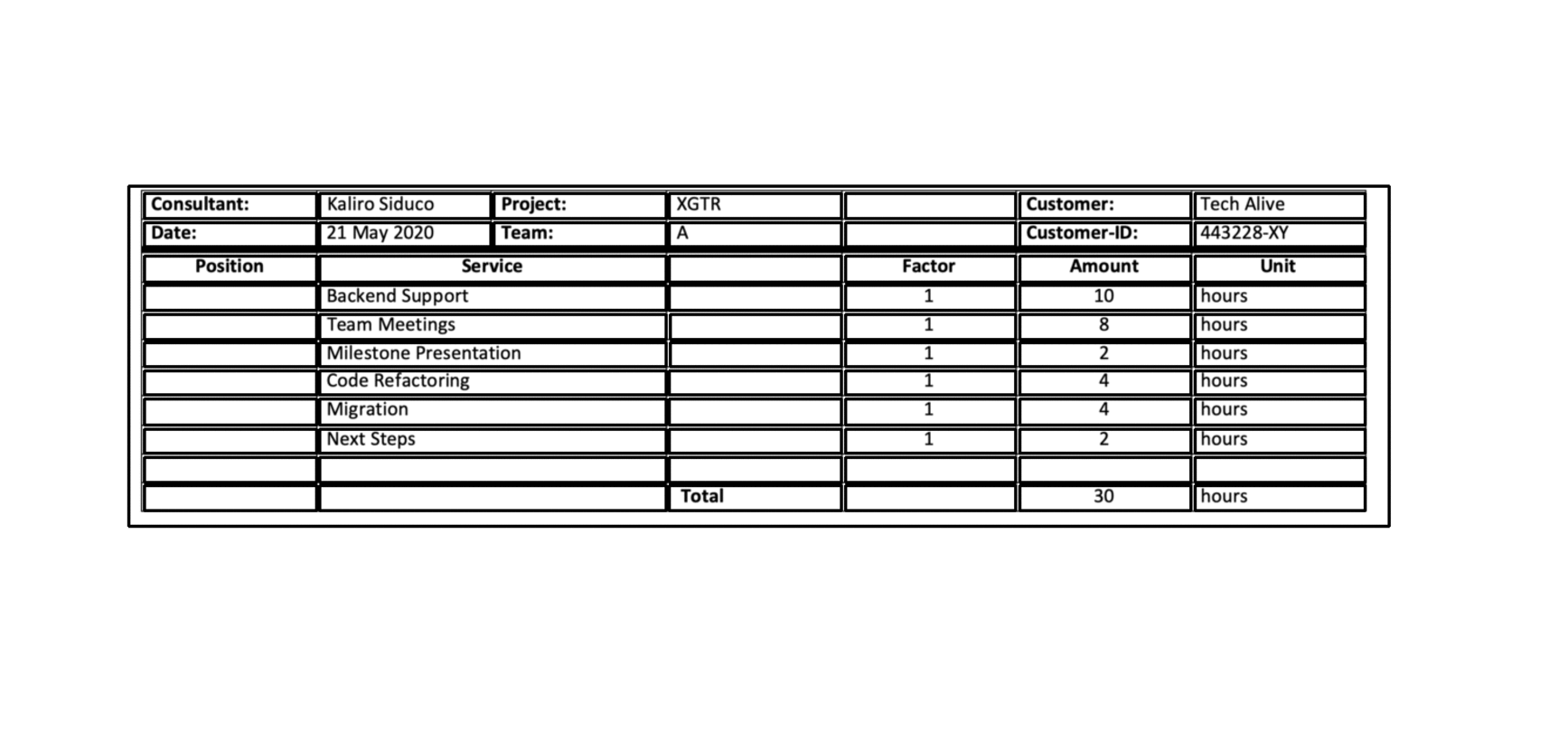
Multi-Typ-TD-TSR
Sehen Sie sich den Quellcode unseres Papiers an: Multi-Typ-TD-TSR-Extrahieren von Tabellen aus Dokumentbildern mit einer mehrstufigen Pipeline zur Erkennung von Tabellenerkennung und Tabellenstruktur
Beschreibung
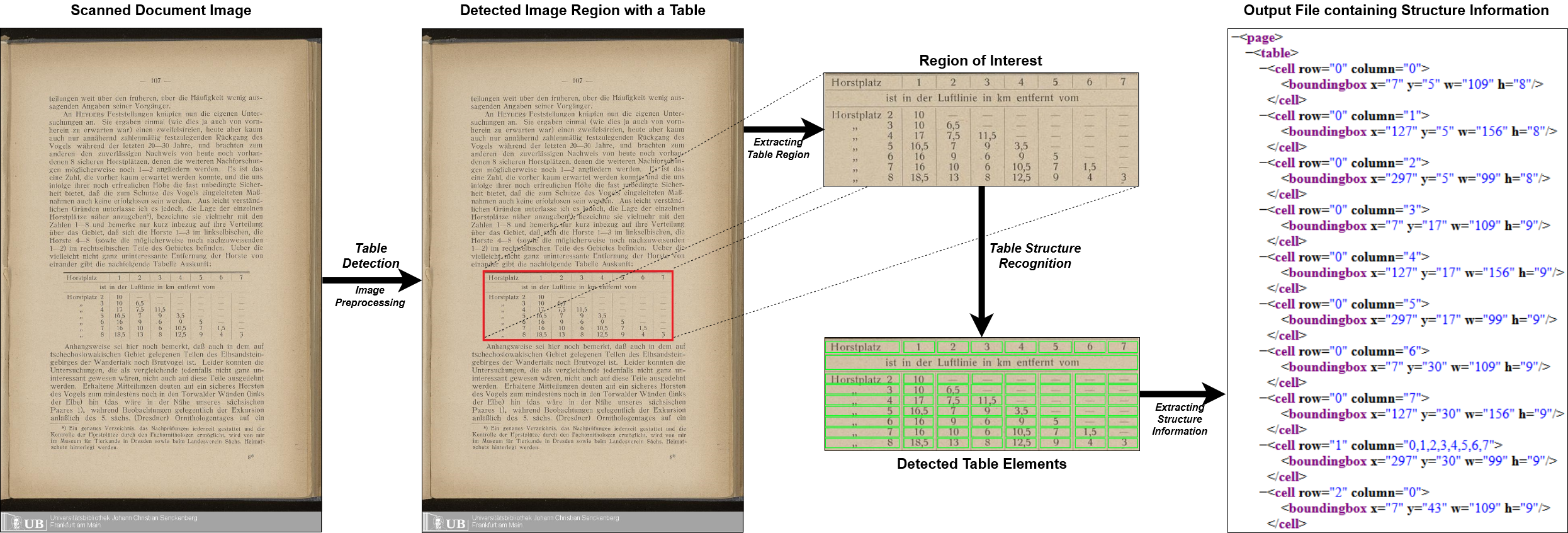
Multi-Typ-TD-TSR Die gesamte Pipeline
Da sich die globalen Trends in Richtung datenorientierter Branchen verlagern, wächst die Nachfrage nach automatisierten Algorithmen, die digitale Bilder von gescannten Dokumenten in maschinenlesbare Informationen umwandeln können. Neben der Möglichkeit der Datendigitalisierung für die Anwendung von Datenanalysewerkzeugen besteht auch eine massive Verbesserung der Automatisierung der Prozesse, die zuvor eine manuelle Inspektion der Dokumente erfordern würde. Obwohl die Einführung der OCR-Technologien (optische Charaktereerkennung) meist die Aufgabe des Umwandlung menschlicher lesbarer Zeichen von Bildern in maschinenlesbare Zeichen löste, war die Aufgabe, die Tabellensemantik zu extrahieren, im Laufe der Jahre weniger konzentriert. Die Erkennung von Tabellen besteht aus zwei Hauptaufgaben, nämlich Tabellenerkennung und Tabellenstrukturerkennung. Die meisten früheren Arbeiten an diesem Problem konzentrieren sich entweder auf die Aufgabe, ohne eine End-to-End-Lösung anzubieten, oder achten Sie auf reale Anwendungsbedingungen wie gedrehte Bilder oder Geräuschartefakte im Dokumentbild. Jüngste Arbeiten zeigen einen klaren Trend zu Deep -Learning -Ansätzen in Verbindung mit der Verwendung von Transferlernen für die Aufgabe der Tabellenstrukturerkennung aufgrund des Mangels an ausreichend großer Datensätze. In diesem Artikel präsentieren wir eine mehrstufige Pipeline mit dem Namen Multi-Typ-TD-TSR, die eine End-to-End-Lösung für das Problem der Tabellenerkennung bietet. Es verwendet hochmoderne Deep-Learning-Modelle für die Tabellenerkennung und unterscheidet zwischen 3 verschiedenen Tabellenarten basierend auf den Grenzen der Tabellen. Für die Erkennung von Tabellenstruktur verwenden wir einen deterministischen nicht-datengesteuerten Algorithmus, der auf allen Tabellentypen funktioniert. Wir präsentieren zusätzlich zwei Algorithmen. Eine für nicht angeordnete Tabellen und eine für umrandete Tabellen, die die Basis des Algorithmus zur Erkennung von Tabellenstruktur sind. Wir bewerten Multi-Typ-TD-TSR im ICDAR 2019-Tabellenstrukturerkennungsdatensatz und erreichen eine neue hochmoderne Art.
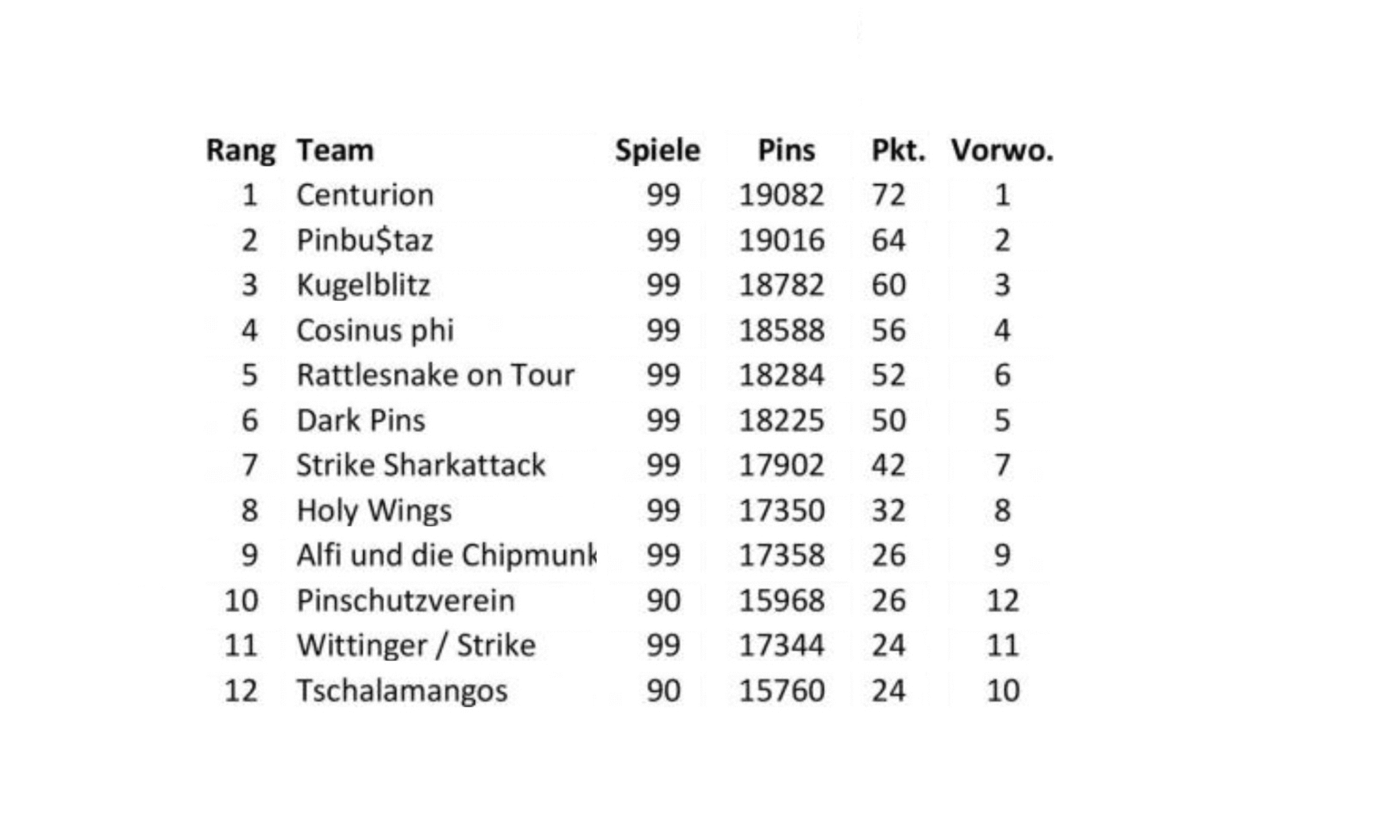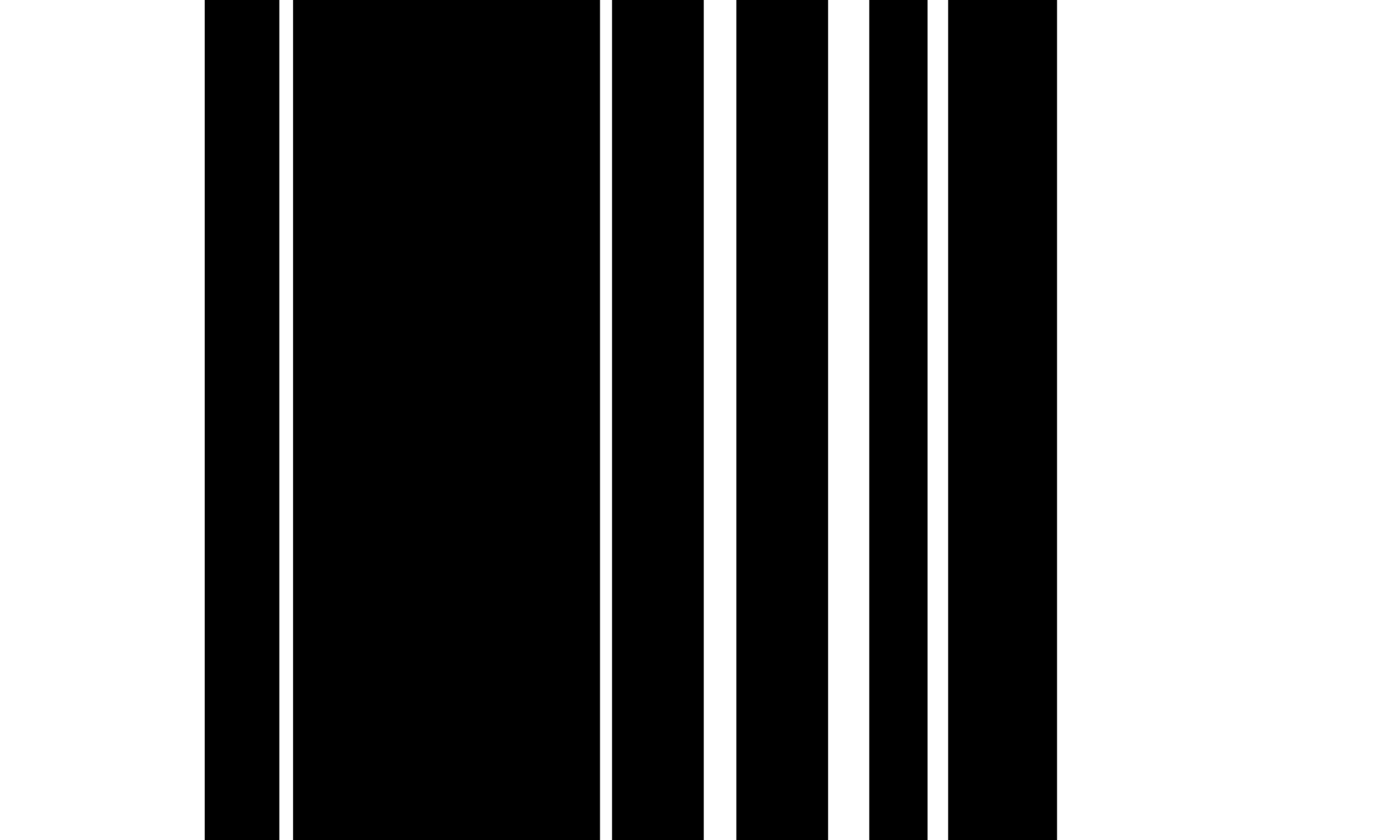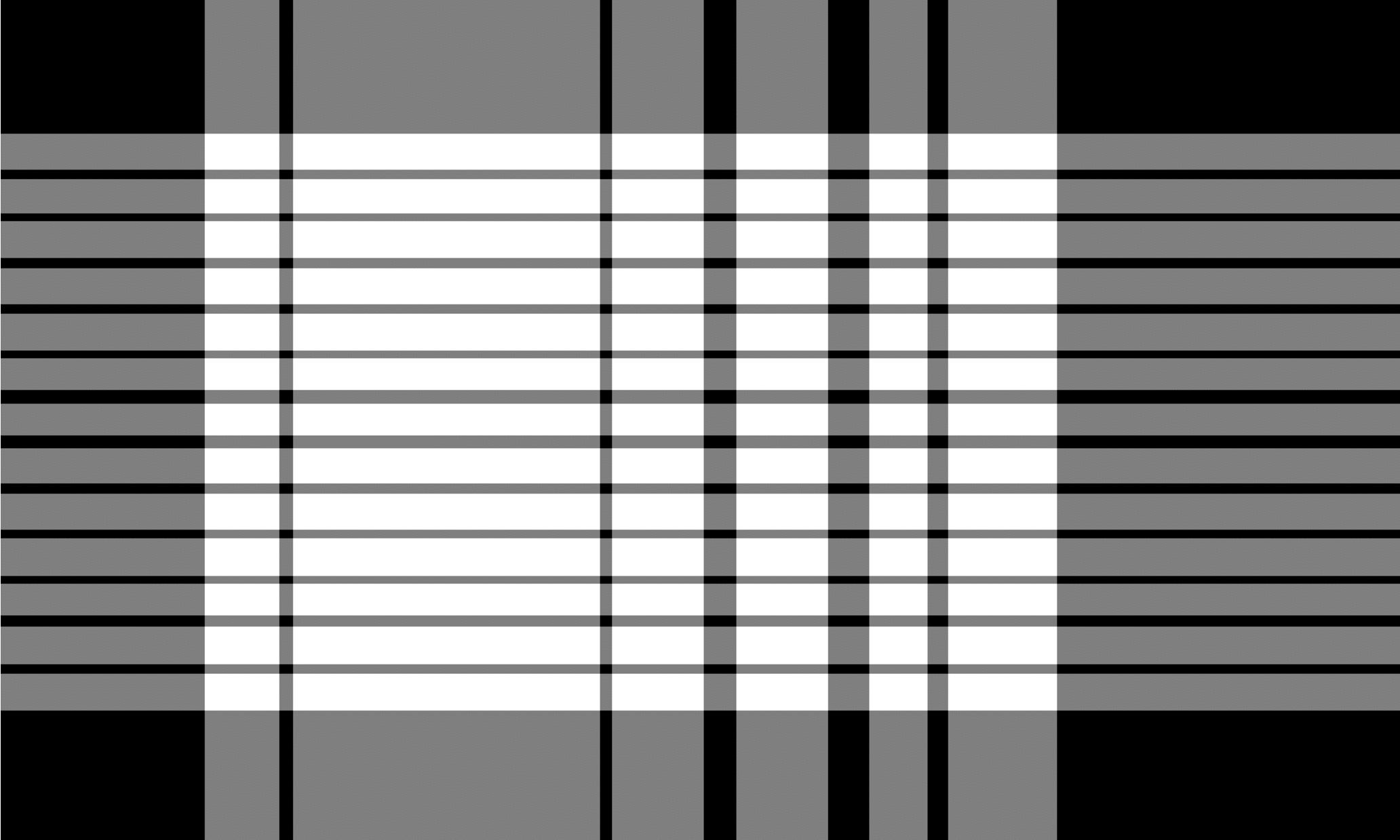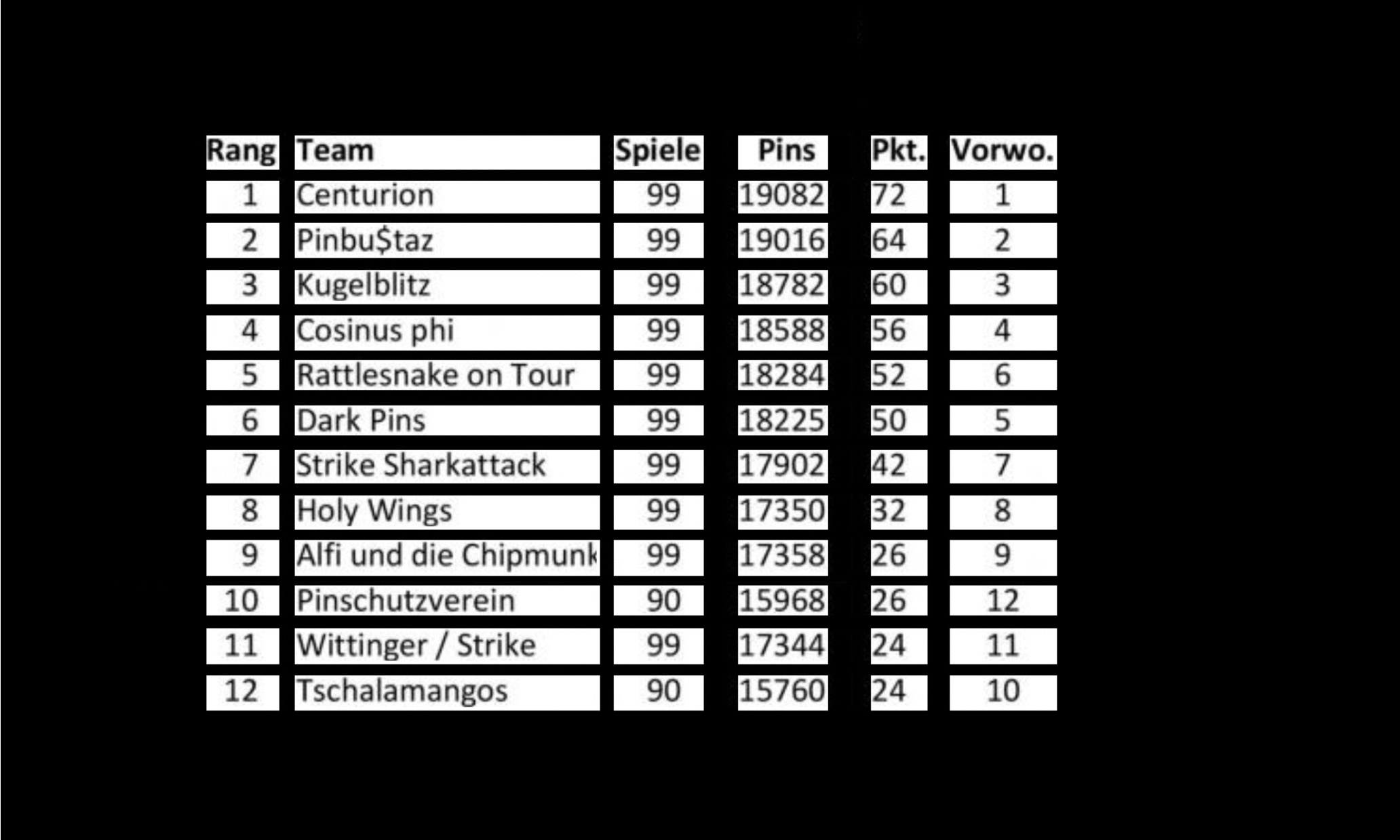
Multi-Typ-TD-TSR auf vollständig begrenzten Tischen
Für TSR in vollständig umrandeten Tabellen verwenden wir den Erosions- und Dilatationsoperation, um das Zellbild des Zeilensäulenzellens ohne Text oder Zeichen zu extrahieren. Die Erosionskerne sind im Allgemeinen dünne vertikale und horizontale Streifen, die länger sind als die Gesamtschriftgröße, aber kürzer als die Größe der kleinsten Gitterzelle und müssen insbesondere nicht breiter sein als die kleinste Tischrandbreite. Die Verwendung dieser Kernelgrößenbeschränkungen führt dazu, dass die Erosionsoperation alle Schriftarten und Zeichen aus der Tabelle entfernt wird, während die Tabellengrenzen erhalten bleiben. Um die ursprüngliche Linienform wiederherzustellen, wendet der Algorithmus den Dilatationsvorgang mit derselben Kernelgröße auf jedem der beiden erodierten Bilder an, wodurch ein Bild mit vertikalem und einer Sekunde mit horizontalen Linien erzeugt wird. Schließlich kombiniert der Algorithmus beide Bilder unter Verwendung eines bit-weisen `` `oder`` -Operation und neu invertiert die Pixelwerte, um ein Rasterzellbild zu erhalten. Wir verwenden dann die Konturenfunktion auf dem Gitterzellbild, um die Begrenzungskästen für jede einzelne Gitterzelle zu extrahieren.
Multi-Typ-TD-TSR auf ungebrernten Tischen
Der TSR -Algorithmus für nicht angeordnete Tabellen funktioniert ähnlich wie für umrandete Tabellen, nutzt jedoch den Erosionsbetrieb auf unterschiedliche Weise. Der Erosionskern ist im Allgemeinen ein dünner Streifen mit dem Unterschied, dass die horizontale Größe des horizontalen Kernels die vollständige Bildbreite und die vertikale Größe des vertikalen Kernels die vollständige Bildhöhe enthält. Der Algorithmus rutscht beide Kerne unabhängig über das gesamte Bild von links nach rechts für den vertikalen Kernel und von oben nach unten für den horizontalen Kernel. Während dieses Vorgangs sucht es nach leeren Zeilen und Spalten, die keine Zeichen oder Schriftart enthalten. Die resultierenden Bilder werden durch eine bitbezogene Operation invertiert und kombiniert, die die endgültige Ausgabe erzeugt. Die Ausgabe ist ein Gitterzellbild, das dem aus TSR für umgestalte Tabellen ähnelt, in dem die überlappenden Bereiche der beiden resultierenden Bilder die Begrenzungskästen für jede einzelne Gitterzelle darstellen.
Multi-Typ-TD-TSR auf teilweise begrenzten Tischen
Das Hauptziel unserer Algorithmen für umrandete und nicht angeordnete Tabellen ist es, ein Gitterzellenbild zu erstellen, indem Grenzen im nicht angeordneten Fall hinzugefügt und Linien im umrandeten Fall erfasst werden. Wenn eine Tabelle nur teilweise begrenzt ist, wird der ungebrernte Algorithmus verhindert, dass die vorhandenen Grenzen Grenzen in orthogonaler Richtung hinzufügen, während der umrandete Algorithmus nur die vorhandenen Grenzen finden kann. Beide Ansätze führen zu unvollständigen Gitterzellbildern.
TSR für teilweise begrenzte Tabellen verwendet denselben Erosionsalgorithmus wie in umgestellten Tabellen, um vorhandene Borders zu erkennen. Dies ermöglicht die Anwendung des Algorithmus auf nicht angeordnete Tabellen, um das Gitterzellbild und die Konturen analog zu den oben diskutierten Varianten zu erstellen. Ein wesentliches Merkmal dieses Ansatzes ist, dass er sowohl mit ausrandeten als auch mit nicht angeordneten Tabellen funktioniert: Es ist typenunabhängig.
Tabellenstrukturerkennungsergebnisse
ICDAR 19 (Track B2)
| Iou | Iou | Iou | Iou | Gewichtet |
|---|
| Team | 0,6 | 0,7 | 0,8 | 0,9 | Durchschnitt |
| Cascadetabnet | 0,438 | 0,354 | 0,19 | 0,036 | 0,232 |
| NLPR-PAL | 0,365 | 0,305 | 0,195 | 0,035 | 0,206 |
| Multi-Typ-TD-TSR | 0,589 | 0,404 | 0,137 | 0,015 | 0,253 |
Anweisungen
Konfigurationen
Der Quellcode wird unter den folgenden Bibliotheksabhängigkeiten entwickelt
- Pytorch = 1,7.0
- Torchvision = 0,8,1
- CUDA = 10,1
- Pyyaml = 5.1
DETECTRON 2
Das Tabellenerkennungsmodell basiert auf DETECTRON2. Folgen Sie diesem Installationshandbuch zum Setup.
Bildausrichtung Vorverarbeitung
Für den Vorverarbeitungschritt für die Bildausrichtung steht ein Skript zur Verfügung:
Um den Vorverarbeitungalgorithmus zur Bildausrichtung auf alle Bilder in einem Ordner anzuwenden, müssen Sie ausführen:
mit den folgenden Parametern
-
--folder den Eingaberordner einschließlich Dokumentbildern -
--output des Ausgangsordners für die Deskewed-Bilder
Tabellenstrukturerkennung (TSR)
Für die Tabellenstrukturerkennung bieten wir ein einfaches Skript für verschiedene Ansätze an
Um einen Tabellenstrukturerkennungsalgorithmus auf alle Bilder in einem Ordner anzuwenden, müssen Sie ausführen:
mit den folgenden Parametern
-
--folder des Eingabeforders einschließlich Tabellenbilder -
--type den type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--img_output -Ausgangsordnerpfad für die verarbeiteten Bilder -
--xml_output Ausgangsordnerpfad für die XML-Dateien einschließlich Begrenzungsfeldern
Tabellenerkennung und Tabellenstrukturerkennung (TD & TSR)
Um die Tabellenerkennung mit einem folgenden Tabellenstrukturerkennung zu berechnen
Um einen Tabellenstruktur -Erkennungsalgorithmus auf alle Bilder in einem Ordner anzuwenden, müssen Sie ausführen:
mit den folgenden Parametern
-
--folder des Eingabeforders einschließlich Tabellenbilder -
--type den type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--tsr_img_output Ausgangsordnerpfad für die verarbeiteten Tabellenbilder -
--td_img_output Ausgangsordner-Ordnerpfad für die erzeugten Tabellenausschnitte -
--xml_output Ausgangsordnerpfad für die XML-Dateien für Tabellen und Zellen einschließlich Begrenzungsboxen -
--config der DETECRON2-Konfigurationsdatei für die Tabellenerkennung -
--yaml -Pfad der DETECTRON2-YAML-Datei zur Tischerkennung -
--weights der Detektron2-Modellgewichte für die Tabellenerkennung
Auswertung
Um den Algorithmus zur Erkennung von Tabellenstruktur zu bewerten, geben wir das folgende Skript an:
Um die Bewertung anzuwenden, müssen die Tabellenbilder und deren Beschriftungen in XML-Format der gleiche Name sein und sollten in einem einzelnen Ordner liegen. Die Bewertung könnte durch:
mit dem folgenden Parameter
-
--dataset -Datensatzordnerpfad mit Tabellenbildern und Beschriftungen im .xml-Format enthält
Daten abrufen
- Testen Sie den Datensatz für die Erkennung von Tabellenstruktur, einschließlich Tabellenbildern und Anmerkungen können hier heruntergeladen werden
- Tabellenerkennungsdetektron2 -Modellgewichte und Konfigurationsdateien können hier heruntergeladen werden
Zitat
@misc{fischer2021multitypetdtsr,
title={Multi-Type-TD-TSR - Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations},
author={Pascal Fischer and Alen Smajic and Alexander Mehler and Giuseppe Abrami},
year={2021},
eprint={2105.11021},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


