Multi-Type-TD-TSR
Confira no código-fonte do nosso artigo: Tabelas de extração de vários tipos TD-TSR a partir de imagens de documentos usando um pipeline de várias etapas para detecção de tabela e reconhecimento de estrutura de tabela
Descrição
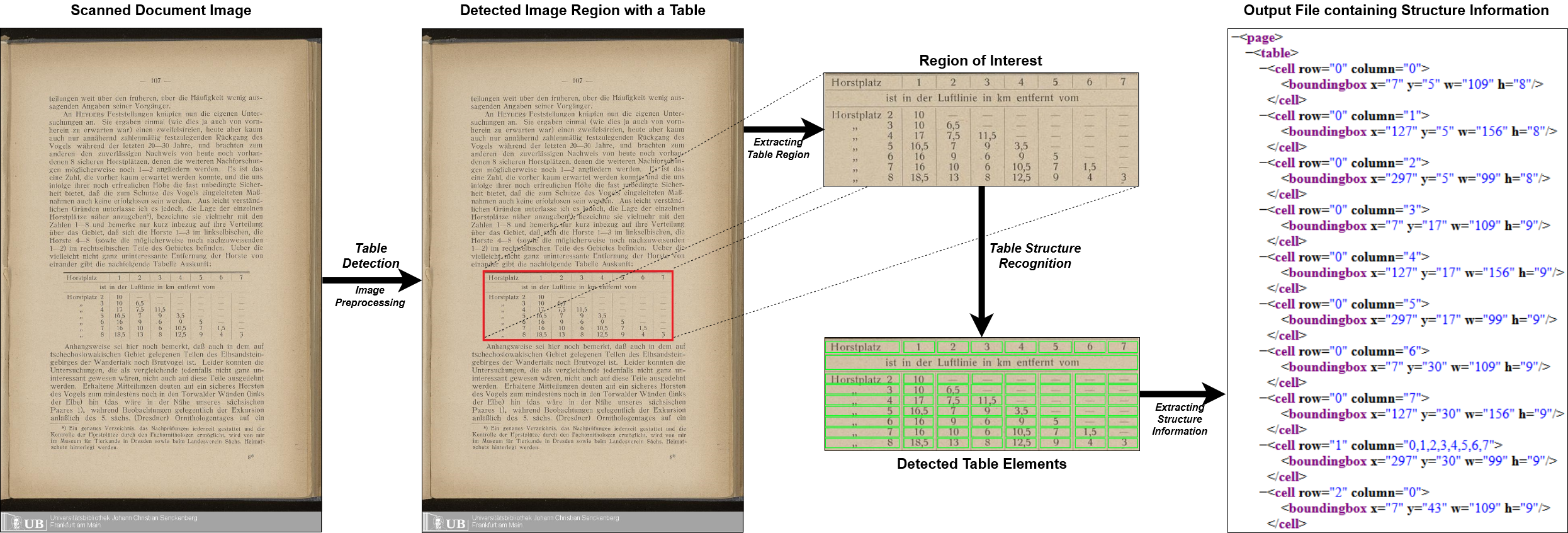
Multi-type-td-tsr todo o pipeline
À medida que as tendências globais estão mudando para as indústrias orientadas a dados, a demanda por algoritmos automatizados que podem converter imagens digitais de documentos digitalizados em informações legais para a máquina está crescendo rapidamente. Além da oportunidade de digitalização de dados para a aplicação de ferramentas analíticas de dados, também há uma grande melhoria em relação à automação de processos, que anteriormente exigiria a inspeção manual dos documentos. Embora a introdução das tecnologias de reconhecimento de caracteres ópticos (OCR) tenha resolvido principalmente a tarefa de converter caracteres legíveis por humanos de imagens em caracteres legíveis por máquina, a tarefa de extrair a semântica da tabela tem sido menos focada ao longo dos anos. O reconhecimento das tabelas consiste em duas tarefas principais, a saber, detecção de tabela e reconhecimento da estrutura da tabela. A maioria dos trabalhos anteriores sobre esse problema concentra a tarefa sem oferecer uma solução de ponta a ponta ou prestar atenção a condições reais de aplicação, como imagens rotacionadas ou artefatos de ruído dentro da imagem do documento. Trabalhos recentes mostram uma tendência clara para abordagens de aprendizado profundo, juntamente com o uso do aprendizado de transferência para a tarefa de reconhecimento da estrutura da tabela devido à falta de conjuntos de dados suficientemente grandes. Neste artigo, apresentamos um pipeline de vários estágios chamado MultiTiPe-TD-TSR, que oferece uma solução de ponta a ponta para o problema do reconhecimento da tabela. Ele utiliza modelos de aprendizado profundo de ponta para detecção de tabela e diferenciam entre três tipos diferentes de tabelas com base nas fronteiras das tabelas. Para o reconhecimento da estrutura da tabela, usamos um algoritmo determinístico não acionado por dados, que funciona em todos os tipos de tabela. Além disso, apresentamos dois algoritmos. Um para mesas não fundidas e outra para mesas delimitadas, que são a base do algoritmo de reconhecimento de estrutura de tabela usado. Avaliamos o conjunto de dados de reconhecimento de estrutura de tabela Multi-TD-TSR no ICDAR 2019 e alcançamos um novo estado da arte.
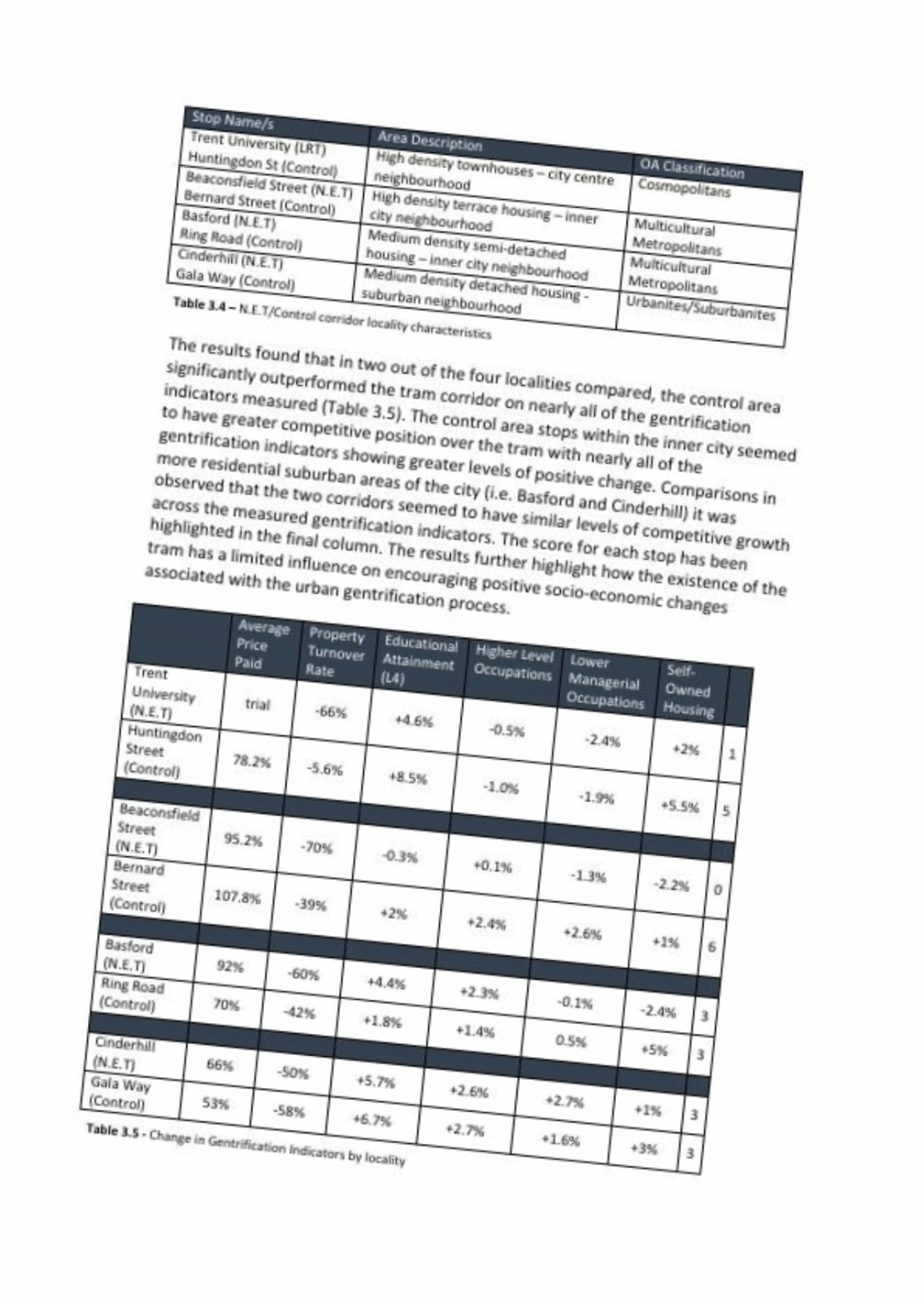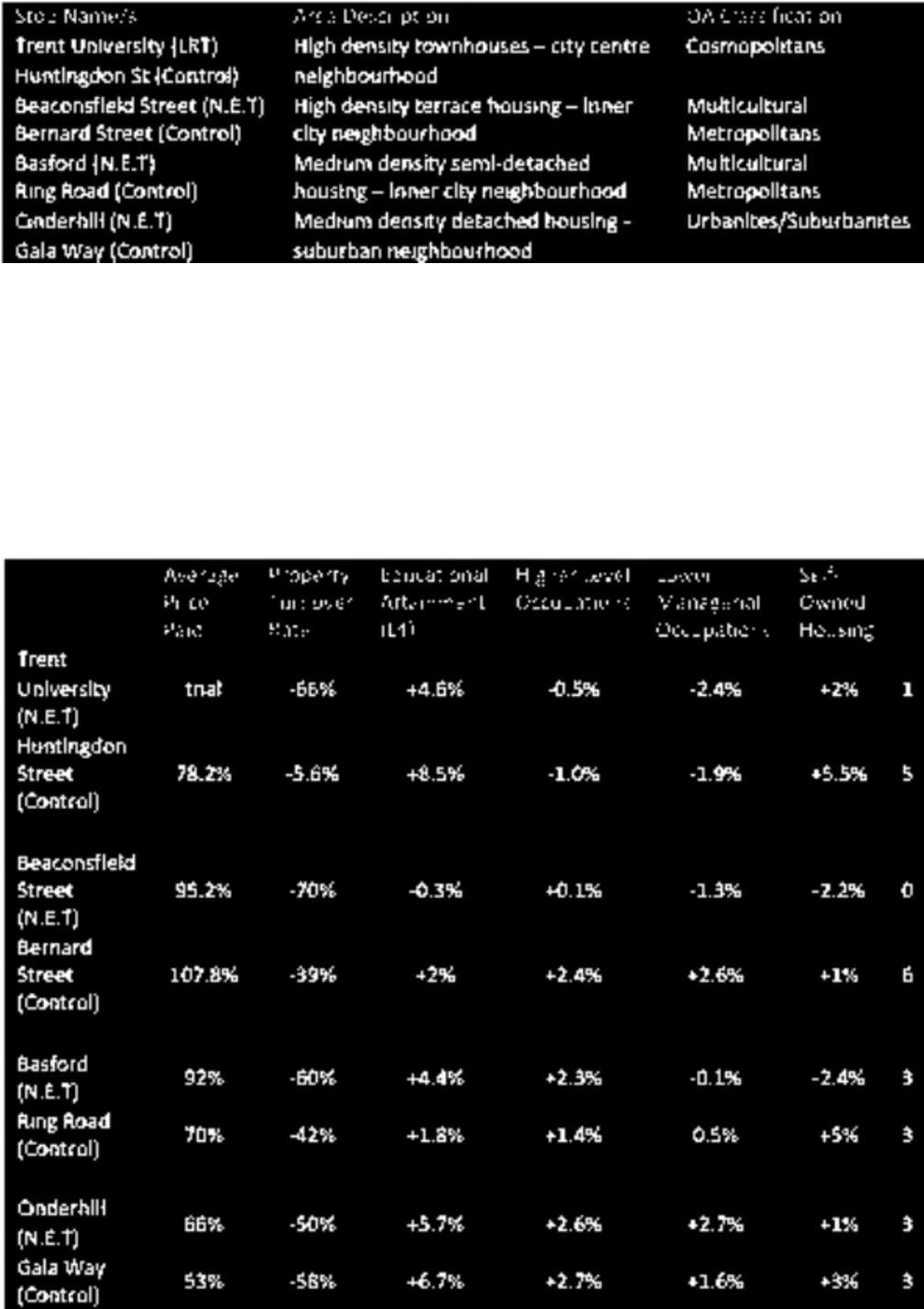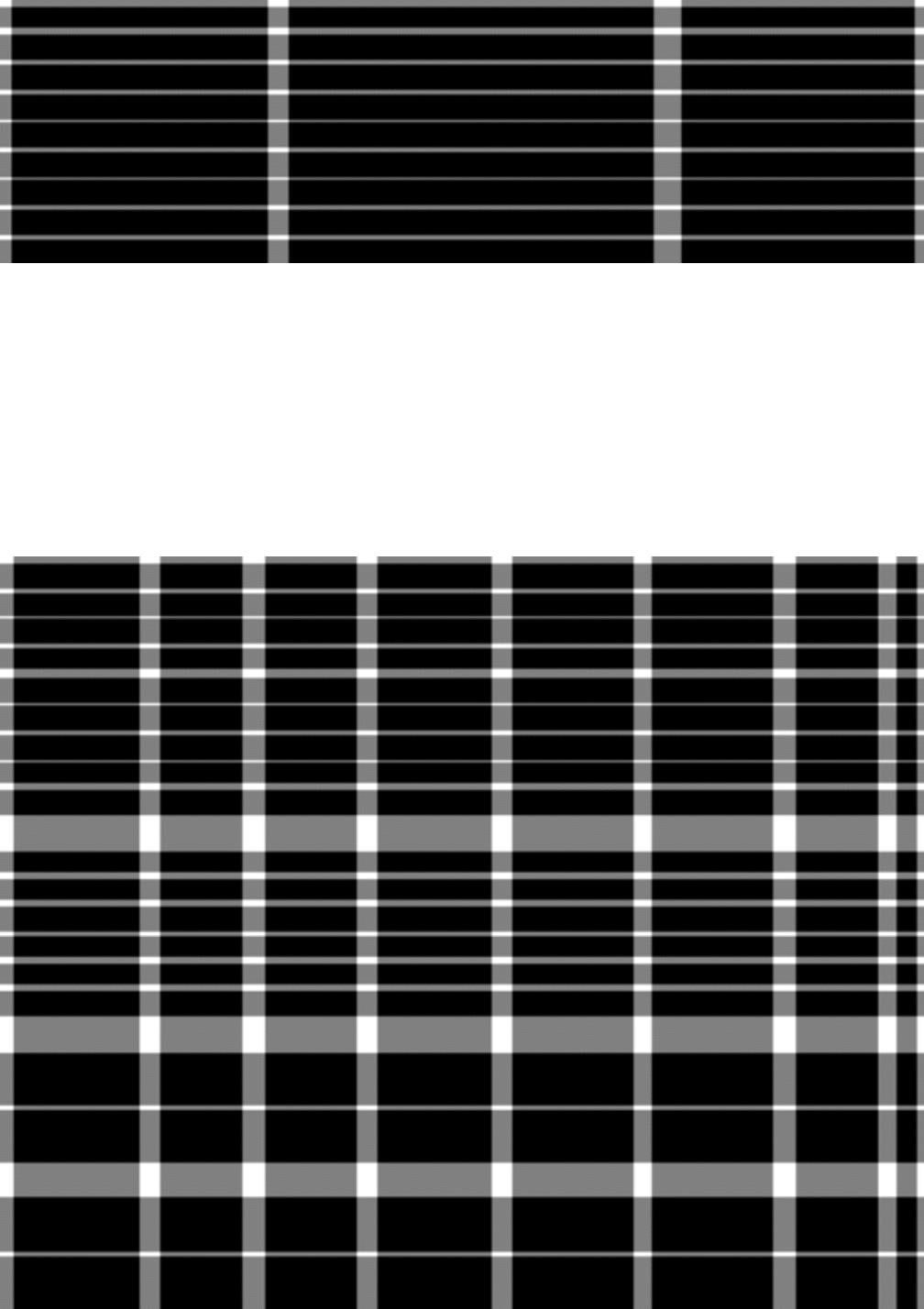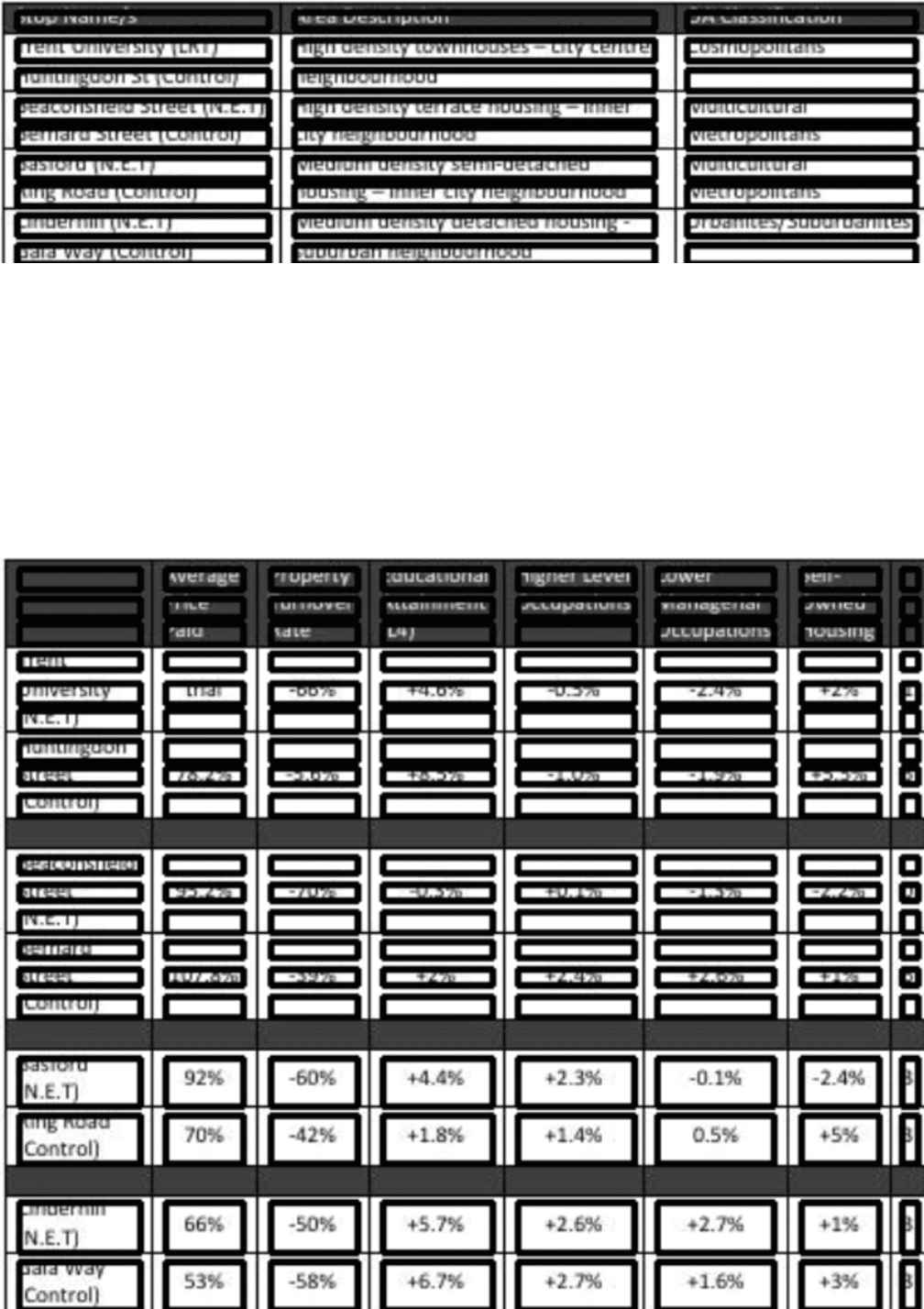
Multi-type-td-tsr em mesas totalmente borda
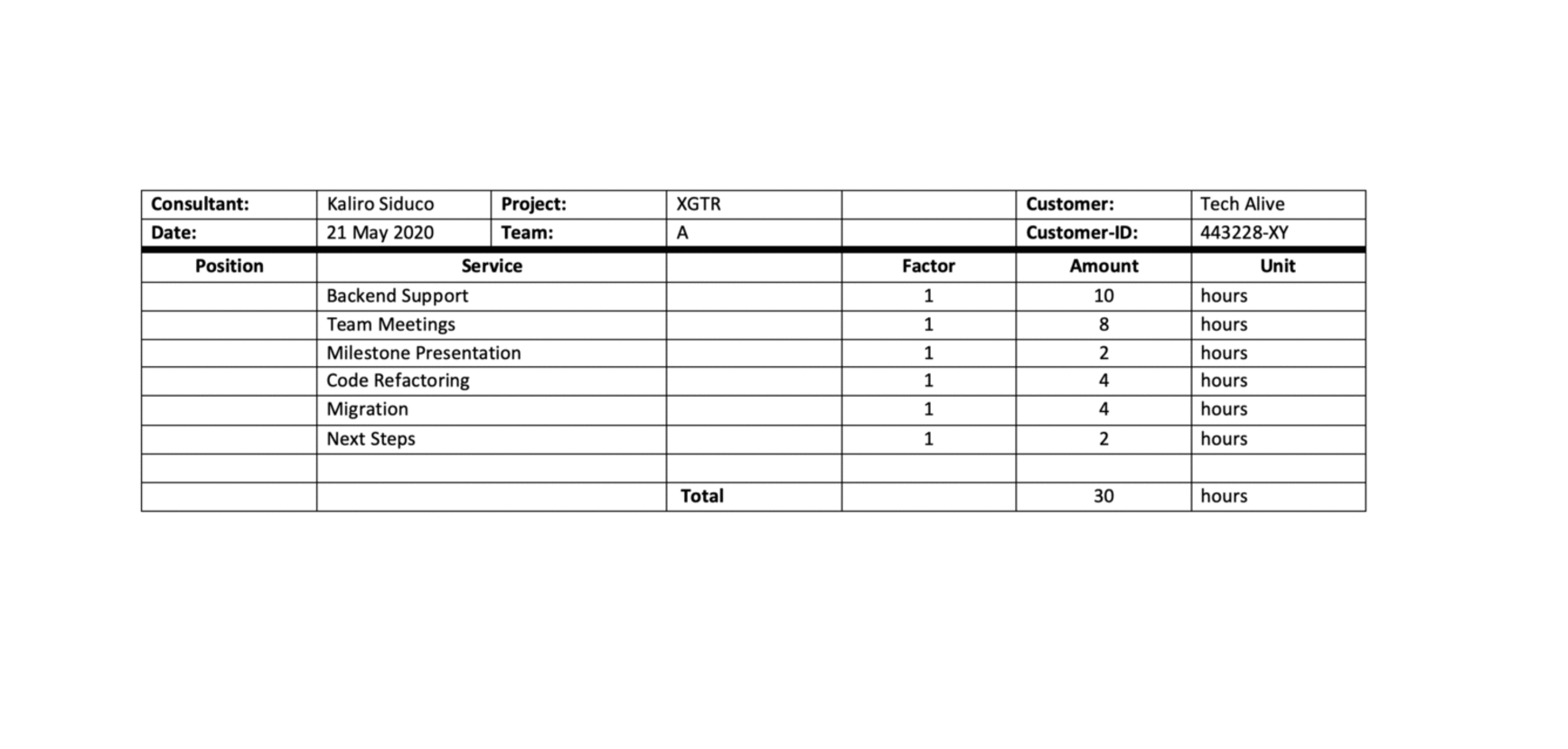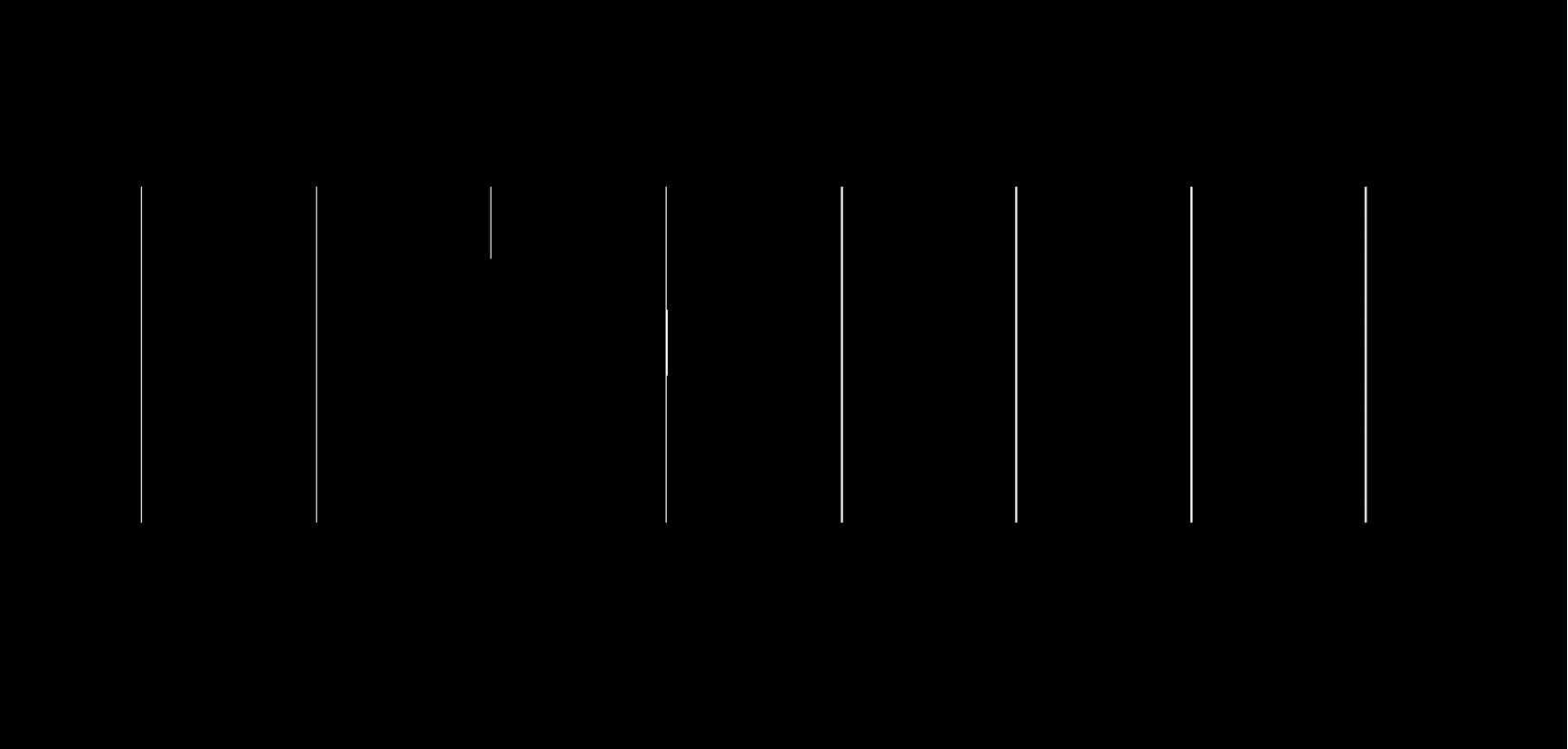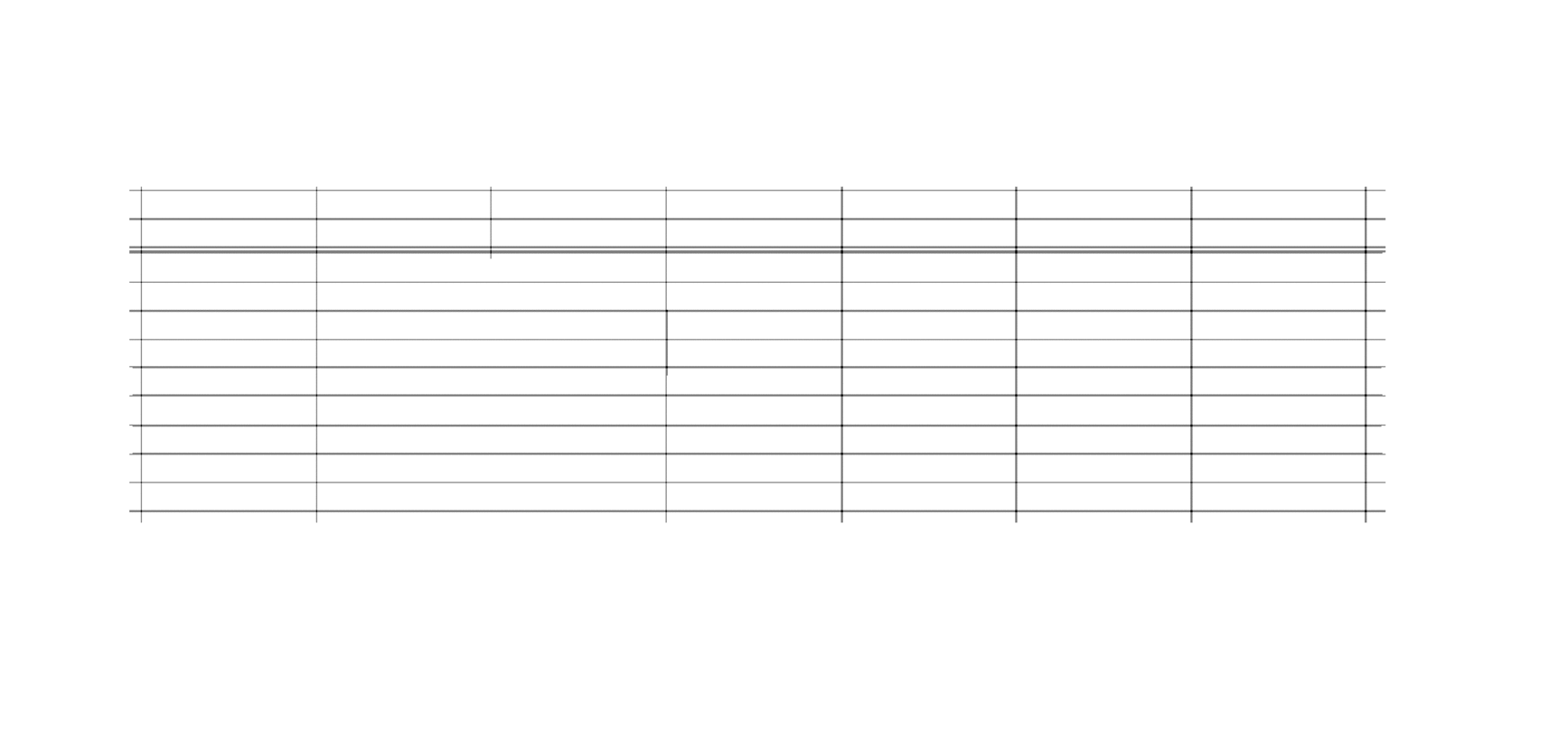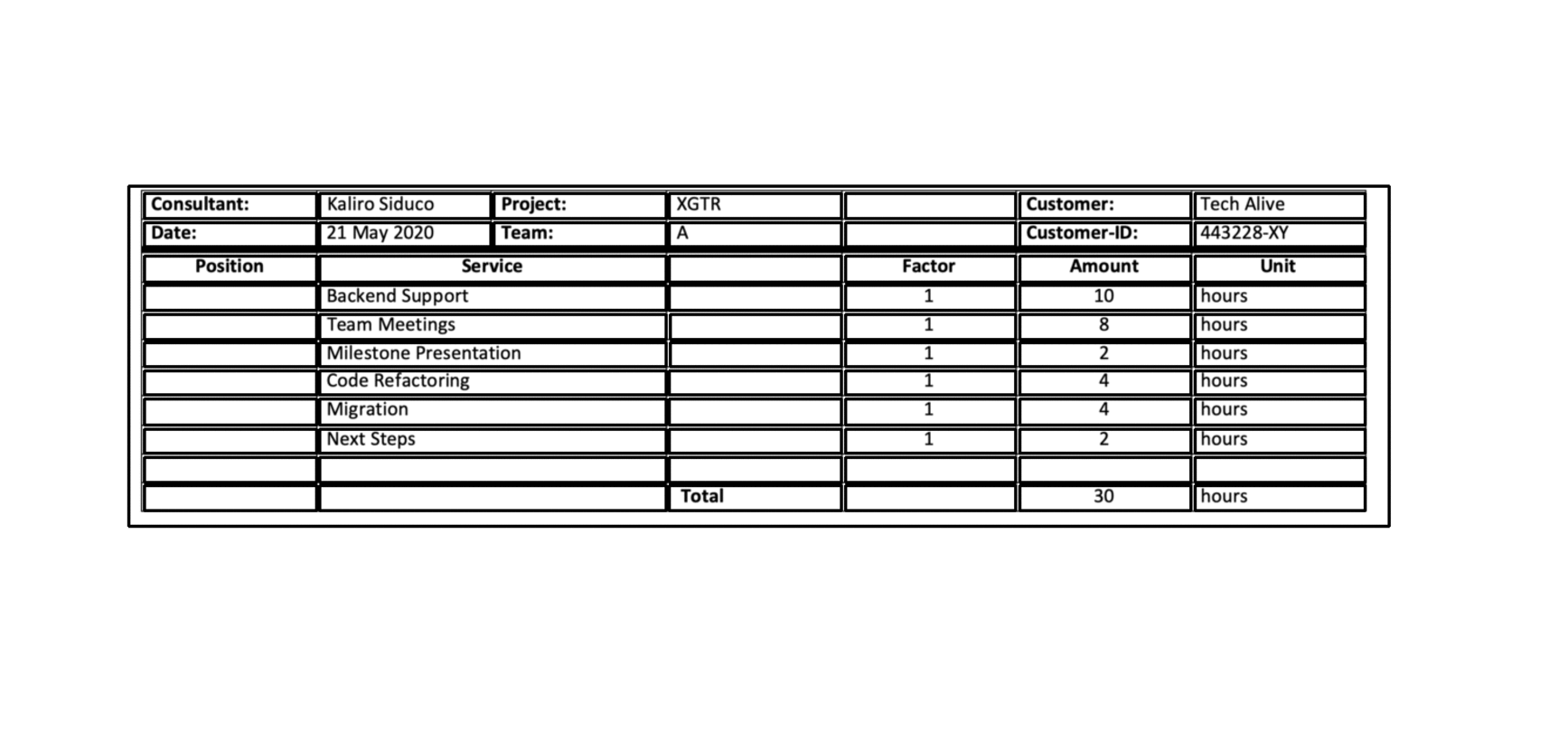
Para o TSR em tabelas totalmente delimitadas, usamos a operação de erosão e dilatação para extrair a imagem da célula da grade da coluna de linha sem nenhum texto ou caracteres. Os núcleos de erosão são geralmente tiras verticais e horizontais finas que são mais longas que o tamanho geral da fonte, mas mais curtas que o tamanho da menor célula da grade e, em particular, não devem ser mais largas que a menor largura da borda da tabela. O uso dessas restrições de tamanho do kernel resulta na operação de erosão, removendo todas as fontes e caracteres da tabela enquanto preservam as fronteiras da tabela. Para restaurar a forma da linha original, o algoritmo aplica a operação de dilatação usando o mesmo tamanho de kernel em cada uma das duas imagens erodidas, produzindo uma imagem com vertical e um segundo com linhas horizontais. Finalmente, o algoritmo combina ambas as imagens usando uma operação `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `operação e reinverte os valores de pixel para obter uma imagem de célula raster. Em seguida, usamos a função de contornos na imagem da célula de grade para extrair as caixas delimitadoras para cada célula de grade.
Multi-Type-TD-TSR em mesas não fundidas
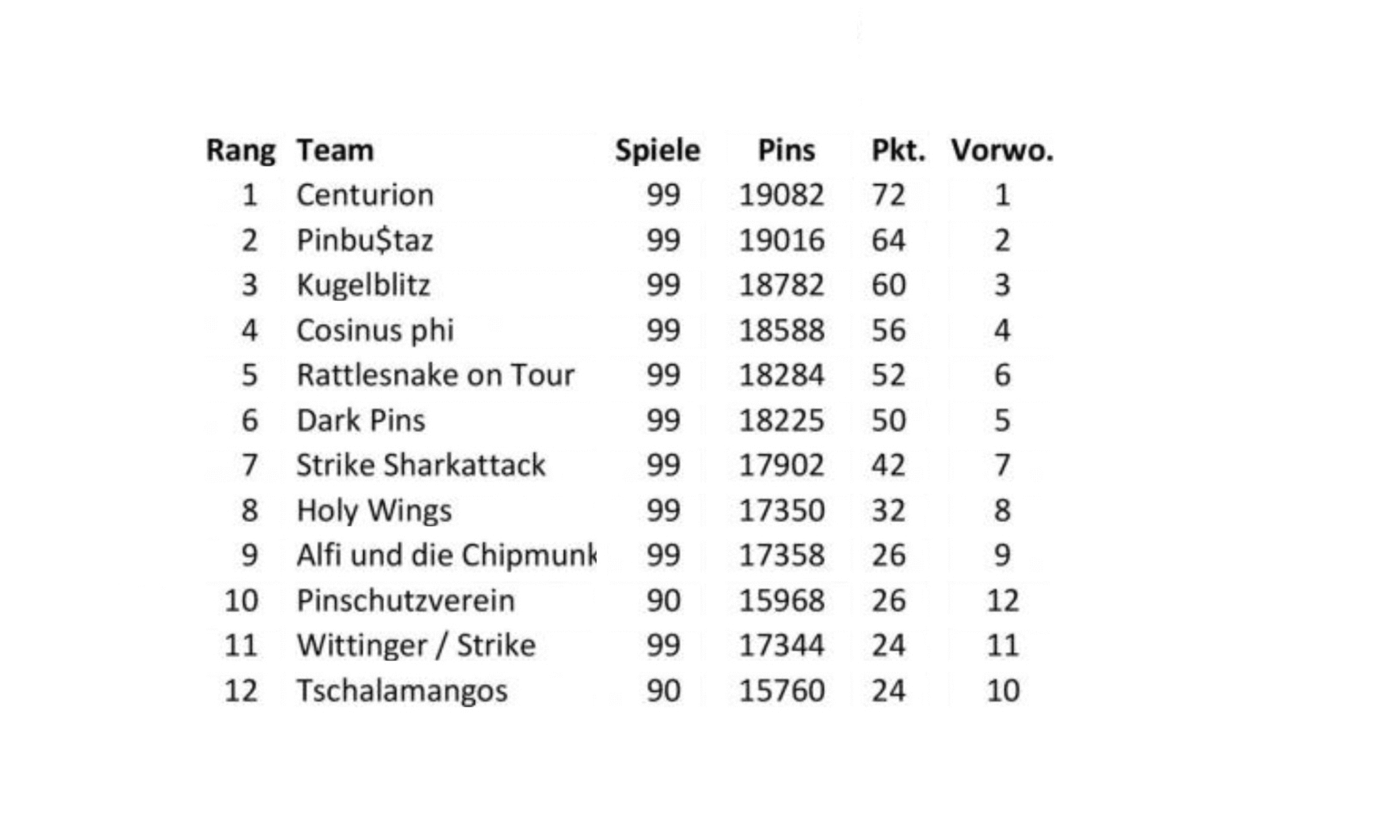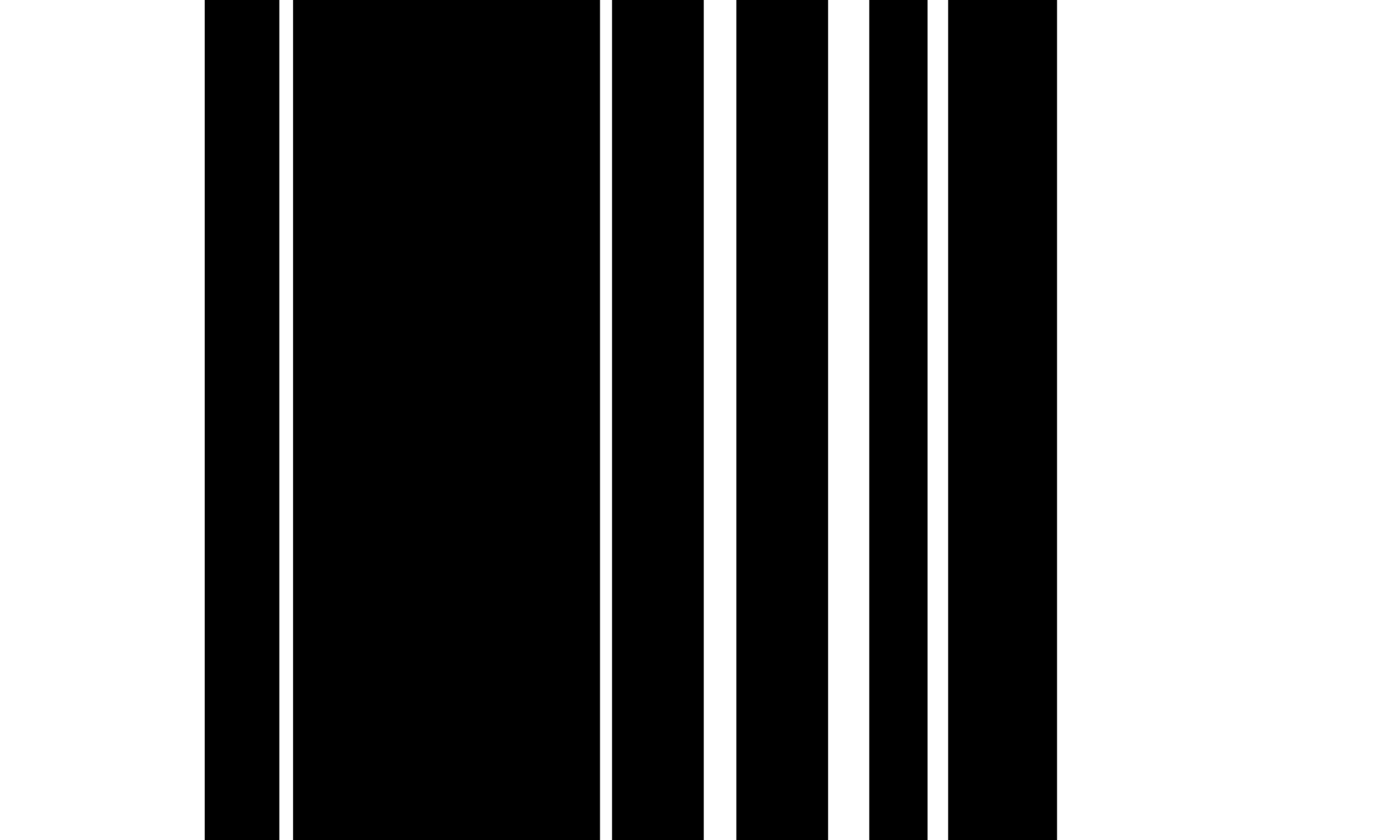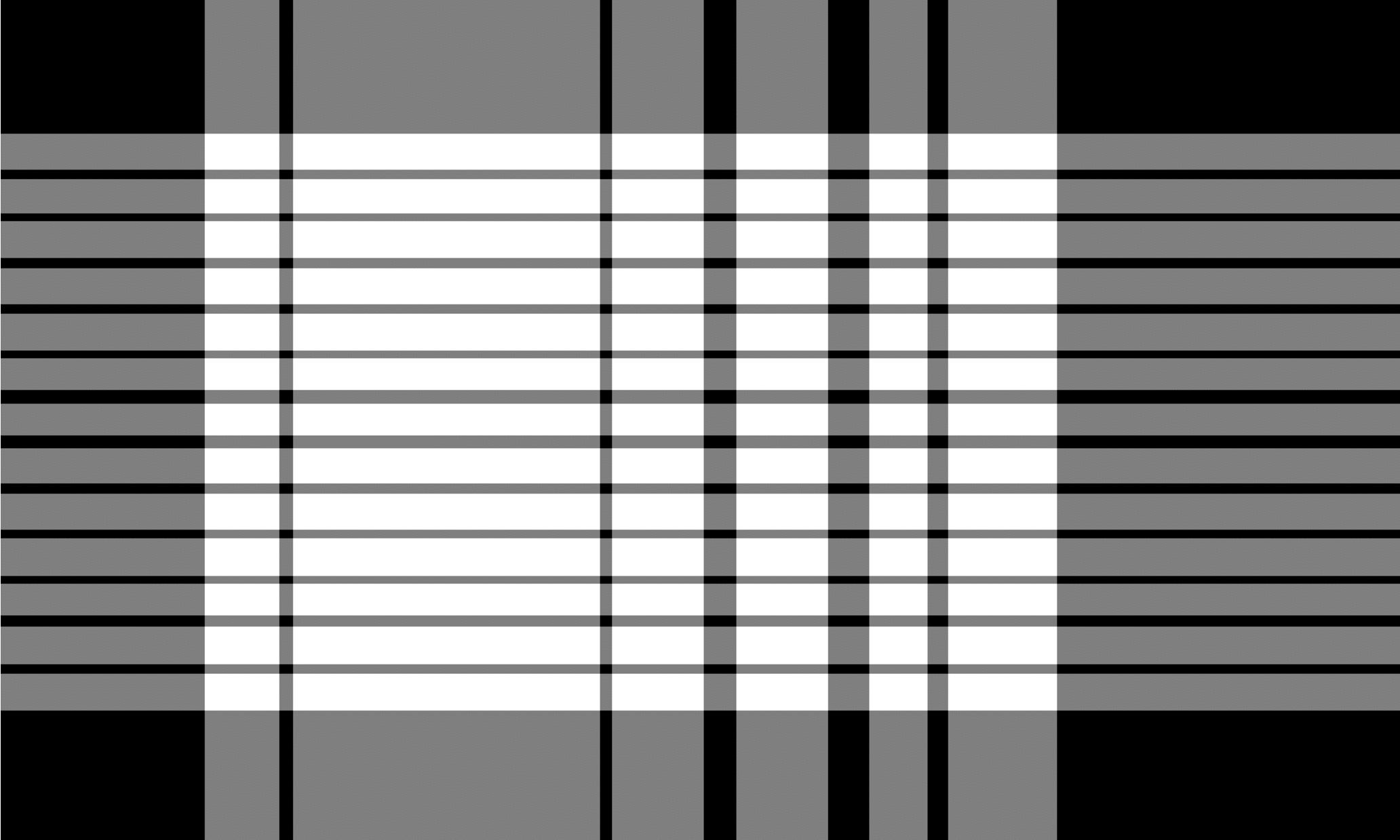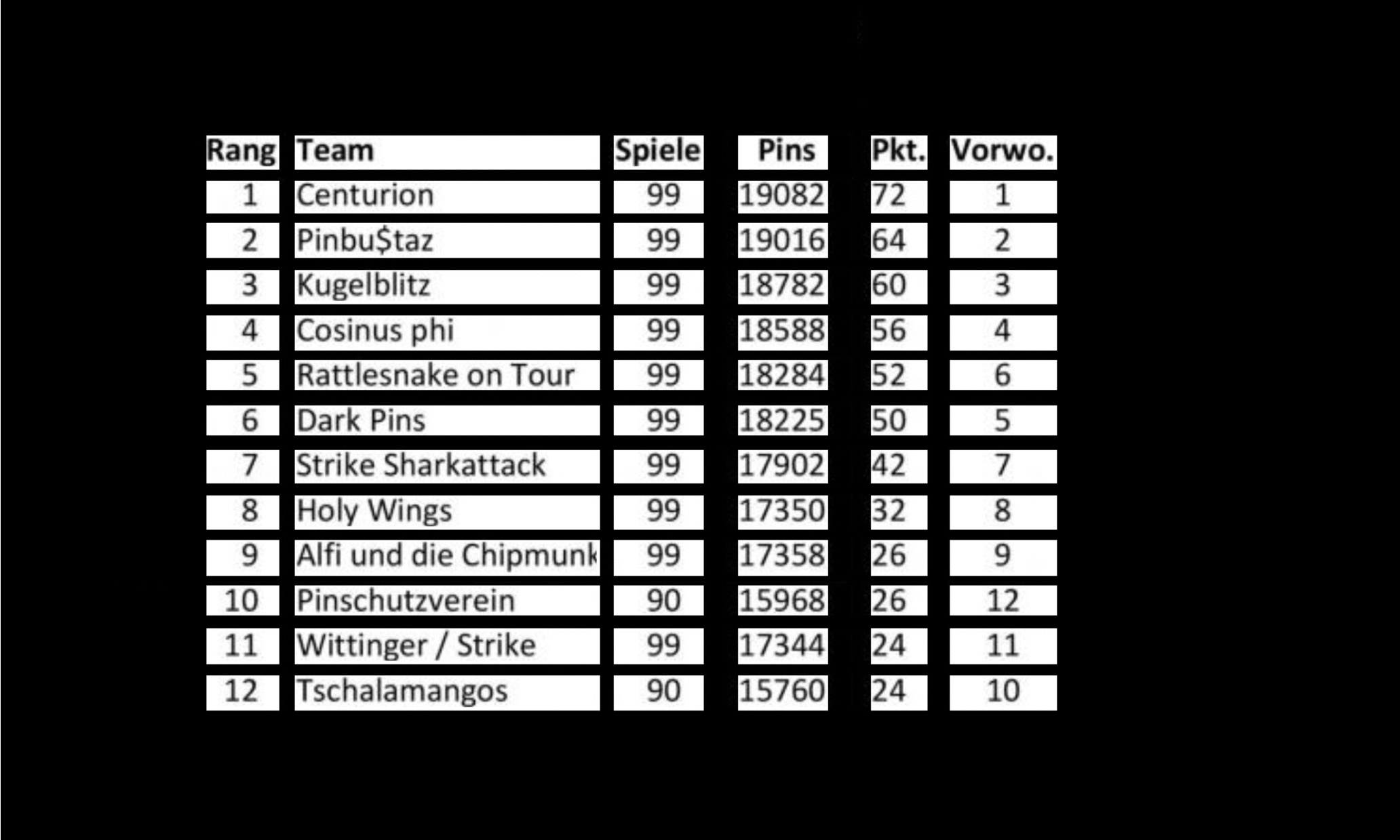
O algoritmo TSR para tabelas não fundidas funciona de maneira semelhante à de tabelas de fronteira, mas utiliza a operação de erosão de uma maneira diferente. O núcleo de erosão é, em geral, uma tira fina com a diferença de que o tamanho horizontal do kernel horizontal inclui a largura da imagem completa e o tamanho vertical do núcleo vertical a altura da imagem completa. O algoritmo desliza ambos os núcleos independentemente de toda a imagem da esquerda para a direita para o kernel vertical e de cima para baixo para o kernel horizontal. Durante esse processo, ele está procurando linhas e colunas vazias que não contêm caracteres ou fonte. As imagens resultantes são invertidas e combinadas por uma operação `` `` ``` ', produzindo a saída final. A saída é uma imagem de célula de grade semelhante à do TSR para tabelas de fronteira, onde as áreas sobrepostas das duas imagens resultantes representam as caixas delimitadoras para cada célula de grade.
Multi-Type-TD-TSR em mesas parcialmente delimitadas
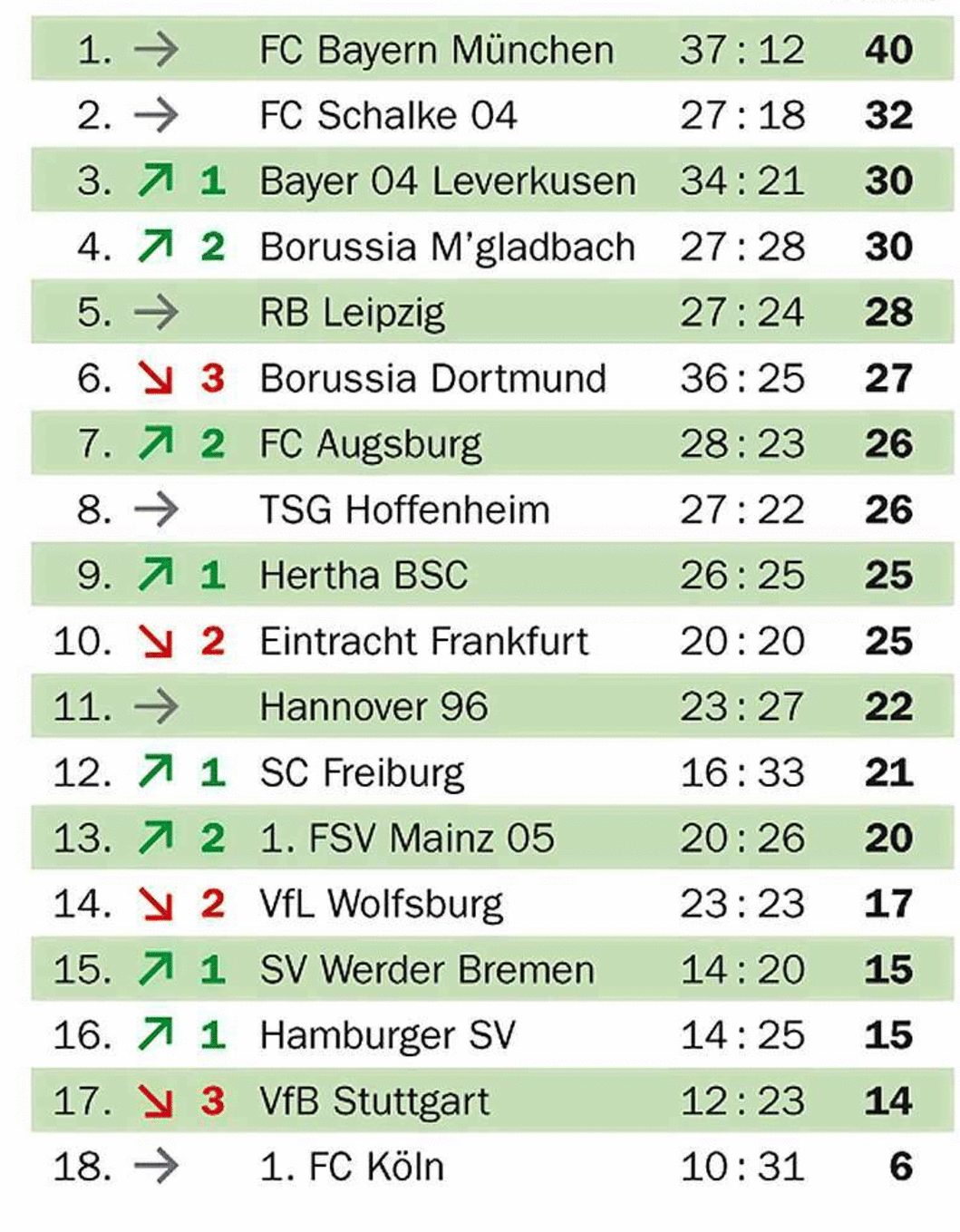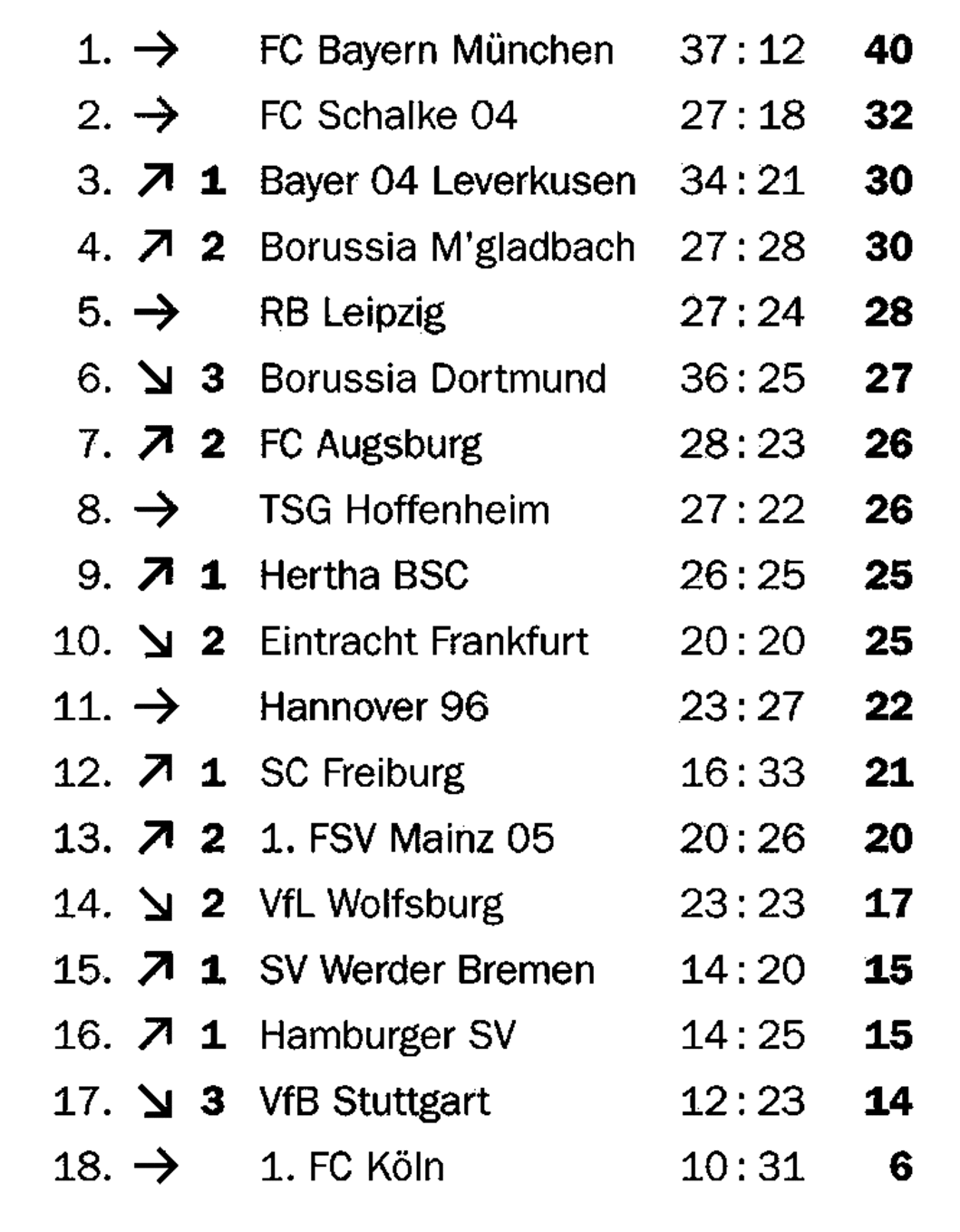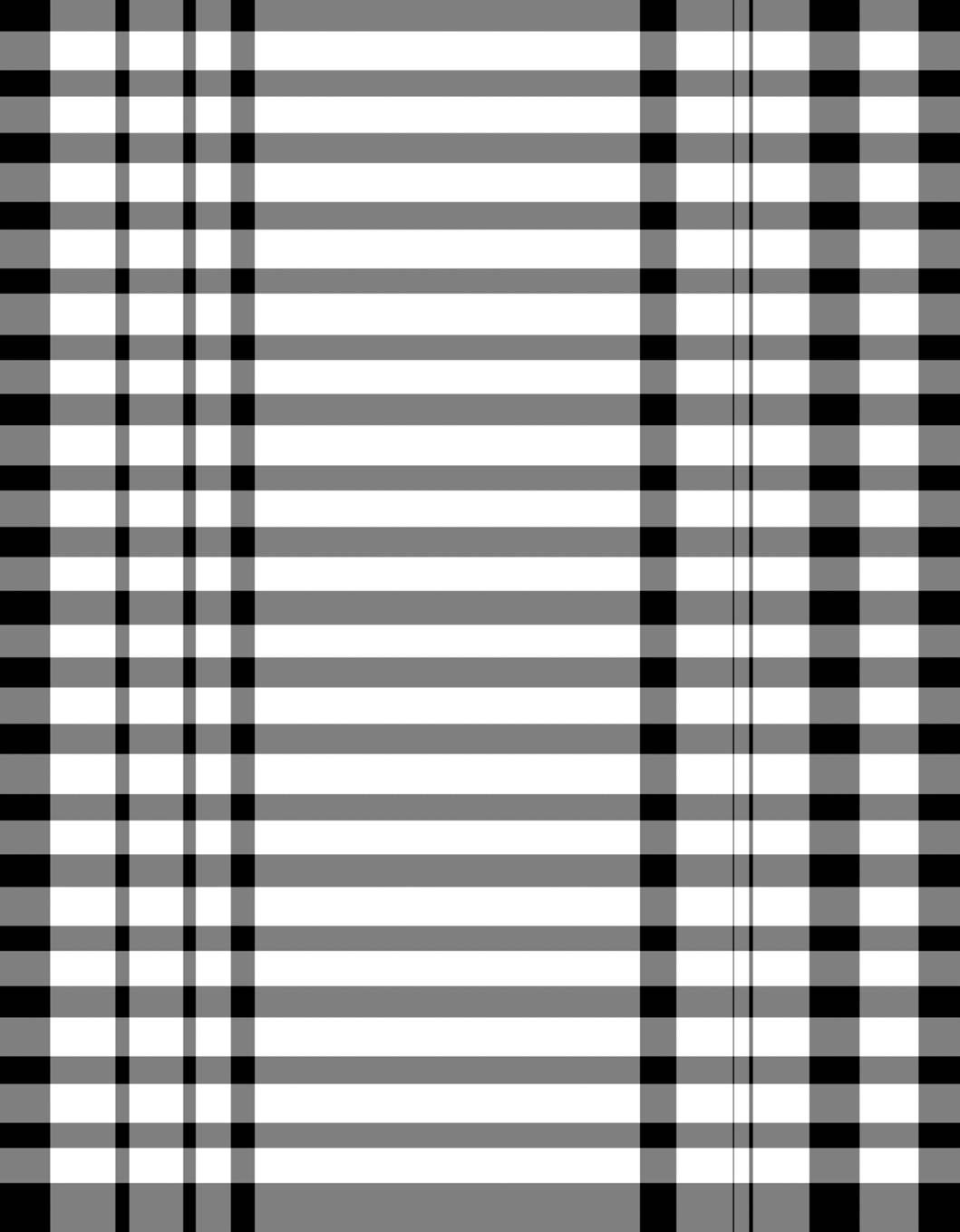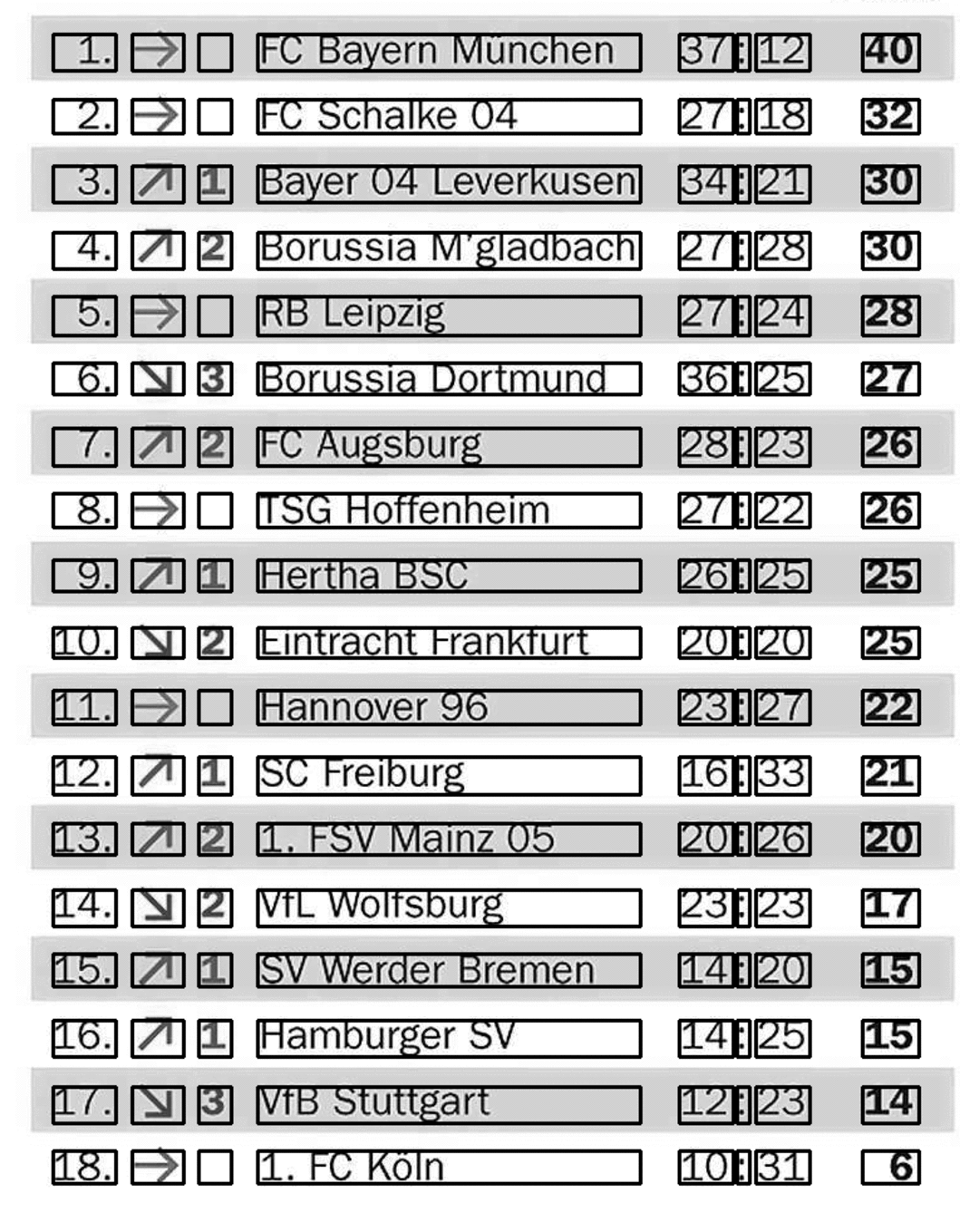
O principal objetivo de nossos algoritmos para tabelas de fronteira e não fundedentada é criar uma imagem de célula de grade adicionando fronteiras no estojo não fundido e detectando linhas no caso da fronteira. Se uma tabela for apenas parcialmente delimitada, o algoritmo não fundido será impedido de adicionar bordas na direção ortogonal às fronteiras existentes, enquanto o algoritmo fronteiriado só pode encontrar as fronteiras existentes. Ambas as abordagens resultam em imagens de células de grade incompletas.
O TSR para tabelas parcialmente delimitadas usa o mesmo algoritmo de erosão que em tabelas delimitadas para detectar as fronteiras existentes, mas sem usá -las para criar uma célula de grade, mas para excluir as fronteiras da imagem da tabela para obter uma tabela não fundida. Isso permite aplicar o algoritmo para tabelas não fundidas para criar a imagem e os contornos da célula de grade por analogia às variantes discutidas acima. Uma característica fundamental dessa abordagem é que ela funciona com tabelas fronteiriadas e não fundidas: é independente do tipo.
Resultados de reconhecimento da estrutura da tabela
ICDAR 19 (faixa B2)
| Iou | Iou | Iou | Iou | Ponderado |
|---|
| Equipe | 0,6 | 0,7 | 0,8 | 0,9 | Média |
| CascadeTabnet | 0,438 | 0,354 | 0,19 | 0,036 | 0,232 |
| NLPR-PAL | 0,365 | 0,305 | 0,195 | 0,035 | 0,206 |
| Multi-Type-TD-TSR | 0,589 | 0,404 | 0,137 | 0,015 | 0,253 |
Instruções
Configurações
O código -fonte é desenvolvido nas seguintes dependências da biblioteca
- Pytorch = 1.7.0
- Torchvision = 0.8.1
- CUDA = 10.1
- Pyyaml = 5.1
Detectron 2
O modelo de detecção de tabela é baseado no Detectron2, siga este guia de instalação para configuração.
Alinhamento de imagem Pré-processamento
Para a etapa de pré-processamento de alinhamento da imagem, há um script disponível:
Para aplicar o algoritmo de pré-processamento de alinhamento de imagem a todas as imagens em uma pasta, você precisa executar:
com os seguintes parâmetros
-
--folder a pasta de entrada, incluindo imagens de documentos -
--output a pasta de saída para as imagens Deskewed
Reconhecimento da estrutura da tabela (TSR)
Para o reconhecimento da estrutura da tabela, oferecemos um script simples para diferentes abordagens
Para aplicar um algoritmo de reconhecimento da estrutura da tabela em todas as imagens em uma pasta, você precisa executar:
com os seguintes parâmetros
-
--folder mais flexível da pasta de entrada, incluindo imagens de tabela -
--type O tipo de reconhecimento da estrutura da tabela type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--img_output Saída PASTER PATH para as imagens processadas -
--xml_output Saída PATHER PATHER PARA Os arquivos XML, incluindo caixas delimitadoras
Detecção de tabela e reconhecimento da estrutura da tabela (TD & TSR)
Para aplicar a detecção de tabela com um reconhecimento de estrutura de tabela seguido
Para aplicar um algoritmo de reconhecimento da estrutura da tabela em todas as imagens em uma pasta, você precisa executar:
com os seguintes parâmetros
-
--folder mais flexível da pasta de entrada, incluindo imagens de tabela -
--type O tipo de reconhecimento da estrutura da tabela type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--tsr_img_output de saída Caminho da pasta para as imagens da tabela processada -
--td_img_output de saída Caminho para os recortes de tabela produzidos -
--xml_output Saída PATHER PATHER para os arquivos XML para tabelas e células, incluindo caixas delimitadoras -
--config Caminho do arquivo de configuração do Detectron2 para detecção de tabela - -Caminho
--yaml do arquivo YAML do Detectron2 para detecção de tabela -
--weights DE PESO DE PESO DE MODELO DE DETECRON2 para detecção de tabela
Avaliação
Para avaliar o algoritmo de reconhecimento da estrutura da tabela, fornecemos o seguinte script:
Para aplicar a avaliação, as imagens da tabela e seus rótulos no formato XML devem ser o mesmo nome e devem estar em uma única pasta. A avaliação pode ser iniciada por:
com o seguinte parâmetro
-
--dataset DataSet Path Path contendo imagens de tabela e etiquetas no formato .xml
Obtenha dados
- conjunto de dados de teste para reconhecimento da estrutura da tabela, incluindo imagens de tabela e anotações pode ser baixado aqui
- detecção de tabela detecção de detecção de pesos do modelo e arquivos de configuração podem ser baixados aqui
Citação
@misc{fischer2021multitypetdtsr,
title={Multi-Type-TD-TSR - Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations},
author={Pascal Fischer and Alen Smajic and Alexander Mehler and Giuseppe Abrami},
year={2021},
eprint={2105.11021},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


