マルチタイプTD-TSR
私たちの論文のソースコードでそれをチェックしてください:マルチタイプのTD-TSRテーブル検出とテーブル構造認識のためにマルチステージパイプラインを使用してドキュメント画像からテーブルを抽出するテーブルを抽出します
説明
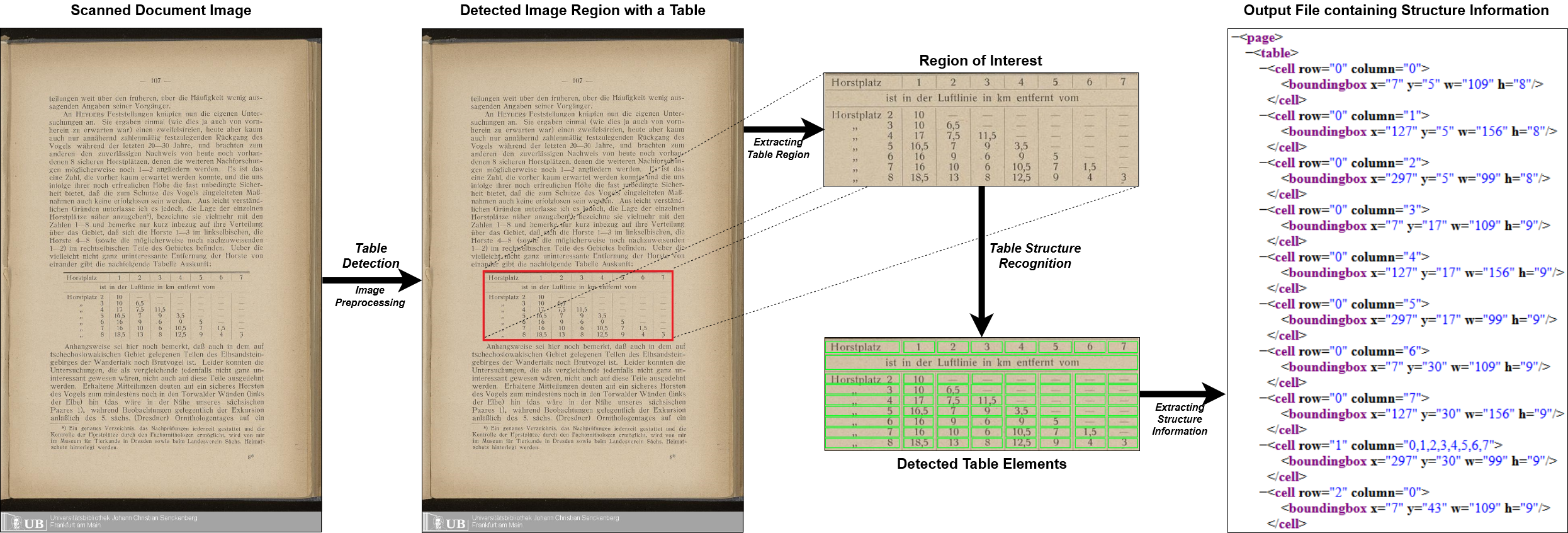
マルチタイプTD-TSRパイプライン全体
グローバルな傾向がデータ駆動型の産業に向けて変化するにつれて、スキャンされたドキュメントのデジタル画像を機械の読み取り可能な情報に変換できる自動化されたアルゴリズムの需要が急速に増加しています。データ分析ツールを適用するためのデータデジタル化の機会に加えて、以前はドキュメントの手動検査が必要だったプロセスの自動化に向けて大幅に改善されています。光学文字認識(OCR)テクノロジーの導入により、人間の読み取り可能な文字を画像から機械可読文字に変換するタスクがほとんど解決されましたが、テーブルセマンティクスを抽出するタスクは長年にわたってあまり焦点を当てていません。テーブルの認識は、2つの主要なタスク、つまりテーブル検出とテーブル構造の認識で構成されています。この問題のほとんどの以前の作業は、エンドツーエンドのソリューションを提供することなくタスクをフォーカスしたり、ドキュメント画像内の回転画像やノイズアーティファクトなどの実際のアプリケーション条件に注意を払ったりしません。最近の研究は、十分に大きなデータセットがないため、テーブル構造認識のタスクのための転送学習の使用と相まって、深い学習アプローチに向かう明確な傾向を示しています。このペーパーでは、マルチタイプTD-TSRという名前のマルチステージパイプラインを紹介します。これは、テーブル認識の問題のエンドツーエンドソリューションを提供します。テーブル検出に最先端のディープラーニングモデルを利用し、テーブルの境界に基づいて3つの異なるタイプのテーブルを区別します。テーブル構造の認識には、すべてのテーブルタイプで機能する決定論的な非DATA駆動型アルゴリズムを使用します。さらに、2つのアルゴリズムを提示します。 1つは、使用されていないテーブル用のテーブルと、使用されているテーブル構造認識アルゴリズムのベースである境界テーブル用です。 ICDAR 2019テーブル構造認識データセットでマルチタイプTD-TSRを評価し、新しい最先端を達成します。
完全に縁取られたテーブルのマルチタイプTD-TSR
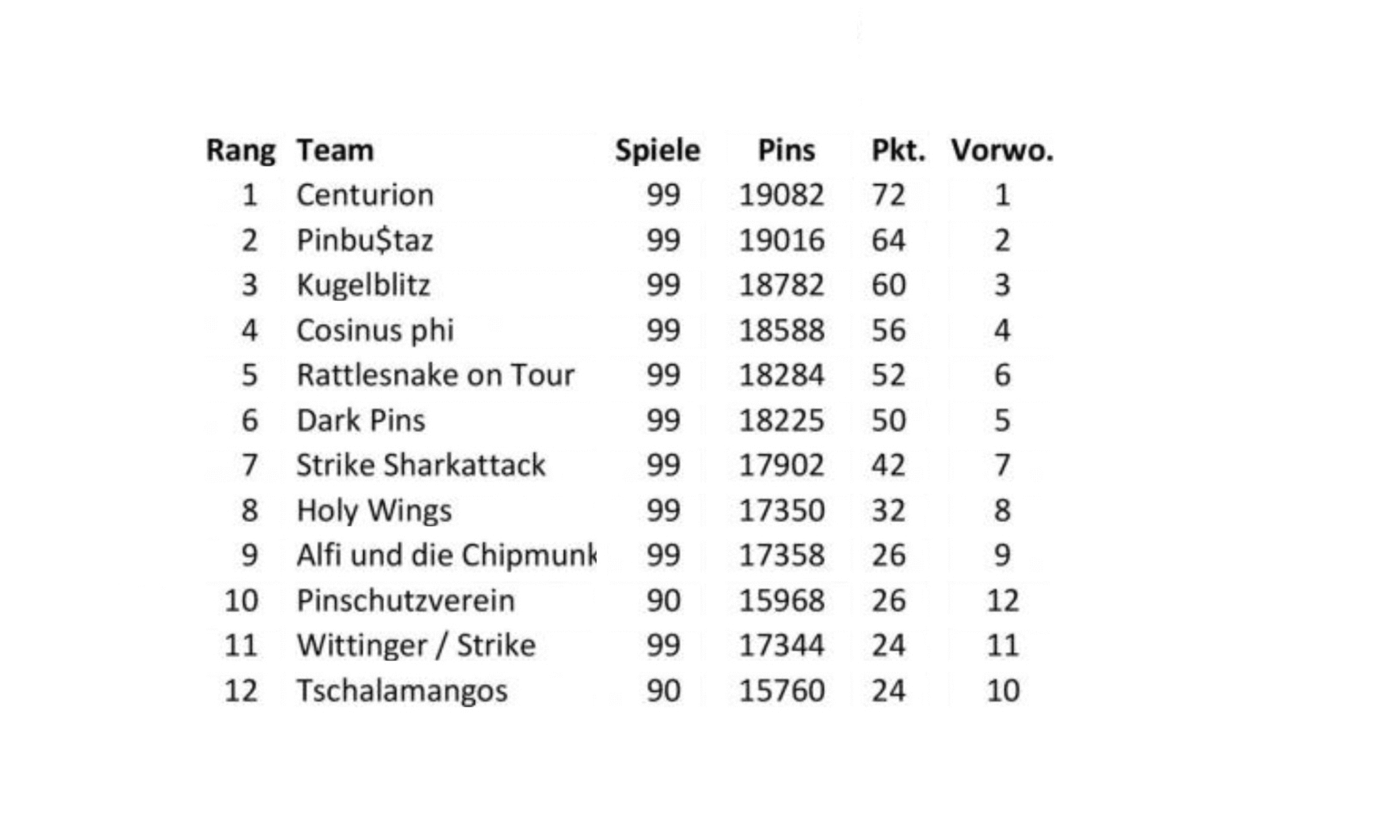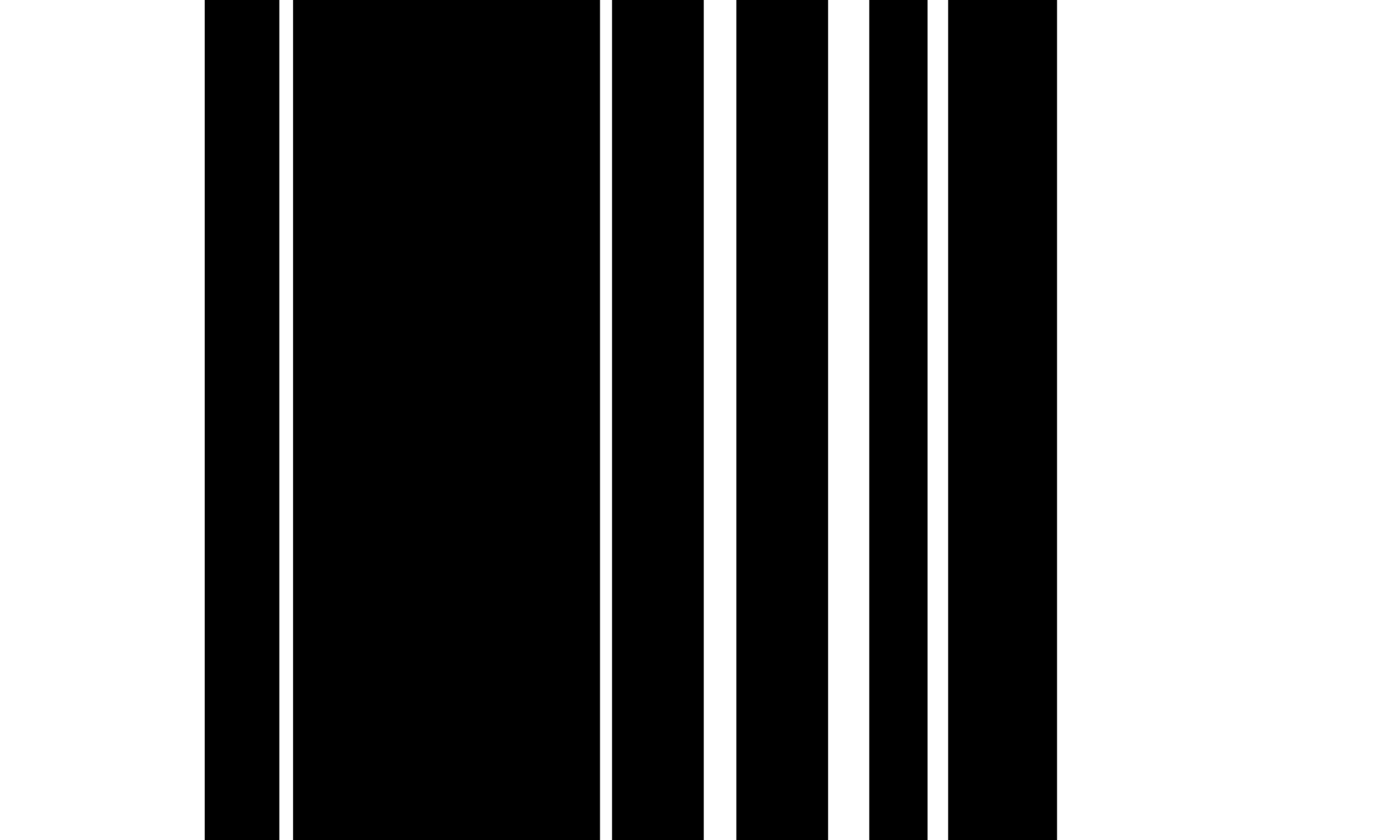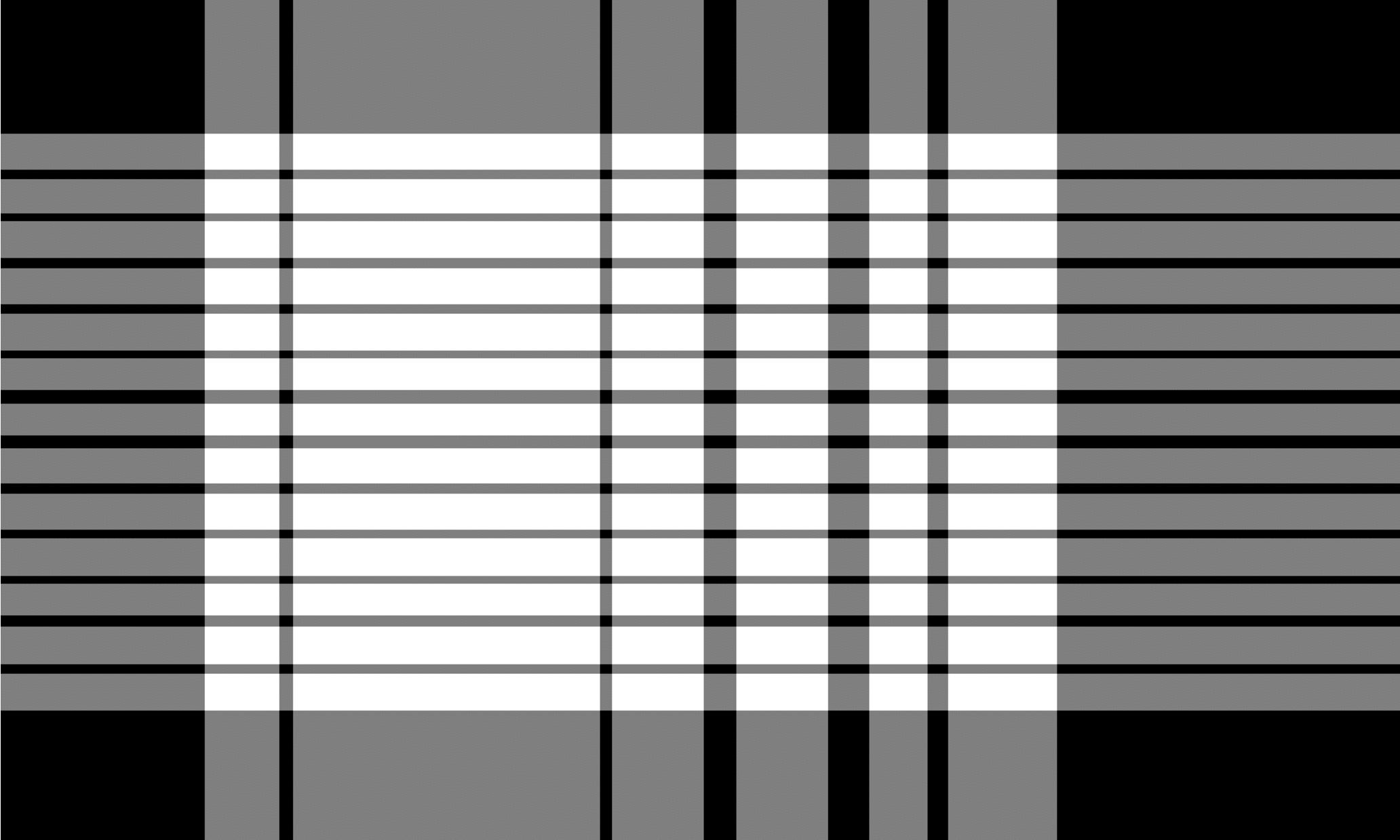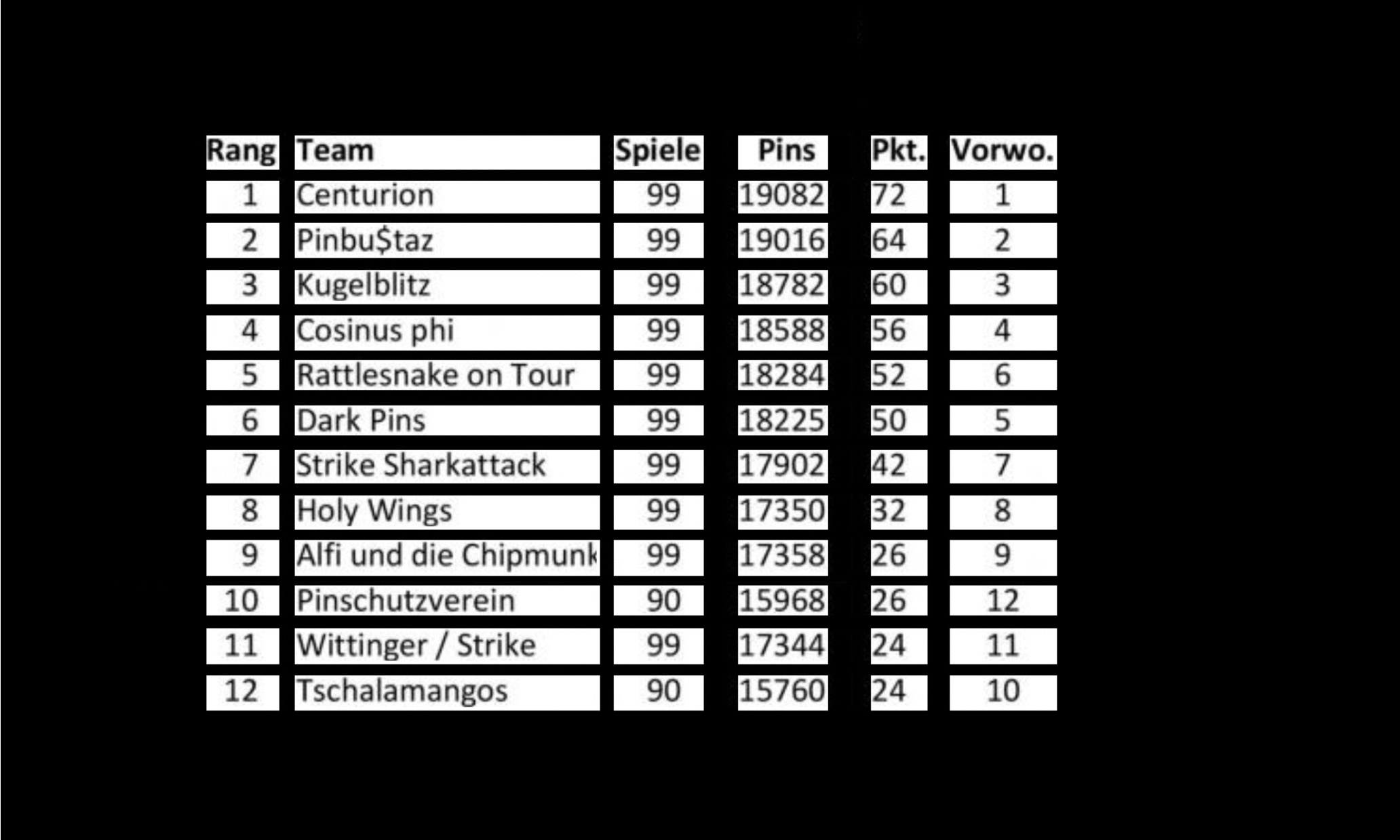
完全に縁取られたテーブルのTSRの場合、侵食と拡張操作を使用して、テキストや文字なしで行列グリッドセルの画像を抽出します。侵食カーネルは、一般に、全体のフォントサイズよりも長いが、最小のグリッドセルのサイズよりも短い薄い垂直および水平ストリップであり、特に最小のテーブル境界幅よりも幅が広くてはなりません。これらのカーネルサイズの制約を使用すると、テーブルの境界を保存しながら、テーブルからすべてのフォントと文字が削除されます。元のライン形状を復元するために、アルゴリズムは2つの侵食された画像のそれぞれに同じカーネルサイズを使用して拡張操作を適用し、垂直と水平線で2番目の画像を生成します。最後に、アルゴリズムは、「または `または` ``操作を少し使用してピクセル値を再インタイバーしてラスターセル画像を取得することにより、両方の画像を組み合わせます。次に、グリッドセル画像の輪郭関数を使用して、すべてのグリッドセルの境界ボックスを抽出します。
不正なテーブル上のマルチタイプTD-TSR
均質化されていないテーブルのTSRアルゴリズムは、境界テーブルのものと同様に機能しますが、侵食操作を異なる方法で使用します。侵食カーネルは、一般に、水平カーネルの水平サイズに完全な画像幅と垂直カーネルの垂直サイズが完全な画像の高さを含むという違いのある薄いストリップです。アルゴリズムは、垂直カーネルの場合、両方のカーネル全体を左から右、および水平カーネルの上から下まで個別にスライドさせます。このプロセス中に、文字やフォントが含まれていない空の行と列を探しています。結果の画像は反転し、最終出力を生成する「 `` `` `` `` ``操作によって組み合わされます。出力は、境界テーブルのTSRからのものと同様のグリッドセル画像であり、2つのグリッドセルの境界ボックスを表す2つの画像の重複領域があります。
部分的に境界のあるテーブル上のマルチタイプTD-TSR
縁取られていないテーブルと境界のないテーブルのアルゴリズムの主な目標は、境界のないケースに境界を追加し、境界のあるケースでラインを検出することにより、グリッドセルイメージを作成することです。テーブルが部分的にしか接していない場合、既存の境界線に直交方向に境界を追加するために、境界線の境界線を追加するために、境界線の境界線が既存の境界のみを見つけることができます。どちらのアプローチでも、グリッドセルの画像が不完全になります。
部分的に縁取られたテーブルのTSRは、境界テーブルと同じ侵食アルゴリズムを使用して既存の境界を検出しますが、グリッドセルを作成してテーブルイメージから境界を削除して境界線を取得するために使用しません。これにより、上記のバリアントに類似してグリッドセルイメージと輪郭を作成して、共有されていないテーブルにアルゴリズムを適用できます。このアプローチの重要な特徴は、境界線と境界のないテーブルの両方で機能することです。タイプに依存していることです。
テーブル構造の認識結果
ICDAR 19(トラックB2)
| iou | iou | iou | iou | 加重 |
|---|
| チーム | 0.6 | 0.7 | 0.8 | 0.9 | 平均 |
| cascadetabnet | 0.438 | 0.354 | 0.19 | 0.036 | 0.232 |
| nlpr-pal | 0.365 | 0.305 | 0.195 | 0.035 | 0.206 |
| マルチタイプTD-TSR | 0.589 | 0.404 | 0.137 | 0.015 | 0.253 |
説明書
構成
ソースコードは、次のライブラリの依存関係の下で開発されています
- pytorch = 1.7.0
- TorchVision = 0.8.1
- cuda = 10.1
- pyyaml = 5.1
検出2
テーブル検出モデルは、Detectron2に基づいています。このインストールガイドには、セットアップを行います。
画像アライメント前処理
画像アラインメント前処理ステップには、利用可能なスクリプトが1つあります。
画像アラインメント前処理アルゴリズムを1つのフォルダー内のすべての画像に適用するには、次のことを実行する必要があります。
次のパラメーターを使用します
--folderドキュメント画像を含む入力フォルダーを折りたたむ--outputデッケッシュされた画像の出力フォルダーを出力します
テーブル構造認識(TSR)
テーブル構造の認識のために、さまざまなアプローチの簡単なスクリプトを提供します
テーブル構造認識アルゴリズムを1つのフォルダー内のすべての画像に適用するには、次のことを実行する必要があります。
次のパラメーターを使用します
--folderテーブル画像を含む入力フォルダーの折りたたみパス--typeテーブル構造認識タイプtype in ["borderd", "unbordered", "partially", "partially_color_inv"]-
--img_outputプロセス画像の出力フォルダーパス --xml_output出力フォルダーパス境界ボックスを含むXMLファイルのパス
テーブル検出およびテーブル構造認識(TD&TSR)
フォローテーブル構造の認識を使用したテーブルの検出を忘れるために
テーブル構造の認識アルゴリズムを1つのフォルダー内のすべての画像に適用するには、次のことを実行する必要があります。
次のパラメーターを使用します
--folderテーブル画像を含む入力フォルダーの折りたたみパス--typeテーブル構造認識タイプtype in ["borderd", "unbordered", "partially", "partially_color_inv"]-
--tsr_img_output処理されたテーブル画像の出力フォルダーパス --td_img_output生成されたテーブルカットアウトの出力フォルダーパス--xml_output出力フォルダーバウンディングボックスを含むテーブルおよびセルのXMLファイルのパス- -detectron2構成ファイルの
--configパステーブル検出用 --yaml detectron2 yamlファイルのパステーブル検出用--weightsテーブル検出のためのDetectron2モデルの重量の重量パス
評価
テーブル構造認識アルゴリズムを評価するには、次のスクリプトを提供します。
評価を適用するには、XML-Formatのテーブル画像とそのラベルは同じ名前でなければならず、単一のフォルダーにある必要があります。評価は以下で開始できます。
次のパラメーターで
- -.xml形式のテーブル画像とラベルを含むデータ
--datasetデータセットフォルダーパス
データを取得します
- テーブル画像や注釈を含むテーブル構造認識のテストデータセットはこちらからダウンロードできます
- テーブル検出Detectron2モデルの重みと構成ファイルはここからダウンロードできます
引用
@misc{fischer2021multitypetdtsr,
title={Multi-Type-TD-TSR - Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations},
author={Pascal Fischer and Alen Smajic and Alexander Mehler and Giuseppe Abrami},
year={2021},
eprint={2105.11021},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


