Multi-type-td-tsr
Visítelo en el código fuente de nuestro documento: Tablas de extracción multi-TD-TD-TSR de imágenes de documentos utilizando una tubería de etapas múltiples para la detección de la tabla y el reconocimiento de la estructura de la tabla
Descripción
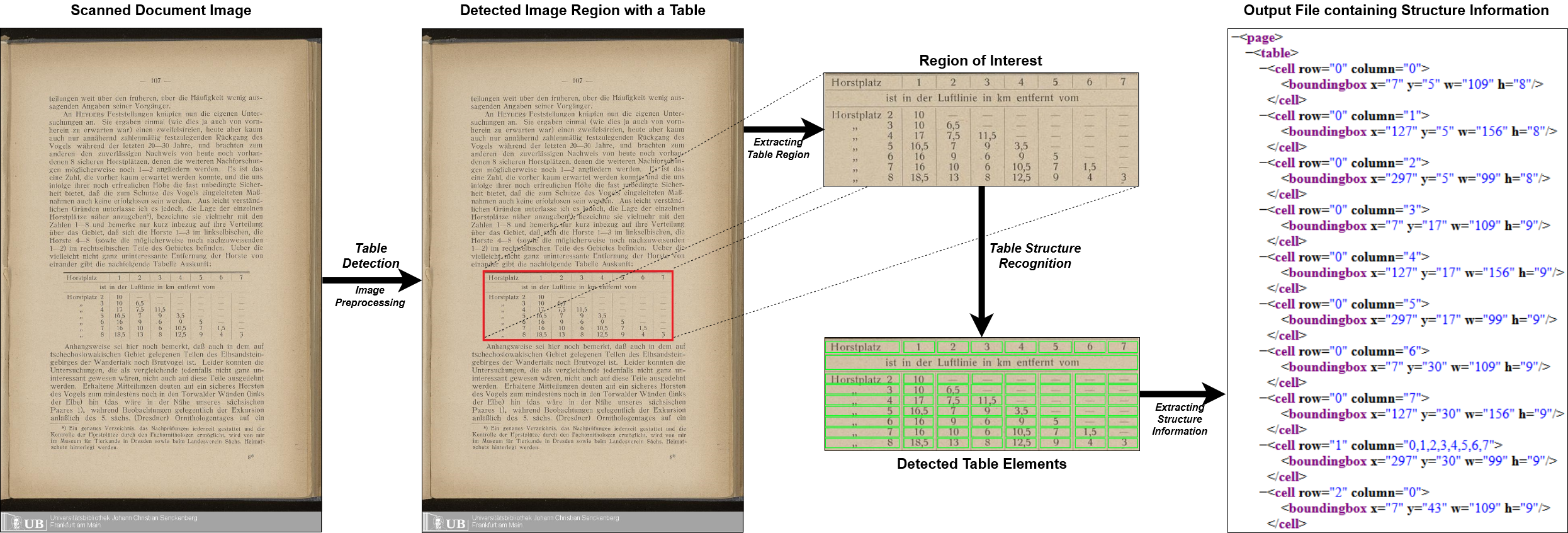
Multi-type-td-tsr toda la tubería
A medida que las tendencias globales están cambiando hacia industrias basadas en datos, la demanda de algoritmos automatizados que puede convertir imágenes digitales de documentos escaneados en información legible por máquina está creciendo rápidamente. Además de la oportunidad de digitalización de datos para la aplicación de herramientas analíticas de datos, también existe una mejora masiva hacia la automatización de procesos, lo que previamente requeriría una inspección manual de los documentos. Aunque la introducción de las tecnologías de reconocimiento de caracteres ópticos (OCR) resolvió principalmente la tarea de convertir caracteres legibles por humanos de imágenes en caracteres legibles por máquina, la tarea de extraer semántica de tabla se ha centrado menos a lo largo de los años. El reconocimiento de tablas consta de dos tareas principales, a saber, la detección de la tabla y el reconocimiento de la estructura de la tabla. La mayoría de los trabajos anteriores en este problema se enfocan en la tarea sin ofrecer una solución de extremo a extremo o prestar atención a condiciones de aplicación reales como imágenes rotadas o artefactos de ruido dentro de la imagen del documento. El trabajo reciente muestra una tendencia clara hacia los enfoques de aprendizaje profundo junto con el uso del aprendizaje de transferencia para la tarea del reconocimiento de la estructura de la tabla debido a la falta de conjuntos de datos suficientemente grandes. En este artículo presentamos una tubería de varias etapas llamada Multi-Type-TD-TSR, que ofrece una solución de extremo a extremo para el problema del reconocimiento de la tabla. Utiliza modelos de aprendizaje profundo de última generación para la detección de la tabla y diferencia entre 3 tipos diferentes de tablas basadas en las bordes de las tablas. Para el reconocimiento de la estructura de la tabla, utilizamos un algoritmo determinista impulsado por los datos, que funciona en todos los tipos de tabla. También presentamos dos algoritmos. Uno para tablas inundadas y otra para tablas limitadas, que son la base del algoritmo de reconocimiento de estructura de tabla usada. Evaluamos el conjunto de datos de reconocimiento de estructura de tabla ICDAR 2019 y logramos un nuevo estado de arte.
Multi-type-td-tsr en tablas totalmente limitadas
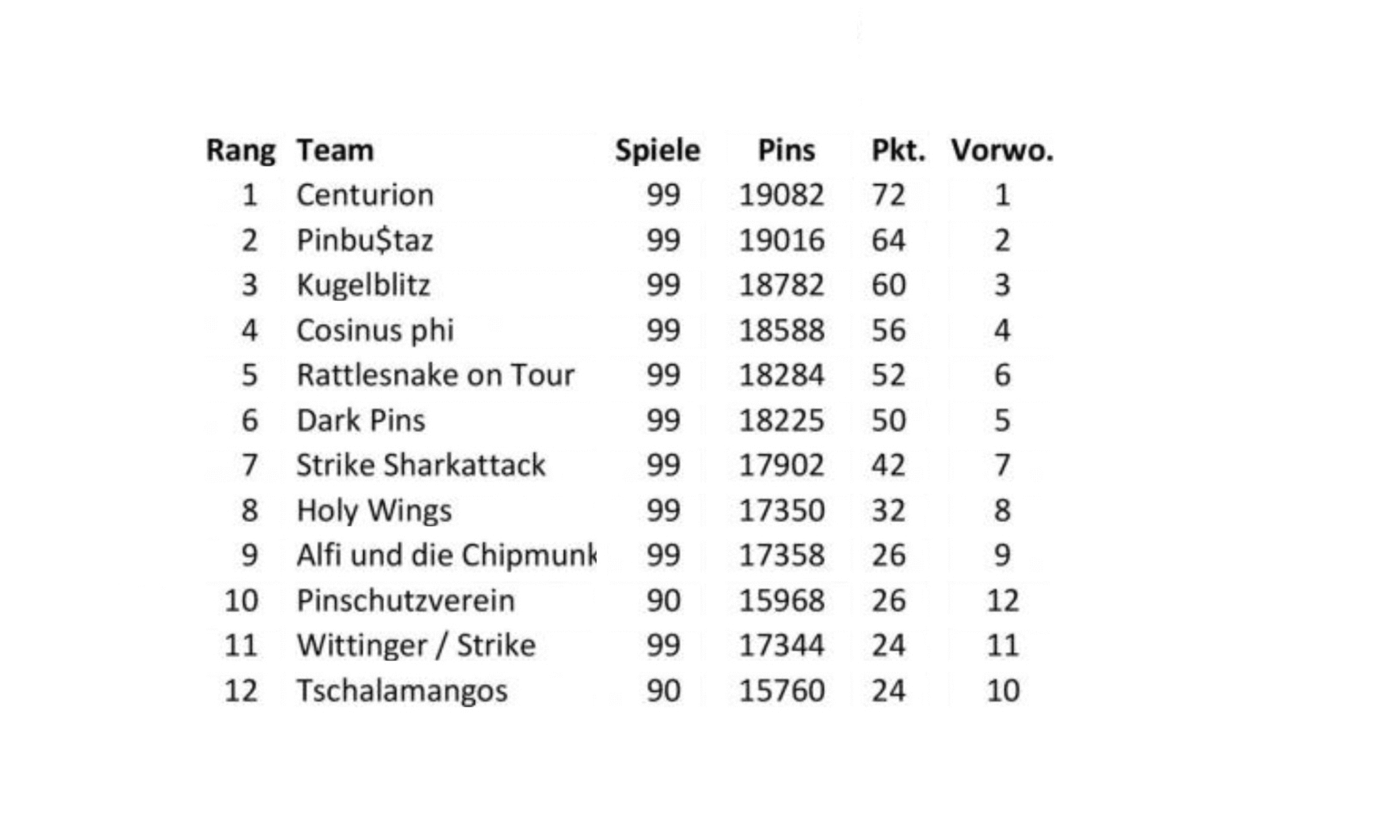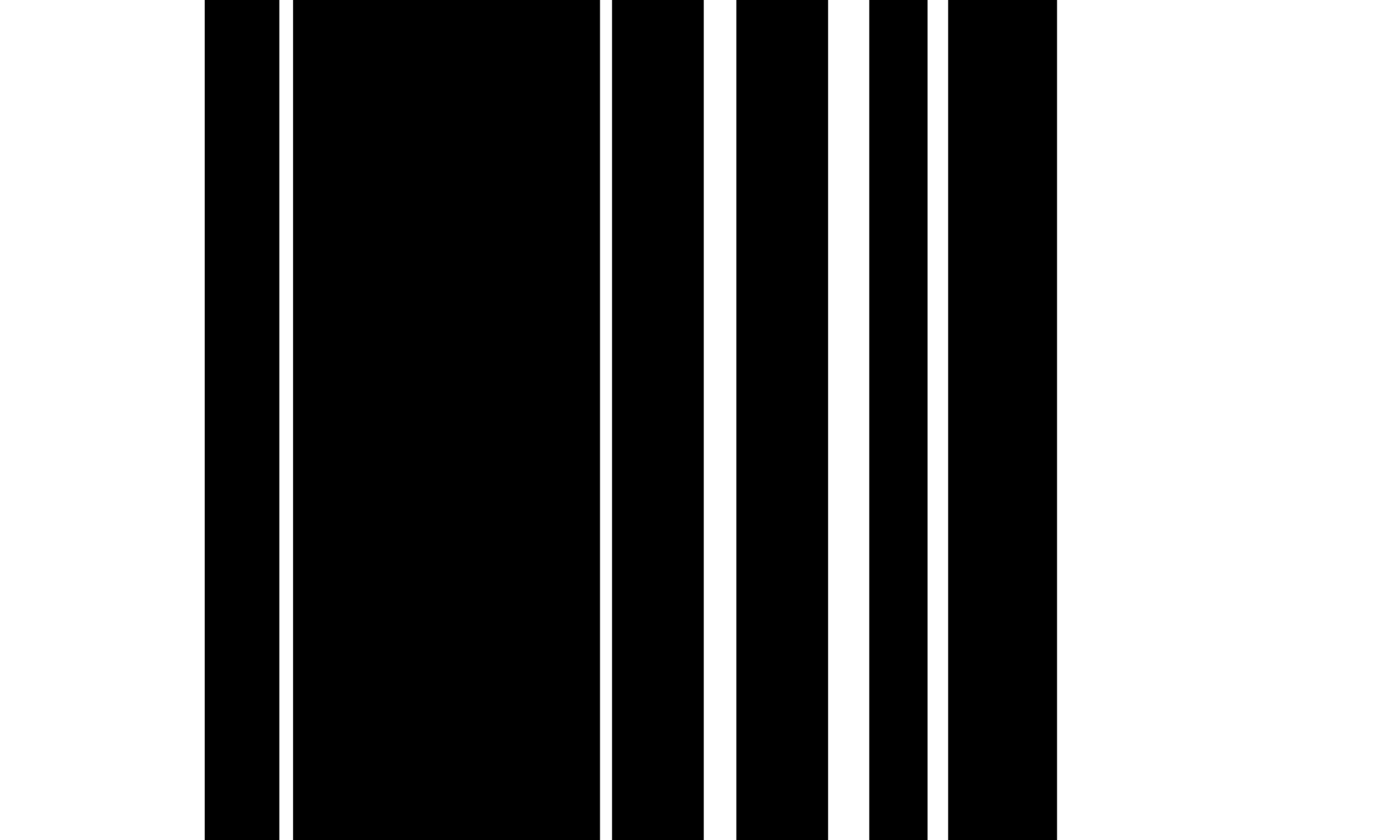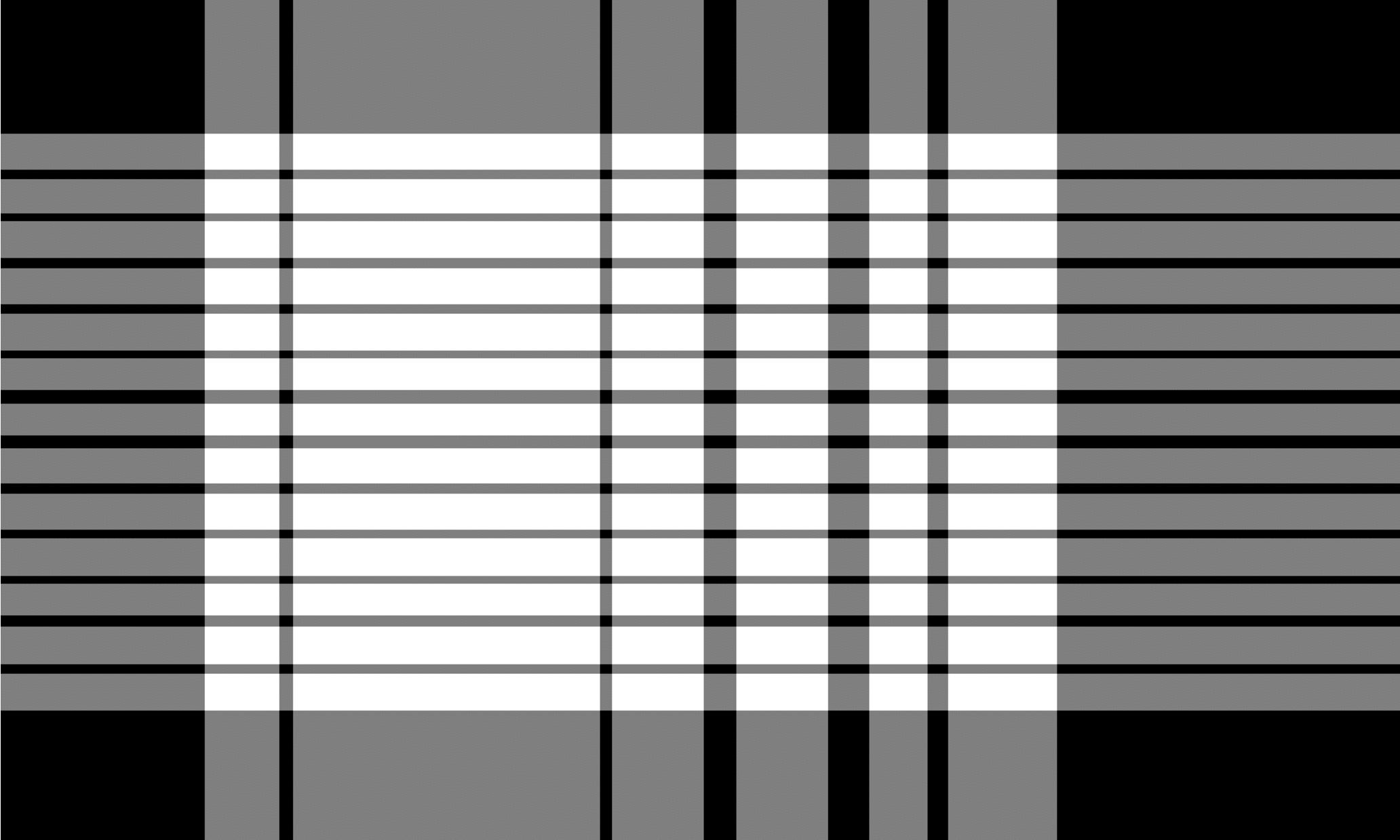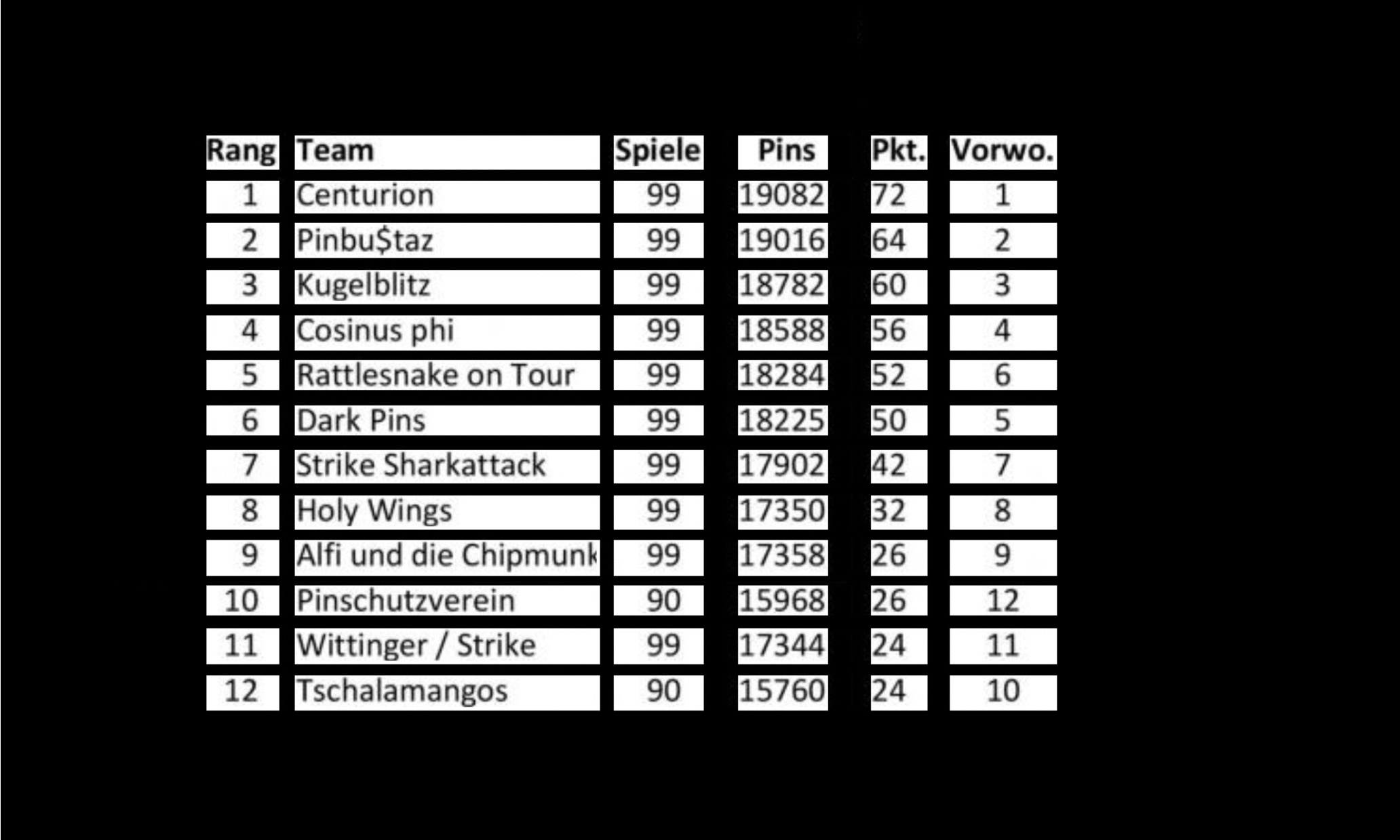
Para TSR en tablas completamente bordeadas, utilizamos la operación de erosión y dilatación para extraer la imagen de la celda de cuadrícula de columna de fila sin ningún texto o caracteres. Los núcleos de erosión son generalmente delgadas tiras verticales y horizontales que son más largas que el tamaño de fuente general pero más cortos que el tamaño de la celda de la cuadrícula más pequeña y, en particular, no deben ser más anchas que el ancho del borde de la mesa más pequeño. El uso de estas restricciones de tamaño del núcleo da como resultado la operación de erosión que elimina todas las fuentes y caracteres de la tabla mientras preservan los bordes de la tabla. Para restaurar la forma de línea original, el algoritmo aplica la operación de dilatación utilizando el mismo tamaño del núcleo en cada una de las dos imágenes erosionadas, produciendo una imagen con vertical y un segundo con líneas horizontales. Finalmente, el algoritmo combina ambas imágenes utilizando una operación `` `` ``` y reinvertiendo los valores de píxeles para obtener una imagen de celda ráster. Luego usamos la función de contornos en la imagen de la célula de la cuadrícula para extraer los boxes delimitadores para cada celda de la cuadrícula.
Multi-type-td-tsr en mesas sin borde
El algoritmo TSR para tablas sin borde funciona de manera similar al de las tablas limitadas, pero utiliza la operación de erosión de una manera diferente. El núcleo de erosión es en general una tira delgada con la diferencia de que el tamaño horizontal del núcleo horizontal incluye el ancho de la imagen completo y el tamaño vertical del núcleo vertical la altura de la imagen completa. El algoritmo desliza ambos núcleos independientemente sobre toda la imagen de izquierda a derecha para el núcleo vertical, y de arriba a abajo para el núcleo horizontal. Durante este proceso, busca filas y columnas vacías que no contengan ningún personaje o fuente. Las imágenes resultantes están invertidas y combinadas por una operación `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` `` ``,,` `` `` `` `` `,, `` `` `` ``,` `` `` `` `, `` `` `` `` `` `` `ana, final. La salida es una imagen de células de cuadrícula similar a la de TSR para tablas limitadas, donde las áreas superpuestas de las dos imágenes resultantes representan las cajas delimitadoras para cada celda de la cuadrícula.
Multi-type-td-tsr en tablas parcialmente limitadas
El objetivo principal de nuestros algoritmos para las tablas limitadas y sin borde es crear una imagen de celda de cuadrícula agregando fronteras en el caso sin borde y detectando líneas en el caso limitado. Si una tabla solo está parcialmente bordeada, entonces se evita que el algoritmo sin borde agregue bordes en dirección ortogonal a las fronteras existentes, mientras que el algoritmo limitado solo puede encontrar las fronteras existentes. Ambos enfoques dan como resultado imágenes de células de cuadrícula incompletas.
TSR para tablas parcialmente limitadas utiliza el mismo algoritmo de erosión que en las tablas limitadas para detectar las fronteras existentes, pero sin usarlas para crear una celda de la cuadrícula, pero para eliminar los bordes de la imagen de la mesa para obtener una mesa sin borde. Esto permite aplicar el algoritmo para tablas sin borde para crear la imagen y los contornos de células de cuadrícula por analogía a las variantes discutidas anteriormente. Una característica clave de este enfoque es que funciona con tablas fronterizas como de bajo borde: es independiente del tipo.
Resultados de la estructura de la tabla
ICDAR 19 (pista B2)
| IOU | IOU | IOU | IOU | Ponderado |
|---|
| Equipo | 0.6 | 0.7 | 0.8 | 0.9 | Promedio |
| Cascadetabnet | 0.438 | 0.354 | 0.19 | 0.036 | 0.232 |
| Pal de NLPR | 0.365 | 0.305 | 0.195 | 0.035 | 0.206 |
| Multi-type-td-tsr | 0.589 | 0.404 | 0.137 | 0.015 | 0.253 |
Instrucciones
Configuraciones
El código fuente se desarrolla en las siguientes dependencias de la biblioteca
- Pytorch = 1.7.0
- Visión de antorchas = 0.8.1
- CUDA = 10.1
- Pyyaml = 5.1
Detectrono 2
El modelo de detección de tabla se basa en Detectron2 Siga esta guía de instalación para la configuración.
Preprocesamiento de alineación de imágenes
Para el paso de preprocesamiento de alineación de imágenes hay un script disponible:
Para aplicar el algoritmo de preprocesamiento de alineación de imágenes a todas las imágenes en una carpeta, debe ejecutar:
con los siguientes parámetros
-
--folder la carpeta de entrada que incluye imágenes de documentos -
--output la carpeta de salida para las imágenes Deskewed
Reconocimiento de la estructura de la tabla (TSR)
Para el reconocimiento de la estructura de la tabla ofrecemos un script simple para diferentes enfoques
Para aplicar un algoritmo de reconocimiento de estructura de tabla a todas las imágenes en una carpeta, debe ejecutar:
con los siguientes parámetros
-
--folder placa de la carpeta de entrada, incluidas las imágenes de la tabla -
--type the Table Structure Reconocido type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--img_output ruta de carpeta de salida para las imágenes procesadas -
--xml_output ruta de la carpeta de salida para los archivos XML que incluyen cuadros limitados
Detección de tabla y reconocimiento de estructura de tabla (TD & TSR)
Para aplicar la detección de la tabla con un reconocimiento de estructura de tabla seguido
Para aplicar un algoritmo de reconocimiento de estructura de tabla a todas las imágenes en una carpeta, debe ejecutar:
con los siguientes parámetros
-
--folder placa de la carpeta de entrada, incluidas las imágenes de la tabla -
--type the Table Structure Reconocido type in ["borderd", "unbordered", "partially", "partially_color_inv"] -
--tsr_img_output ruta de carpeta de salida para las imágenes de la tabla procesadas -
--td_img_output ruta de carpeta de salida para los recortes de tabla producidos -
--xml_output ruta de la carpeta de salida para los archivos XML para tablas y celdas que incluyen cuadros de límite - -ruta
--config del archivo de configuración de Detectron2 para la detección de la tabla - -ruta
--yaml del archivo yaml de detectron2 para la detección de la tabla -
--weights de los pesos del modelo Detectron2 para la detección de la tabla
Evaluación
Para evaluar el algoritmo de reconocimiento de la estructura de la tabla proporcionamos el siguiente script:
Para aplicar la evaluación, las imágenes de la tabla y sus etiquetas en formato XML deben ser el mismo nombre y deben estar en una sola carpeta. La evaluación podría ser iniciada por:
con el siguiente parámetro
- -Ruta de la carpeta de datos de
--dataset que contiene imágenes de tabla y etiquetas en formato .xml
Obtener datos
- El conjunto de datos de prueba para el reconocimiento de la estructura de la tabla, incluidas las imágenes de la tabla y las anotaciones, se pueden descargar aquí
- Detección de tabla Detectron2 Los pesos del modelo y los archivos de configuración se pueden descargar aquí
Citación
@misc{fischer2021multitypetdtsr,
title={Multi-Type-TD-TSR - Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations},
author={Pascal Fischer and Alen Smajic and Alexander Mehler and Giuseppe Abrami},
year={2021},
eprint={2105.11021},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


