UniCATS CTX txt2vec
1.0.0
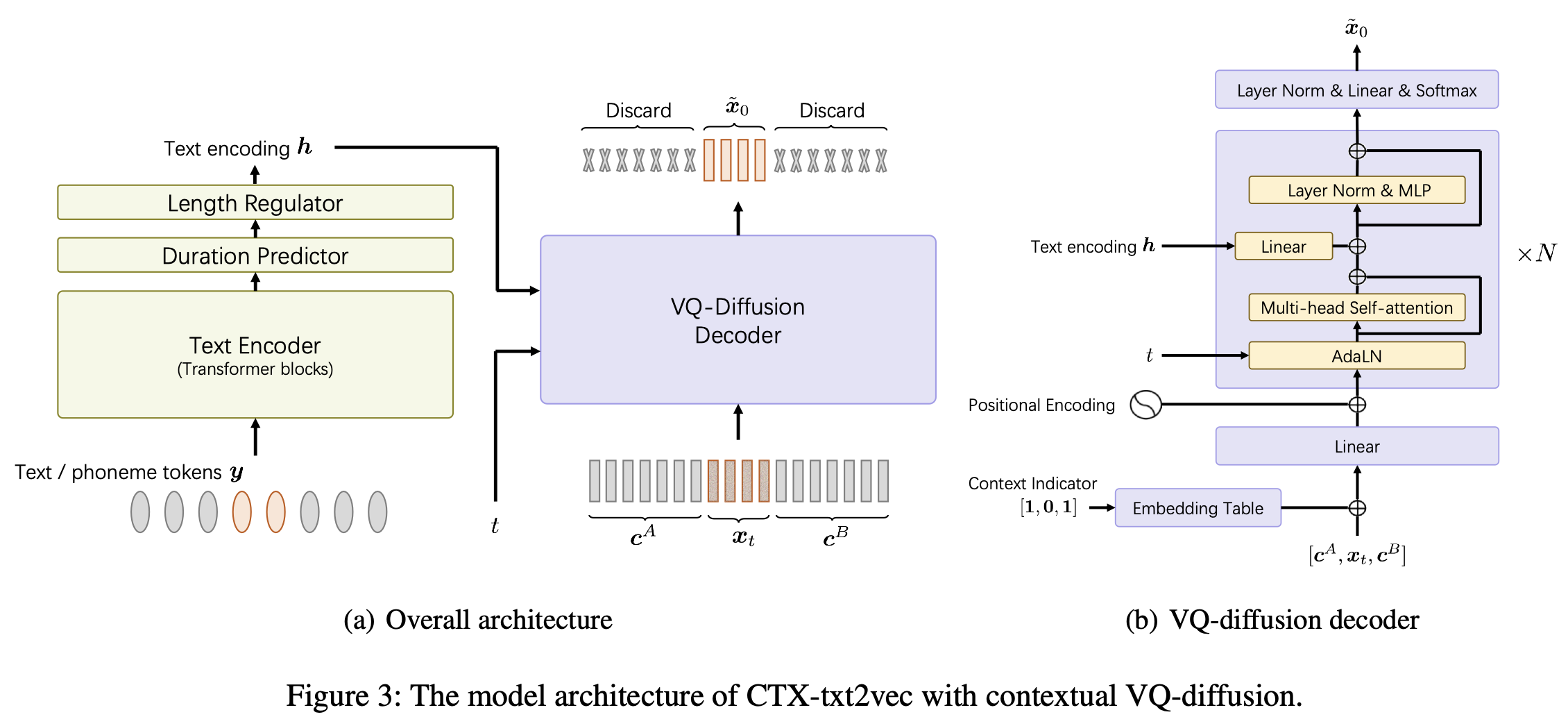
Esta é a implementação oficial do modelo CTX-TXT2VEC TTS nos unicats de papel AAAI-2024: uma estrutura de texto para fala com consciência de contexto unificada com difusão e vocoding contextuais VQ.
Este repo é testado no Python 3.7 no Linux. Você pode configurar o ambiente com conda
# Install required packages
conda create -n ctxt2v python=3.7 # or any name you like
conda activate ctxt2v
pip install -r requirements.txt Toda vez que você insere este projeto, você pode ativar conda activate ctxt2v ou source path.sh .
Além disso, você pode executar chmod +x utils/* para garantir que esses scips sejam executáveis.
Aqui pegamos o pipeline de preparação do Libritts, por exemplo. Outros conjuntos de dados podem ser configurados da mesma maneira.
data/ no diretório do projeto. O conteúdo é o seguinte: ├── train_all
│ ├── duration # the integer duration for each utterance. Frame shift is 10ms.
│ ├── feats.scp # the VQ index for each utterance. Will be explained later.
│ ├── text # the phone sequence for each utterance
│ └── utt2num_frames # the number of frames of each utterance.
├── eval_all
│ ... # similar four files
│── dev_all
│ ...
└── lang_1phn
└── train_all_units.txt # mapping between valid phones and their indexes
feats.scp é o especificador de recurso no estilo Kaldi apontando para feats/label/.../feats.ark . Também fornecemos on -line (432 MB), então faça o download e descompacte para feats no diretório do projeto. Esses recursos são os índices 1-D dos recursos VQ-WAV2VEC. Você pode verificar a forma dos recursos de utils/feat-to-shape.py scp:feats/label/dev_all/feats.scp | head . O código de código feats/vqidx/codebook.npy tem forma [2, 320, 256] .Ou seja, extraímos Indxes de livro de código discretos usando o modelo VQ-WAV2VEC da FairSeq , a versão Kmeans Librispeech , que continha 2 grupos de indexos inteiros, cada um variando de 0 a 319. Em seguida, encontramos as ocorrências desses pares e o índice e o Índice2 e o Index-O-Índice2 e o Index-O-Índice2 e o Index-O-Índice2.
feats/vqidx/label2vqidx. Utilizamos os rótulos 23632 para treinar o modelo VQ-difusão.
Depois de construir os diretórios corretamente, o modelo pode ser treinado.
Treinar o modelo CTX-TXT2VEC pode ser simplesmente feito por
python train.py --name Libritts --config_file configs/Libritts.yaml --num_node 1 --tensorboard --auto_resume onde --name especifica o nome do diretório de saída. Confira configs/Libritts.yaml de configurações detalhadas. O treinamento multi-GPU é tratado automaticamente pelo programa (padrão para usar todos os dispositivos visíveis).
Após o início do treinamento, os pontos de verificação e os logs serão salvos em OUTPUT/Libritts .
A decodificação do CTX-TXT2VEC sempre depende de avisos que fornecem informações contextuais. Em outras palavras, antes de decodificar, deve haver um arquivo utt2prompt que se parece:
1089_134686_000002_000001 1089_134686_000032_000008
1089_134686_000007_000005 1089_134686_000032_000008
1089_134686_000009_000003 1089_134686_000032_000008
1089_134686_000009_000008 1089_134686_000032_000008
1089_134686_000015_000003 1089_134686_000032_000008
onde toda linha é organizada como utt-to-synthesize prompt-utt . As chaves utt-to-synthesize e prompt-utt devem estar presentes no feats.scp para indexação.
Recomendamos o uso do arquivo oficial UTT2PROMPT para o conjunto de testes B no artigo. Você pode baixar isso e salvar em data/eval_all/utt2prompt .
Depois disso, a decodificação com o contexto presa (também conhecida como continuação) pode ser realizada por
python continuation.py --eval-set eval_all
# will only synthesize utterances in `utt2prompt`. Check the necessary files in `data/${eval_set}`. Os Indexes VQ decodificados (2-DIM) serão salvos para OUTPUT/Libritts/syn/${eval_set}/ .
Observe que o modelo realmente amostra de 23631 "rótulos" distintos de VQ. Neste código, transformamos-o de volta aos índices VQ 2-DIM usando
feats/vqidx/label2vqidx.
Para que o vocoding da forma de onda, é altamente recomendável a contraparte "CTX-VEC2WAV". Você pode configurar CTX-VEC2WAV
git clone https://github.com/cantabile-kwok/UniCATS-CTX-vec2wav.gite depois siga a instrução ambiental lá.
Após decodificar para os índices de VQ, o vocoding pode ser alcançado por
syn_dir= $PWD /OUTPUT/Libritts/syn/eval_all/
utt2prompt_file= $PWD /data/eval_all/utt2prompt
v2w_dir=/path/to/CTX-vec2wav/
cd $v2w_dir || exit 1 ;
source path.sh
# now, in CTX-vec2wav's environment
feat-to-len.py scp: $syn_dir /feats.scp > $syn_dir /utt2num_frames
# construct acoustic prompt specifier (mel spectrograms) using utt2prompt
python ./local/get_prompt_scp.py feats/normed_fbank/eval_all/feats.scp ${utt2prompt_file} > $syn_dir /prompt.scp
decode.py --feats-scp $syn_dir /feats.scp
--prompt-scp $syn_dir /prompt.scp
--num-frames $syn_dir /utt2num_frames
--outdir $syn_dir /wav/
--checkpoint /path/to/checkpointDurante o desenvolvimento, os seguintes repositórios foram referidos:
ctx_text2vec/modeling/transformers/espnet_nets e scripts utilitários nos utils .utils .

