UniCATS CTX txt2vec
1.0.0
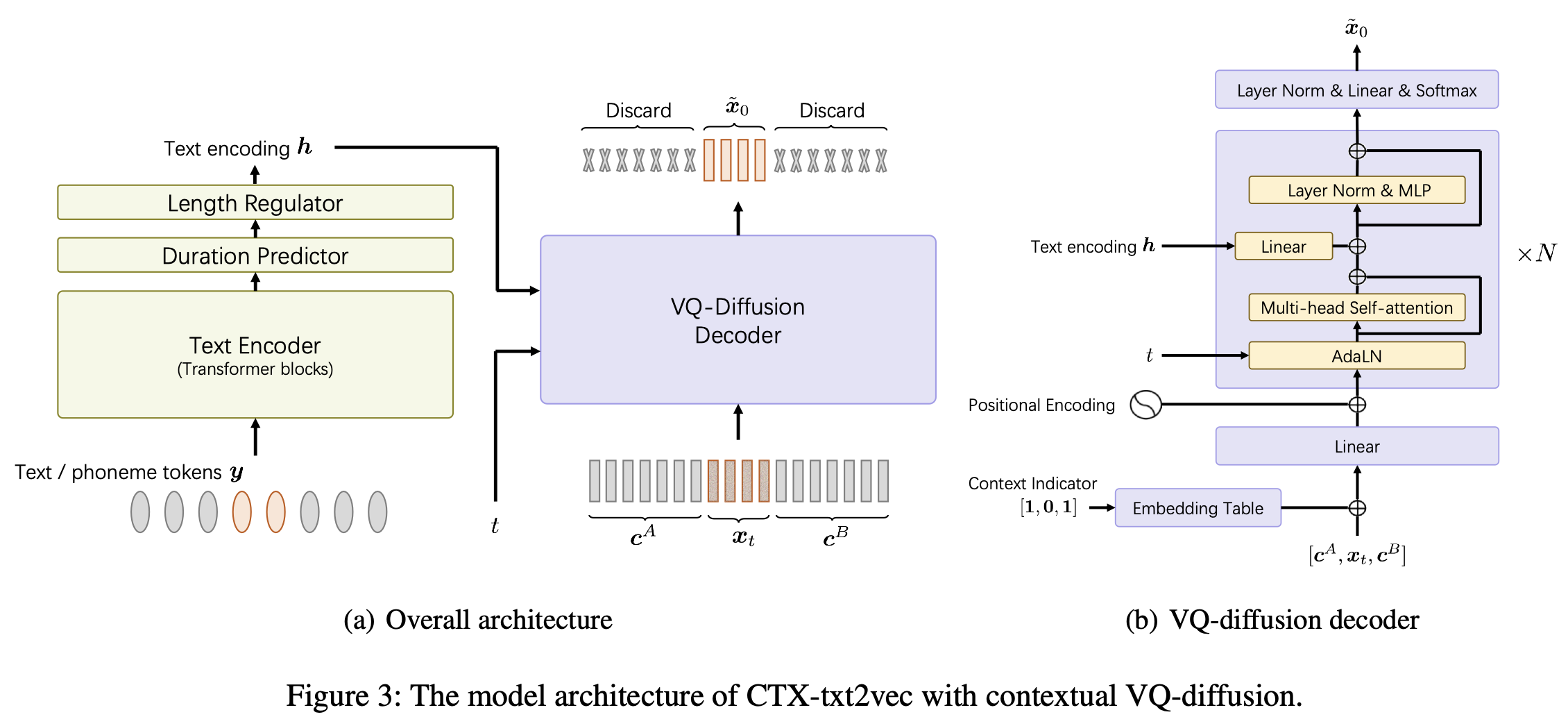
Dies ist die offizielle Implementierung des CTX-TXT2VEC -TTS-Modells im AAAI-2024-Papier-Unicats: ein einheitlicher kontextbewusster Text-zu-Sprache-Framework mit kontextbezogenem VQ-Diffusion und Vocoding.
Dieses Repo wird auf Python 3.7 unter Linux getestet. Sie können die Umgebung mit Conda einrichten
# Install required packages
conda create -n ctxt2v python=3.7 # or any name you like
conda activate ctxt2v
pip install -r requirements.txt Jedes Mal, wenn Sie dieses Projekt eingeben, können Sie conda activate ctxt2v oder source path.sh durchführen.
Außerdem können Sie chmod +x utils/* durchführen, um sicherzustellen, dass diese Scipts ausführbar sind.
Hier nehmen wir zum Beispiel die Libritts -Vorbereitungspipeline. Andere Datensätze können auf die gleiche Weise eingerichtet werden.
data/ im Projektverzeichnis. Der Inhalt ist wie folgt: ├── train_all
│ ├── duration # the integer duration for each utterance. Frame shift is 10ms.
│ ├── feats.scp # the VQ index for each utterance. Will be explained later.
│ ├── text # the phone sequence for each utterance
│ └── utt2num_frames # the number of frames of each utterance.
├── eval_all
│ ... # similar four files
│── dev_all
│ ...
└── lang_1phn
└── train_all_units.txt # mapping between valid phones and their indexes
feats.scp der Feature-Feature-Spezifizierer im Kaldi-Stil, der auf feats/label/.../feats.ark zeigt. Wir stellen es auch online (432 MB) an. Bitte laden Sie es herunter und entpacken Sie es zu feats im Projektverzeichnis. Diese Merkmale sind die 1-D-Abflachungsindizes der VQ-Wav2VEC-Funktionen. Sie können die Form der Funktionen nach utils/feat-to-shape.py scp:feats/label/dev_all/feats.scp | head überprüfen. utils/feat-to-shape.py scp:feats/label/dev_all/feats.scp | head . Das Codebebook feats/vqidx/codebook.npy hat Form [2, 320, 256] .That is, we extracted discrete codebook indxes using fairseq's vq-wav2vec model , the kmeans Librispeech version , which contained 2 groups of integer indexes each ranging from 0 to 319. We then find the occurrences of these pairs and label them using another index, which counts to 23632. The mapping between this label index and original vq-wav2vec codebook index can be found at
feats/vqidx/label2vqidx. Wir verwenden die 23632-Etiketten, um das VQ-Diffusion-Modell zu trainieren.
Nach dem richtigen Bau der Verzeichnisse kann das Modell geschult werden.
Training Das CTX-TXT2VEC-Modell kann einfach von durchgeführt werden
python train.py --name Libritts --config_file configs/Libritts.yaml --num_node 1 --tensorboard --auto_resume Wo --name gibt den Namen des Ausgabeverzeichnisses an. Weitere detaillierte Konfigurationen finden Sie auf configs/Libritts.yaml . Das Multi-GPU-Training wird vom Programm automatisch abgeschlossen (Standard für die Verwendung aller sichtbaren Geräte).
Nach dem Start des Trainings werden Kontrollpunkte und Protokolle in OUTPUT/Libritts gespeichert.
Die Dekodierung von CTX-TXT2VEC stützt sich immer auf Eingabeaufforderungen, die kontextbezogene Informationen liefern. Mit anderen Worten, vor dem Dekodieren sollte es eine utt2prompt -Datei geben, die aussieht:
1089_134686_000002_000001 1089_134686_000032_000008
1089_134686_000007_000005 1089_134686_000032_000008
1089_134686_000009_000003 1089_134686_000032_000008
1089_134686_000009_000008 1089_134686_000032_000008
1089_134686_000015_000003 1089_134686_000032_000008
wo jede Zeile als utt-to-synthesize prompt-utt organisiert ist. Die Tasten utt-to-synthesize und prompt-utt sollten beide für die Indexierung in feats.scp vorhanden sein.
Wir empfehlen, die offizielle UTT2PROMPT -Datei für den Testsatz B im Papier zu verwenden. Sie können das herunterladen und auf data/eval_all/utt2prompt speichern.
Danach kann die Dekodierung mit dem Kontext (auch bekannt als Fortsetzung) dekodiert werden
python continuation.py --eval-set eval_all
# will only synthesize utterances in `utt2prompt`. Check the necessary files in `data/${eval_set}`. Die dekodierten VQ-Indexes (2-DIM) werden in OUTPUT/Libritts/syn/${eval_set}/ gespeichert.
Beachten Sie, dass das Modell tatsächlich aus 23631 unterschiedlichen VQ -Labels probiert. In diesem Code transformieren wir es in 2-DIM-VQ-Indizes mithilfe von
feats/vqidx/label2vqidx.
Für die Vokodierung der Wellenform ist das Gegenstück "CTX-VEC2WAV" sehr empfohlen. Sie können CTX-VEC2WAV durch einrichten
git clone https://github.com/cantabile-kwok/UniCATS-CTX-vec2wav.gitund befolgen Sie dann den Umgebungsunterricht dort.
Nach dem Dekodieren von VQ -Indizes kann das Vokodieren durch erreicht werden
syn_dir= $PWD /OUTPUT/Libritts/syn/eval_all/
utt2prompt_file= $PWD /data/eval_all/utt2prompt
v2w_dir=/path/to/CTX-vec2wav/
cd $v2w_dir || exit 1 ;
source path.sh
# now, in CTX-vec2wav's environment
feat-to-len.py scp: $syn_dir /feats.scp > $syn_dir /utt2num_frames
# construct acoustic prompt specifier (mel spectrograms) using utt2prompt
python ./local/get_prompt_scp.py feats/normed_fbank/eval_all/feats.scp ${utt2prompt_file} > $syn_dir /prompt.scp
decode.py --feats-scp $syn_dir /feats.scp
--prompt-scp $syn_dir /prompt.scp
--num-frames $syn_dir /utt2num_frames
--outdir $syn_dir /wav/
--checkpoint /path/to/checkpointWährend der Entwicklung wurden die folgenden Repositorys verwiesen:
ctx_text2vec/modeling/transformers/espnet_nets und Utility -Skripte in utils .utils .

