UniCATS CTX txt2vec
1.0.0
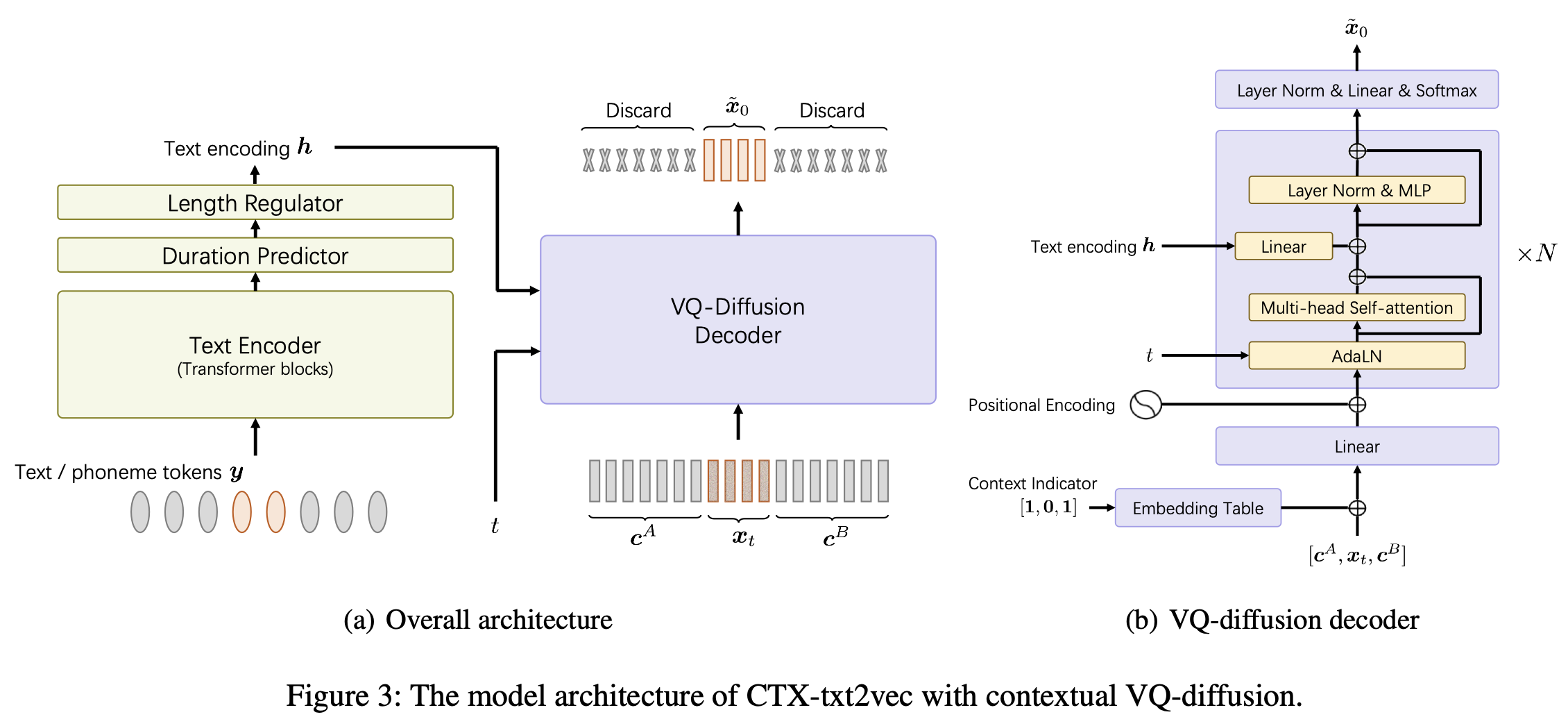
이것은 AAAI-2024 Paper Unicats에서 CTX-TXT2VEC TTS 모델의 공식적 구현 : 상황에 맞는 VQ 분해 및 보컬을 갖춘 통합 컨텍스트 인식 텍스트 음성 프레임 워크입니다.
이 repo는 Linux의 Python 3.7 에서 테스트됩니다. 콘다로 환경을 설정할 수 있습니다
# Install required packages
conda create -n ctxt2v python=3.7 # or any name you like
conda activate ctxt2v
pip install -r requirements.txt 이 프로젝트에 들어갈 때마다 conda activate ctxt2v 또는 source path.sh 수행 할 수 있습니다.
또한 chmod +x utils/* 수행하여 해당 경계를 실행 할 수 있습니다.
예를 들어 Libritts 준비 파이프 라인을 가져옵니다. 다른 데이터 세트도 같은 방식으로 설정할 수 있습니다.
data/ 를 삭제하십시오. 내용은 다음과 같습니다. ├── train_all
│ ├── duration # the integer duration for each utterance. Frame shift is 10ms.
│ ├── feats.scp # the VQ index for each utterance. Will be explained later.
│ ├── text # the phone sequence for each utterance
│ └── utt2num_frames # the number of frames of each utterance.
├── eval_all
│ ... # similar four files
│── dev_all
│ ...
└── lang_1phn
└── train_all_units.txt # mapping between valid phones and their indexes
feats/label/.../feats.ark feats.scp 는 Kaldi 스타일의 기능 지정자입니다. 우리는 또한 온라인 (432MB)을 제공하므로 프로젝트 디렉토리에서 feats 위해 다운로드하고 압축을 해제하십시오. 이러한 기능은 VQ-WAV2VEC 기능의 1 차원 평평한 인덱스입니다. utils/feat-to-shape.py scp:feats/label/dev_all/feats.scp | head . Codebook feats/vqidx/codebook.npy 모양을 가지고 있습니다 [2, 320, 256] .즉, FairSeQ의 VQ-Wav2VEC 모델 인 Kmeans Librispeech 버전 인 FairSeQ의 VQ-WAV2VEC 모델을 사용하여 개별 코드북 INDX를 추출했습니다. 여기에는 각각 0에서 319 사이의 정수 인덱스 그룹이 포함되어 있습니다. 그런 다음이 쌍의 발생을 찾아 23632로 계산 된 다른 인덱스를 사용하여 레이블을 지정할 수 있습니다.
feats/vqidx/label2vqidx. 우리는 23632 라벨을 사용하여 VQ 분해 모델을 훈련시킵니다.
디렉토리를 올바르게 구성한 후 모델을 교육 할 수 있습니다.
CTX-TXT2VEC 모델 교육 간단히 수행 할 수 있습니다
python train.py --name Libritts --config_file configs/Libritts.yaml --num_node 1 --tensorboard --auto_resume 여기서 --name 출력 디렉토리 이름을 지정합니다. 자세한 구성은 configs/Libritts.yaml 확인하십시오. 멀티 GPU 교육은 프로그램에 의해 자동으로 처리됩니다 (모든 가시 장치를 사용하기위한 기본값).
훈련이 시작되면 체크 포인트 및 로그가 OUTPUT/Libritts 에 저장됩니다.
CTX-TXT2VEC의 디코딩은 항상 상황 정보를 제공하는 프롬프트에 의존합니다. 다시 말해, 디코딩하기 전에 다음과 같은 utt2prompt 파일이 있어야합니다.
1089_134686_000002_000001 1089_134686_000032_000008
1089_134686_000007_000005 1089_134686_000032_000008
1089_134686_000009_000003 1089_134686_000032_000008
1089_134686_000009_000008 1089_134686_000032_000008
1089_134686_000015_000003 1089_134686_000032_000008
모든 라인이 utt-to-synthesize prompt-utt 로 구성되는 경우. utt-to-synthesize 및 prompt-utt 키는 모두 인덱싱을 위해 feats.scp 에 있어야합니다.
논문에서 테스트 세트 B에 공식 UTT2PROMPT 파일을 사용하는 것이 좋습니다. 이를 다운로드하고 data/eval_all/utt2prompt 에 저장할 수 있습니다.
그 후, 컨텍스트 선불로 디코딩 (일명 연속)을 수행 할 수 있습니다.
python continuation.py --eval-set eval_all
# will only synthesize utterances in `utt2prompt`. Check the necessary files in `data/${eval_set}`. 디코딩 된 vq-indexes (2-dim)는 OUTPUT/Libritts/syn/${eval_set}/ 에 저장됩니다.
이 모델은 실제로 23631 개별 VQ "레이블"에서 샘플링합니다. 이 코드에서는
feats/vqidx/label2vqidx사용하여 2-DIM VQ 인덱스로 다시 변환합니다.
파형으로의 보코딩을 위해서는 "CTX-VEC2WAV"를 적극 권장합니다. CTX-VEC2WAV를 설정할 수 있습니다
git clone https://github.com/cantabile-kwok/UniCATS-CTX-vec2wav.git그런 다음 환경 교육을 따르십시오.
VQ 인덱스로 디코딩 한 후에는 보코딩을 달성 할 수 있습니다.
syn_dir= $PWD /OUTPUT/Libritts/syn/eval_all/
utt2prompt_file= $PWD /data/eval_all/utt2prompt
v2w_dir=/path/to/CTX-vec2wav/
cd $v2w_dir || exit 1 ;
source path.sh
# now, in CTX-vec2wav's environment
feat-to-len.py scp: $syn_dir /feats.scp > $syn_dir /utt2num_frames
# construct acoustic prompt specifier (mel spectrograms) using utt2prompt
python ./local/get_prompt_scp.py feats/normed_fbank/eval_all/feats.scp ${utt2prompt_file} > $syn_dir /prompt.scp
decode.py --feats-scp $syn_dir /feats.scp
--prompt-scp $syn_dir /prompt.scp
--num-frames $syn_dir /utt2num_frames
--outdir $syn_dir /wav/
--checkpoint /path/to/checkpoint개발 중에 다음 저장소를 참조했습니다.
ctx_text2vec/modeling/transformers/espnet_nets 및 utils 의 유틸리티 스크립트의 모델 아키텍처 용 ESPNET.utils 의 대부분의 유틸리티 스크립트.

