UniCATS CTX txt2vec
1.0.0
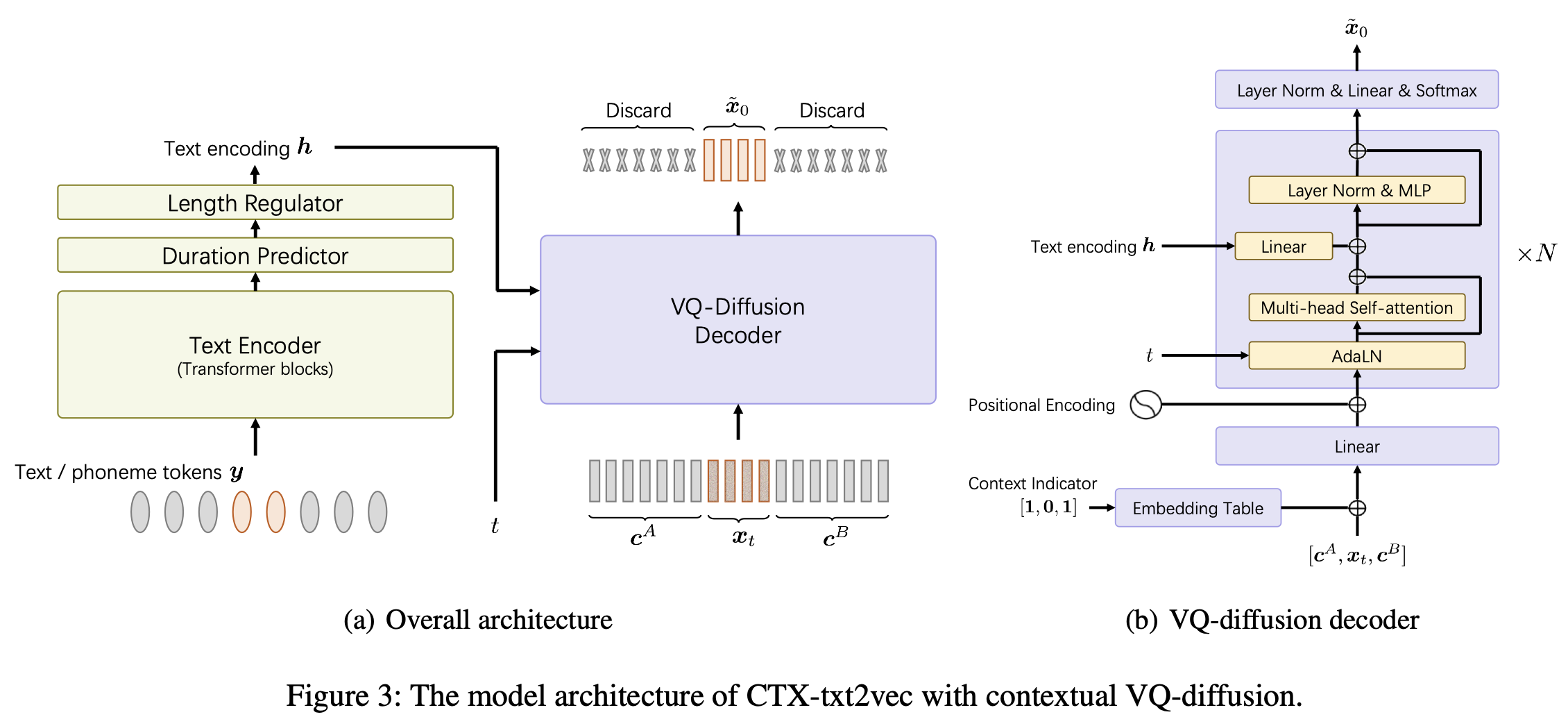
これは、AAAI-2024 Paper UnicatsにおけるCTX-TXT2VEC TTSモデルの公式実装です。コンテキストVQ拡散とボコディングを備えた統一されたコンテキスト認識テキストからスピーチフレームワークです。
このレポは、LinuxのPython 3.7でテストされています。 Condaで環境をセットアップできます
# Install required packages
conda create -n ctxt2v python=3.7 # or any name you like
conda activate ctxt2v
pip install -r requirements.txtこのプロジェクトに参加するたびに、 conda activate ctxt2vまたはsource path.shをアクティブにするCONDAを実行できます。
また、 chmod +x utils/*を実行して、これらのSCIPTが実行可能であることを確認できます。
ここでは、たとえばLibritts準備パイプラインを取ります。他のデータセットも同じ方法でセットアップできます。
data/に解凍します。内容は次のとおりです。 ├── train_all
│ ├── duration # the integer duration for each utterance. Frame shift is 10ms.
│ ├── feats.scp # the VQ index for each utterance. Will be explained later.
│ ├── text # the phone sequence for each utterance
│ └── utt2num_frames # the number of frames of each utterance.
├── eval_all
│ ... # similar four files
│── dev_all
│ ...
└── lang_1phn
└── train_all_units.txt # mapping between valid phones and their indexes
feats.scp 、 feats/label/.../feats.arkを指すKaldiスタイルの特徴指定器です。また、オンライン(432MB)を提供しているため、プロジェクトディレクトリにfeats foreをダウンロードして拡張してください。これらの機能は、VQ-WAV2VEC機能の1Dフラットなインデックスです。 utils/feat-to-shape.py scp:feats/label/dev_all/feats.scp | head 。コードブックのfeats/vqidx/codebook.npyには形があります[2, 320, 256] 。つまり、FairSeqのVQ-WAV2VECモデルであるKmeans Librispeechバージョンを使用して離散コードブックIndxesを抽出しました。これには、それぞれ0〜319の範囲の整数インデックスの2つのグループが含まれていました。次に、これらのペアの発生を見つけ、このインデックスを使用して別のインデックスを使用してラベルを付けます。
feats/vqidx/label2vqidx。 23632ラベルを使用して、VQ拡散モデルをトレーニングします。
ディレクトリを適切に構築した後、モデルをトレーニングできます。
CTX-TXT2VECモデルのトレーニングは、単純に実行できます
python train.py --name Libritts --config_file configs/Libritts.yaml --num_node 1 --tensorboard --auto_resumeここで--name出力ディレクトリ名を指定します。詳細な構成についてはconfigs/Libritts.yamlをご覧ください。マルチGPUトレーニングは、プログラムによって自動的に処理されます(すべての可視デバイスを使用するデフォルト)。
トレーニングが開始されると、チェックポイントとログがOUTPUT/Librittsに保存されます。
CTX-TXT2VECのデコードは、常にコンテキスト情報を提供するプロンプトに依存しています。言い換えれば、デコードする前に、次のように見えるutt2promptファイルがあるはずです。
1089_134686_000002_000001 1089_134686_000032_000008
1089_134686_000007_000005 1089_134686_000032_000008
1089_134686_000009_000003 1089_134686_000032_000008
1089_134686_000009_000008 1089_134686_000032_000008
1089_134686_000015_000003 1089_134686_000032_000008
ここで、すべての行がutt-to-synthesize prompt-uttとして編成されています。 utt-to-synthesizeとprompt-uttキーは両方とも、インデックスのためにfeats.scpに存在する必要があります。
論文のテストセットBに公式のUTT2PROMPTファイルを使用することをお勧めします。それをダウンロードして、 data/eval_all/utt2promptに保存できます。
その後、コンテキストでのデコードの準備(別名継続)は、
python continuation.py --eval-set eval_all
# will only synthesize utterances in `utt2prompt`. Check the necessary files in `data/${eval_set}`.デコードされたVQ-Indexes(2-dim)はOUTPUT/Libritts/syn/${eval_set}/に保存されます。
モデルは、実際には23631個の異なるVQ「ラベル」からサンプリングしていることに注意してください。このコードでは
feats/vqidx/label2vqidxを使用して2-dim VQインデックスに戻します。
波形へのボーコードには、対応する「CTX-VEC2WAV」を強くお勧めします。 ctx-vec2wav byをセットアップできます
git clone https://github.com/cantabile-kwok/UniCATS-CTX-vec2wav.gitそして、そこでの環境指導に従ってください。
VQインデックスにデコードした後、ボーコードは
syn_dir= $PWD /OUTPUT/Libritts/syn/eval_all/
utt2prompt_file= $PWD /data/eval_all/utt2prompt
v2w_dir=/path/to/CTX-vec2wav/
cd $v2w_dir || exit 1 ;
source path.sh
# now, in CTX-vec2wav's environment
feat-to-len.py scp: $syn_dir /feats.scp > $syn_dir /utt2num_frames
# construct acoustic prompt specifier (mel spectrograms) using utt2prompt
python ./local/get_prompt_scp.py feats/normed_fbank/eval_all/feats.scp ${utt2prompt_file} > $syn_dir /prompt.scp
decode.py --feats-scp $syn_dir /feats.scp
--prompt-scp $syn_dir /prompt.scp
--num-frames $syn_dir /utt2num_frames
--outdir $syn_dir /wav/
--checkpoint /path/to/checkpoint開発中、次のリポジトリが参照されました。
ctx_text2vec/modeling/transformers/espnet_netsおよびutilsのユーティリティスクリプトのモデルアーキテクチャ用。utilsのほとんどのユーティリティスクリプトについて。

