UniCATS CTX txt2vec
1.0.0
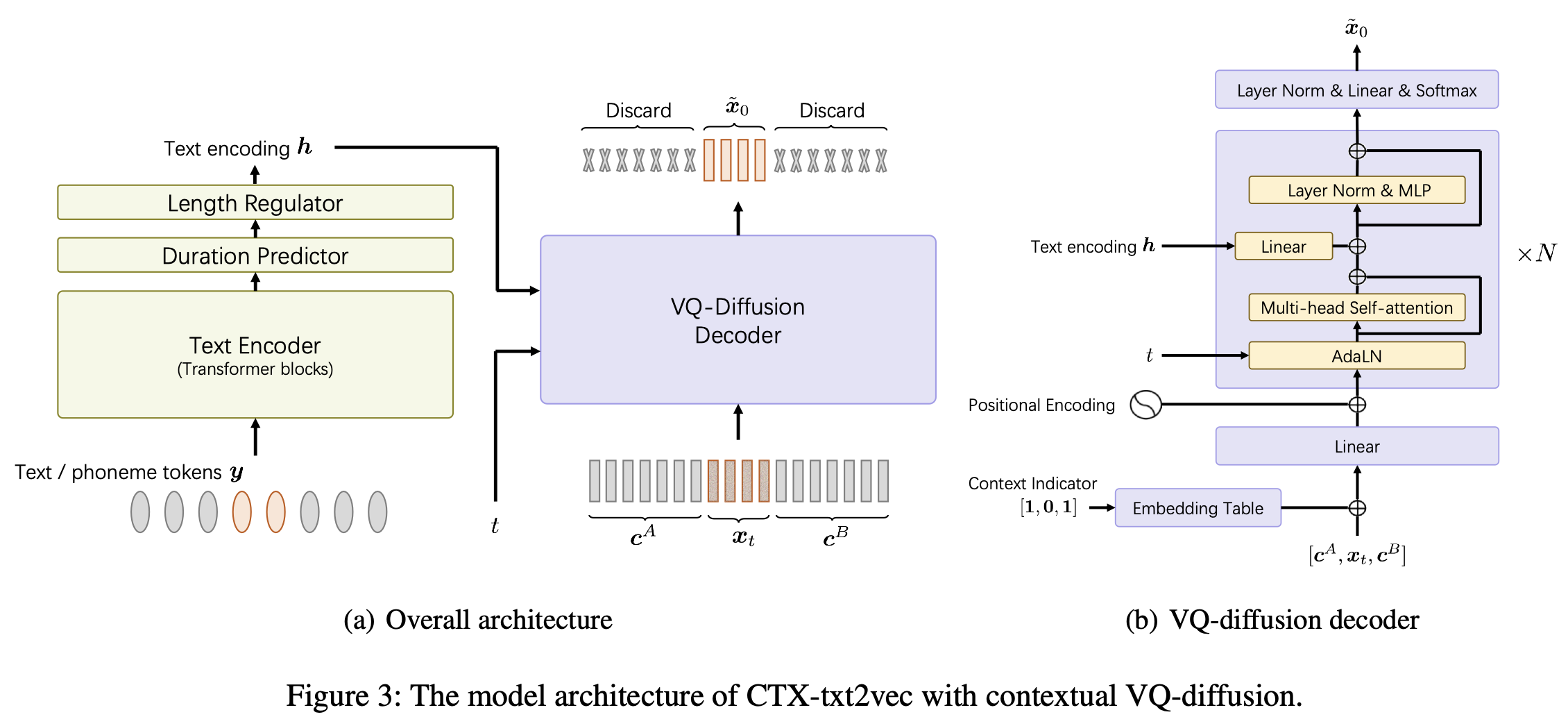
Ini adalah implementasi resmi model CTX-TXT2VEC TTS dalam kertas AAAI-2024 Unicats: kerangka kerja teks-ke-ucapan konteks yang disatukan dengan VQ-difusi dan vokoding kontekstual.
Repo ini diuji pada Python 3.7 di Linux. Anda dapat mengatur lingkungan dengan conda
# Install required packages
conda create -n ctxt2v python=3.7 # or any name you like
conda activate ctxt2v
pip install -r requirements.txt Setiap kali Anda memasuki proyek ini, Anda dapat melakukan conda activate ctxt2v atau source path.sh
Juga, Anda dapat melakukan chmod +x utils/* untuk memastikan scipt tersebut dapat dieksekusi.
Di sini kami mengambil pipa persiapan Libritts misalnya. Dataset lain dapat diatur dengan cara yang sama.
data/ di direktori proyek. Isinya adalah sebagai berikut: ├── train_all
│ ├── duration # the integer duration for each utterance. Frame shift is 10ms.
│ ├── feats.scp # the VQ index for each utterance. Will be explained later.
│ ├── text # the phone sequence for each utterance
│ └── utt2num_frames # the number of frames of each utterance.
├── eval_all
│ ... # similar four files
│── dev_all
│ ...
└── lang_1phn
└── train_all_units.txt # mapping between valid phones and their indexes
feats.scp adalah spesifikasi fitur gaya Kaldi yang menunjuk ke feats/label/.../feats.ark . Kami juga menyediakannya secara online (432MB), jadi silakan unduh dan unzip untuk feats di direktori proyek. Fitur-fitur ini adalah indeks perataan 1-D dari fitur VQ-WAV2VEC. Anda dapat memverifikasi bentuk fitur oleh utils/feat-to-shape.py scp:feats/label/dev_all/feats.scp | head . Codebook feats/vqidx/codebook.npy memiliki bentuk [2, 320, 256] .Artinya, kami mengekstraksi indx codebook diskrit menggunakan model VQ-WAV2VEC Fairseq , versi Librispeech KMeans , yang berisi 2 kelompok indeks integer masing-masing mulai dari 0 hingga 319. Kami kemudian menemukan kemunculan indeks ini dan memberi label pada indeks lain, yang dihitung hingga 23632. Pemetaan indeks ini dan label orisinal VQ ini menggunakan indeks lain, yang diperhitungkan 23632. Pemetaan antara label ini indeks dan label orisinal VQUS menggunakan indeks lain, yang diperhitungkan 23632. Pemetaan antara label ini indeks dan label orisinal VQUS menggunakan indeks lain, yang diperhitungkan 23632. Pemetaan antara label ini indeks dan label orisinal VQUS menggunakan indeks lain, yang diperhitungkan 23632. Pemetaan antara label ini indeks dan label orisinal VQUS menggunakan indeks lain, yang diperhitungkan 23632. Pemetaan antara label ini indeks dan label VQ original menggunakan VQ-WAV2.
feats/vqidx/label2vqidx. Kami menggunakan label 23632 untuk melatih model VQ-difusi.
Setelah membangun direktori dengan benar, model dapat dilatih.
Melatih model CTX-TXT2VEC dapat dilakukan dengan mudah
python train.py --name Libritts --config_file configs/Libritts.yaml --num_node 1 --tensorboard --auto_resume Di mana --name menentukan nama direktori output. Lihat configs/Libritts.yaml untuk konfigurasi terperinci. Pelatihan multi-GPU secara otomatis ditangani oleh program (default untuk menggunakan semua perangkat yang terlihat).
Setelah pelatihan dimulai, pos pemeriksaan dan log akan disimpan dalam OUTPUT/Libritts .
Decoding CTX-TXT2VEC selalu mengandalkan petunjuk yang memberikan informasi kontekstual. Dengan kata lain, sebelum decoding, harus ada file utt2prompt yang terlihat seperti:
1089_134686_000002_000001 1089_134686_000032_000008
1089_134686_000007_000005 1089_134686_000032_000008
1089_134686_000009_000003 1089_134686_000032_000008
1089_134686_000009_000008 1089_134686_000032_000008
1089_134686_000015_000003 1089_134686_000032_000008
di mana setiap baris disusun sebagai utt-to-synthesize prompt-utt . Kunci utt-to-synthesize dan prompt-utt harus ada dalam feats.scp untuk pengindeksan.
Kami merekomendasikan menggunakan file UTT2Prompt resmi untuk Test Set B di koran. Anda dapat mengunduhnya dan menyimpan ke data/eval_all/utt2prompt .
Setelah itu, decoding dengan konteks prepended (alias kelanjutan) dapat dilakukan oleh
python continuation.py --eval-set eval_all
# will only synthesize utterances in `utt2prompt`. Check the necessary files in `data/${eval_set}`. VQ-indexes yang diterjemahkan (2-DIM) akan disimpan ke OUTPUT/Libritts/syn/${eval_set}/ .
Perhatikan bahwa model sebenarnya sampel dari 23631 label "label" VQ yang berbeda. Dalam kode ini kami mengubahnya kembali ke indeks VQ 2-DIM menggunakan
feats/vqidx/label2vqidx.
Untuk vokoding ke bentuk gelombang, rekan "CTX-VEC2WAV" sangat dianjurkan. Anda dapat mengatur ctx-vec2wav oleh
git clone https://github.com/cantabile-kwok/UniCATS-CTX-vec2wav.gitdan kemudian ikuti instruksi lingkungan di sana.
Setelah decoding ke indeks VQ, vokoding dapat dicapai dengan
syn_dir= $PWD /OUTPUT/Libritts/syn/eval_all/
utt2prompt_file= $PWD /data/eval_all/utt2prompt
v2w_dir=/path/to/CTX-vec2wav/
cd $v2w_dir || exit 1 ;
source path.sh
# now, in CTX-vec2wav's environment
feat-to-len.py scp: $syn_dir /feats.scp > $syn_dir /utt2num_frames
# construct acoustic prompt specifier (mel spectrograms) using utt2prompt
python ./local/get_prompt_scp.py feats/normed_fbank/eval_all/feats.scp ${utt2prompt_file} > $syn_dir /prompt.scp
decode.py --feats-scp $syn_dir /feats.scp
--prompt-scp $syn_dir /prompt.scp
--num-frames $syn_dir /utt2num_frames
--outdir $syn_dir /wav/
--checkpoint /path/to/checkpointSelama pengembangan, repositori berikut dirujuk:
ctx_text2vec/modeling/transformers/espnet_nets dan skrip utilitas di utils .utils .

