UniCATS CTX txt2vec
1.0.0
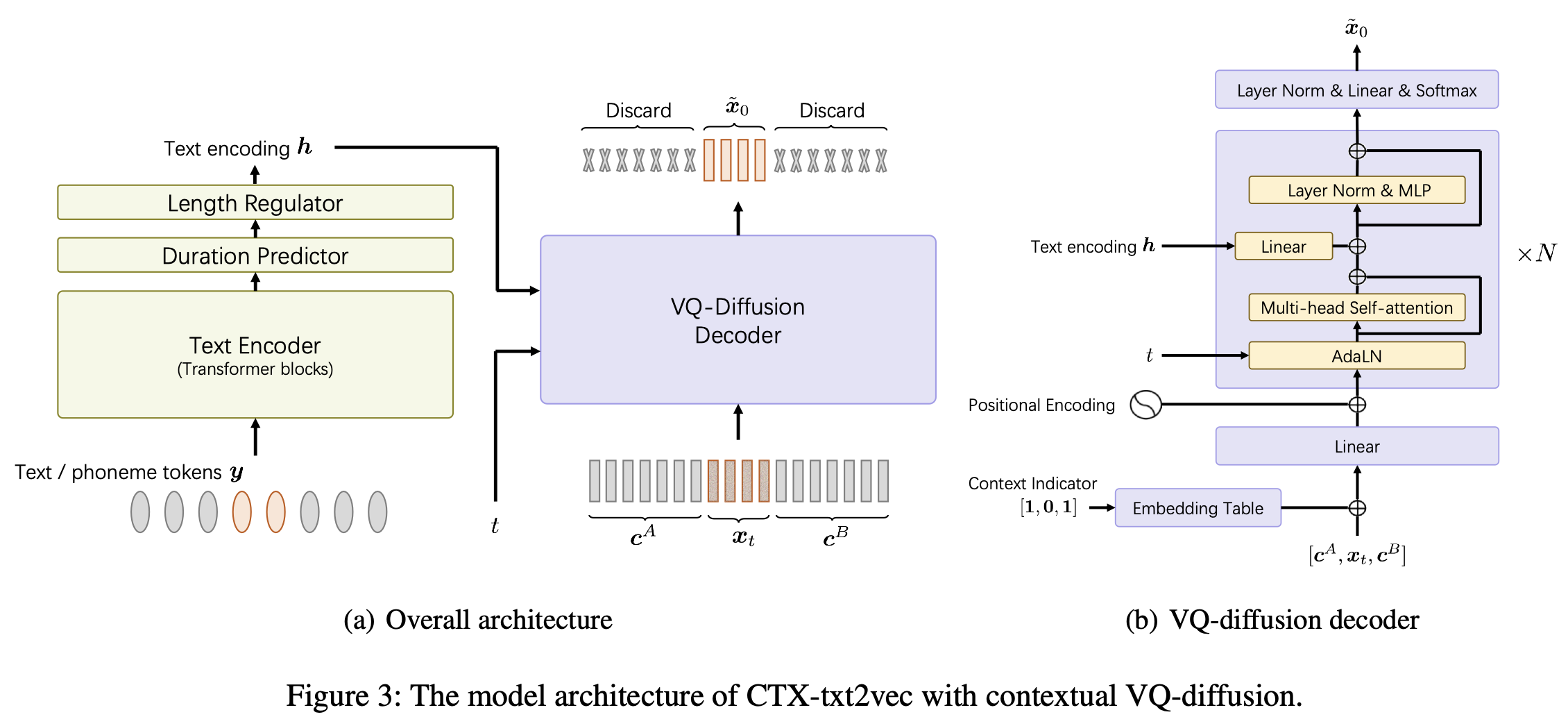
Esta es la implementación oficial del modelo CTX-TXT2VEC TTS en los unicats de papel AAAI-2024: un marco de texto a voz contextual unificado con difusión VQ contextual y vocoding.
Este repositorio se prueba en Python 3.7 en Linux. Puedes configurar el medio ambiente con conda
# Install required packages
conda create -n ctxt2v python=3.7 # or any name you like
conda activate ctxt2v
pip install -r requirements.txt Cada vez que ingrese este proyecto, puede conda activate ctxt2v o source path.sh
Además, puede realizar chmod +x utils/* para asegurarse de que esos SCIPS sean ejecutables.
Aquí tomamos la tubería de preparación de Libritts, por ejemplo. Otros conjuntos de datos se pueden configurar de la misma manera.
data/ en el directorio del proyecto. El contenido es el siguiente: ├── train_all
│ ├── duration # the integer duration for each utterance. Frame shift is 10ms.
│ ├── feats.scp # the VQ index for each utterance. Will be explained later.
│ ├── text # the phone sequence for each utterance
│ └── utt2num_frames # the number of frames of each utterance.
├── eval_all
│ ... # similar four files
│── dev_all
│ ...
└── lang_1phn
└── train_all_units.txt # mapping between valid phones and their indexes
feats.scp es la característica de estilo Kaldi especificador que apunta a feats/label/.../feats.ark . También lo proporcionamos en línea (432 MB), así que descarguelo y descifrar a feats en el directorio del proyecto. Estas características son los índices 1-D Flatten de las características VQ-WAV2VEC. Puede verificar la forma de las características de utils/feat-to-shape.py scp:feats/label/dev_all/feats.scp | head . El libro de código feats/vqidx/codebook.npy tiene forma [2, 320, 256] .Es decir, extraemos el libro de códigos discretos indxes utilizando el modelo VQ-wav2vec de FairSeq , la versión Kmeans Librispeech, que contenía 2 grupos de índices enteros de cada uno que varían de 0 a 319. Luego encontramos las ocurrencias de estos pares y etiquetarlos usando otro índice, que cuenta a 23632. La mapeo entre esta etiqueta y el índice VQ-WAV2 Vecedlos se puede encontrar en el Índice de código VQ-WAV2 se puede usar con otro índice usando otro índice, se encuentra a 23632. La asignación entre esta etiqueta y el índice de código VQ-WAV2 se puede encontrar en el Índice de código VQ-WAV2 que se puede encontrar con otro índice utilizando otro índice, se encuentra a 23632. La asignación entre esta etiqueta y el índice VQ-WAV2 VOCOC se puede encontrar en el Índice de código VQ-WAV2.
feats/vqidx/label2vqidx. Utilizamos las etiquetas 23632 para entrenar el modelo de difusión VQ.
Después de construir los directorios correctamente, el modelo puede ser entrenado.
Entrenamiento El modelo CTX-TXT2VEC se puede hacer simplemente
python train.py --name Libritts --config_file configs/Libritts.yaml --num_node 1 --tensorboard --auto_resume donde --name especifica el nombre del directorio de salida. Echa un vistazo a configs/Libritts.yaml para ver las configuraciones detalladas. El programa maneja automáticamente la capacitación multi-GPU (predeterminada para usar todos los dispositivos visibles).
Después de que comience la capacitación, los puntos de control y los registros se guardarán en OUTPUT/Libritts .
La decodificación de CTX-TXT2VEC siempre depende de las indicaciones que proporcionan información contextual. En otras palabras, antes de decodificar, debe haber un archivo utt2prompt que se vea como:
1089_134686_000002_000001 1089_134686_000032_000008
1089_134686_000007_000005 1089_134686_000032_000008
1089_134686_000009_000003 1089_134686_000032_000008
1089_134686_000009_000008 1089_134686_000032_000008
1089_134686_000015_000003 1089_134686_000032_000008
Donde cada línea se organiza como utt-to-synthesize prompt-utt . Las claves utt-to-synthesize y prompt-utt deben estar presentes en feats.scp SCP para la indexación.
Recomendamos usar el archivo UTT2Prompt oficial para el conjunto de pruebas B en el documento. Puede descargar eso y guardar en data/eval_all/utt2prompt .
Después de eso, la decodificación con el contexto prepuesto (también conocido como continuación) puede realizarse por
python continuation.py --eval-set eval_all
# will only synthesize utterances in `utt2prompt`. Check the necessary files in `data/${eval_set}`. Los índices VQ decodificados (2-DIM) se guardarán en OUTPUT/Libritts/syn/${eval_set}/ .
Tenga en cuenta que el modelo en realidad muestra de 23631 "etiquetas" distintas de VQ. En este código lo transformamos a los índices VQ 2-DIM utilizando
feats/vqidx/label2vqidx.
Para el vocoding a la forma de onda, la contraparte "CTX-VEC2WAV" es muy recomendable. Puede configurar CTX-VEC2WAV por
git clone https://github.com/cantabile-kwok/UniCATS-CTX-vec2wav.gity luego sigue la instrucción ambiental allí.
Después de decodificar a los índices de VQ, se puede lograr vocoding por
syn_dir= $PWD /OUTPUT/Libritts/syn/eval_all/
utt2prompt_file= $PWD /data/eval_all/utt2prompt
v2w_dir=/path/to/CTX-vec2wav/
cd $v2w_dir || exit 1 ;
source path.sh
# now, in CTX-vec2wav's environment
feat-to-len.py scp: $syn_dir /feats.scp > $syn_dir /utt2num_frames
# construct acoustic prompt specifier (mel spectrograms) using utt2prompt
python ./local/get_prompt_scp.py feats/normed_fbank/eval_all/feats.scp ${utt2prompt_file} > $syn_dir /prompt.scp
decode.py --feats-scp $syn_dir /feats.scp
--prompt-scp $syn_dir /prompt.scp
--num-frames $syn_dir /utt2num_frames
--outdir $syn_dir /wav/
--checkpoint /path/to/checkpointDurante el desarrollo, se mencionó los siguientes repositorios:
ctx_text2vec/modeling/transformers/espnet_nets y Scripts de utilidad en utils .utils .

