Font_Recognition DeepFont
1.0.0
O Deepfont Paper é uma técnica criada pelo Adobe.inc para detectar a fonte de imagens usando o aprendizado profundo. Eles publicaram seu trabalho como artigo para o público. Inspirando o trabalho deles, converti a tese deles em um código de trabalho.
O trabalho é dividido em 4 etapas:
DataSet: como o DataSet DataSet do Adobevfr é enorme em tamanho e contém muitas categorias de fontes. Criamos o conjunto de dados personalizado com base nos patches de fonte necessários usando o textRecognitionDatagenerator Github. A pasta de amostra estará disponível neste repositório.
Pré -processamento do conjunto de dados: as fontes não são como objetos, ter que ter enormes informações espaciais para classificar seus recursos. Para identificar, a mudança de recurso muito minuciosa Deepfont usou certas técnicas de pré -processamento, elas são
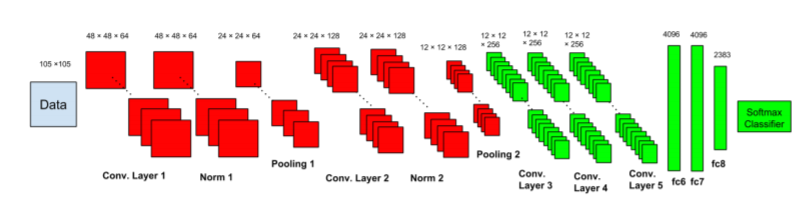
Arquitetura da CNN: Ao contrário de outra rede de classificação de imagem, eles seguiram um novo esquema como duas sub -redes,
Framework (Keras): Como prototipagem, usei Keras para construir todo o pipeline. Sinta -se à vontade para protótipo em outras estruturas.
Thanks to DeepFont Team for their amazing work

Copyright © 2021 Robin Reni. Todos os direitos reservados


