Font_Recognition DeepFont
1.0.0
Deepfont Paper es una técnica creada por Adobe.InC para detectar la fuente de las imágenes que usan el aprendizaje profundo. Publicaron su trabajo como artículo para el público. Inspirando su trabajo, convertí su tesis en un código de trabajo.
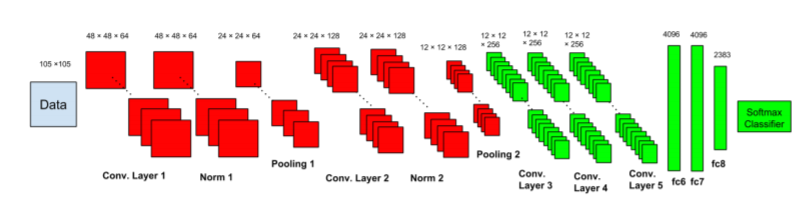
El trabajo se divide en 4 pasos:
DataSet: dado que ADOBEVFR DataSet DataLink es de gran tamaño y contiene muchas categorías de fuentes. Creamos un conjunto de datos personalizado en función de los parches de fuentes requeridos utilizando TextrecognitionDatagenerator GitHub. La carpeta de muestra estará disponible en este repositorio.
Preprocesamiento del conjunto de datos: las fuentes no son como objetos, para tener una gran información espacial para clasificar sus características. Para identificar un cambio de características muy minucioso, DeepFont utilizó ciertas técnicas de preprocesamiento que son
Arquitectura de CNN: a diferencia de otra clasificación de imágenes CNN Network, siguieron un nuevo esquema como dos subredes,
Marco (keras): como su prototipos, utilicé keras para construir toda la tubería. Siéntase libre de prototipos en otros marcos.
Thanks to DeepFont Team for their amazing work

Copyright © 2021 Robin Reni. Reservados todos los derechos


