Font_Recognition DeepFont
1.0.0
Deepfont Paper est une technique créée par Adobe.inc pour détecter la police à partir d'images utilisant l'apprentissage en profondeur. Ils ont publié leur travail de document pour le public. Inspirant leur travail, j'ai converti leur thèse en un code de travail.
Le travail est divisé en 4 étapes:
Ensemble de données: Étant donné que le jeu de données ADOBEVFFR est de taille énorme et contient beaucoup de catégories de polices. Nous avons créé un ensemble de données personnalisé en fonction des correctifs de police requis à l'aide de TexTrecognitionDatagenerator GitHub. Le dossier de l'échantillon sera disponible dans ce dépôt.
Prétraitement de l'ensemble de données: les polices ne sont pas comme des objets, pour avoir d'énormes informations spatiales pour classer leurs fonctionnalités. Pour identifier des fonctionnalités très minuscules, Deepfont a utilisé certaines techniques de prétraitement, elles sont
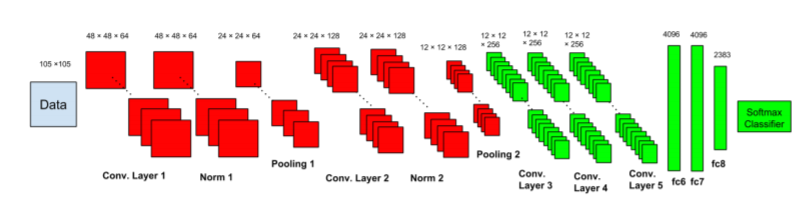
Architecture CNN: Contrairement au réseau CNN de classification d'images, ils ont suivi un nouveau schéma comme deux sous-réseaux,
Framework (Keras): En tant que prototypage, j'ai utilisé Keras pour construire l'intégralité du pipeline. N'hésitez pas à prototyper dans d'autres cadres.
Thanks to DeepFont Team for their amazing work

Copyright © 2021 Robin Reni. Tous droits réservés


