Font_Recognition DeepFont
1.0.0
DeepFont Paper ist eine von Adobe.inc erstellte Technik, um Schriftart mit dem Deep -Lernen aus Bildern zu erkennen. Sie veröffentlichten ihre Arbeit als Papier für die Öffentlichkeit. Ich inspirierte ihre Arbeit und habe ihre These in einen Arbeitscode umgewandelt.
Die Arbeit ist in 4 Schritte aufgeteilt:
Datensatz: Da AdobevFR -DataSet Datalink groß ist und viele Schriftartenkategorien enthält. Wir haben benutzerdefinierte Datensatz basierend auf den erforderlichen Schriftarten mit TexTrecognitionDatagenerator GitHub erstellt. Der Beispielordner ist in diesem Repo verfügbar.
Vorverarbeitung des Datensatzes: Schriftarten sind nicht wie Objekte, um riesige räumliche Informationen zu ermöglichen, um ihre Funktionen zu klassifizieren. Um sehr winzige Funktionen zu identifizieren. Änderung von Deepfont verwendet bestimmte Vorverarbeitungstechniken, die sie sind
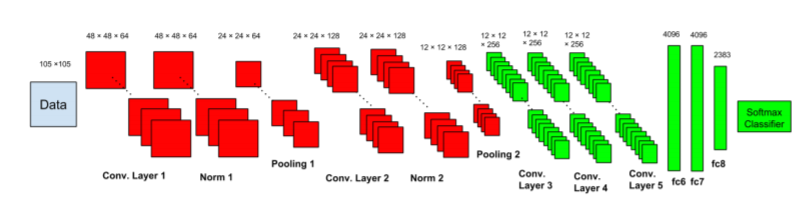
CNN -Architektur: Im Gegensatz zu anderen Bildklassifizierung CNN -Netzwerk folgten sie einem neuen Schema wie zwei Subnetzwerken.
Framework (Keras): Als Prototyping habe ich Keras verwendet, um die gesamte Pipeline zu bauen. Fühlen Sie sich frei, in anderen Frameworks Prototypen zu prototypisieren.
Thanks to DeepFont Team for their amazing work

Copyright © 2021 Robin Reni. Alle Rechte vorbehalten


