Deixe os modelos treinados de Paddleocr usem em Pytorch
Forneça referência para a paddle a Pytorch
Perceber
PytorchOCR é portado pelo PaddleOCRv2.0+ versão gráfica dinâmica.
Atualizações recentes
2024.02.20 pp-ocrv4, fornecendo modelos móveis e servidores
PP-OCRV4-MOBILE: Com velocidade comparável, o efeito da cena chinês será melhorado em 4,5%em comparação com o PP-OCRV3, a cena inglesa será aprimorada em 10%e a precisão média do reconhecimento dos modelos multilíngues de 80 idiomas será aumentada em mais de 8%.
PP-OCRV4-SERVER: O modelo OCR com a maior precisão foi lançado, com a precisão dos modelos de detecção em cenários chineses e ingleses aumentando 4,9%e a precisão dos modelos de identificação aumentando 2%.
2023.04.16 A identificação da fórmula pode
2023.04.07 Texto de textim textion text
2022.10.17 Reconhecimento de texto: Vitstr
2022.10.07 Detecção de texto: db ++
2022.07.24 Algoritmo de detecção de texto (FceNet)
2022.07.16 Algoritmo de reconhecimento de texto (SVTR)
2022.06.19 Algoritmo de reconhecimento de texto (SAR)
2022.05.29 PP-OCRV3, Quando a velocidade é comparável, o efeito da cena chinês é aumentado em 5%em comparação com o PP-OCRV2, a cena inglesa é aumentada em 11%e a precisão média do reconhecimento de 80 modelos multilíngues de idiomas aumentou mais de 5%.
2022.05.14 Modelo de detecção de texto PP-OCRV3
2022.04.17 1 Algoritmo de reconhecimento de texto (NRTR)
2022.03.20 1 Algoritmo de detecção de texto (PSENET)
2021.09.11 PP-OCRV2, a velocidade de inferência da CPU é 220% maior que a do servidor PP-Oocr; O efeito é 7% maior que o do celular pp-ocr
2021.06.01 ATUALIZAÇÃO SRN
2021.04.25 Atualizado AAAI 2021 Algoritmo de identificação de ponta a ponta PGNET PGNET
2021.04.24 Atualizar raro
2021.04.12 Atualizar StarNet
2021.04.08 DB atualizado, Sast, East, Rosetta, CRNN
2021.04.03 Atualizou o modelo de reconhecimento multilíngue, atualmente suporta mais de 27 idiomas e downloads de modelos multilíngues, incluindo chinês simplificado, tradicional chinês, inglês, francês, alemão, coreano, japonês, italiano, espanhol, português, russo, árabe, etc.
2021.01.10 Modelo de OCR geral chinês e inglês gratuito
característica
Modelo de inferência de alta qualidade, efeito de reconhecimento preciso
Série PP-OCR de Ultra Light: Detecção + Classificador de Direção + Identificação
Ultra-Lightweight Ptocr_mobile Mobile Terminal Series
Série geral ptocr_server
Suporta reconhecimento de combinação digital chinês e inglês, reconhecimento de texto vertical e reconhecimento de texto longo
Suporta reconhecimento multilíngue: coreano, japonês, alemão, francês, etc.
Lista de modelos (atualizada)
Pytorch Modelo Download Link: https://pan.baidu.com/s/1r1delt8blgxeop2rqrejeg Código de extração: 6clx
Modelo Paddleocr Baidu Network Disk Link: https://pan.baidu.com/s/1GETAPRT2L_JQWHJWML0G9G Código de extração: LMV7
Para mais downloads de modelos (incluindo multilíngues), você pode consultar os downloads de modelo PT-OCR V2.0 Series
Tutorial de documentação
Instalação rápida
Previsão de modelos
Pipline
Exibição de efeito
Referências
Perguntas frequentes
consulte
PENDÊNCIA
Algoritmo de fronteira: detecção de texto DRRG, reconhecimento de texto RFL
Reconhecimento de texto: Abinet, Visionlan, Spin, Robustscanner
Reconhecimento da tabela: Tablemaster
PP-StructureV2, o desempenho da função do sistema é totalmente atualizado, adaptado às cenas chinesas, adicionou suporte para restauração de layout e suporta um comando de uma linha para preencher o PDF à palavra
Análise de layout Otimização do modelo: o armazenamento do modelo é reduzido em 95%, a velocidade é aumentada 11 vezes, o tempo médio da CPU é de apenas 41ms
Otimização do modelo de reconhecimento de tabela: Projete três estratégias de otimização principais, e o tempo de previsão não é alterado, a precisão do modelo é melhorada em 6%.
Otimização do Modelo de Extração de Informações -Chave: Projete a estrutura do modelo visualmente irrelevante, melhore a precisão do reconhecimento de entidade semântica em 2,8%e aumente a precisão da extração de relacionamento em 9,1%.
Algoritmo de reconhecimento de texto (semente)
Documento Algoritmo estruturado Algoritmo de extração de informações (SDMGR)
Análise da estrutura de documentos PP-Structure Toolkit, suporta análise de layout e reconhecimento de tabela (incluindo exportação do Excel)
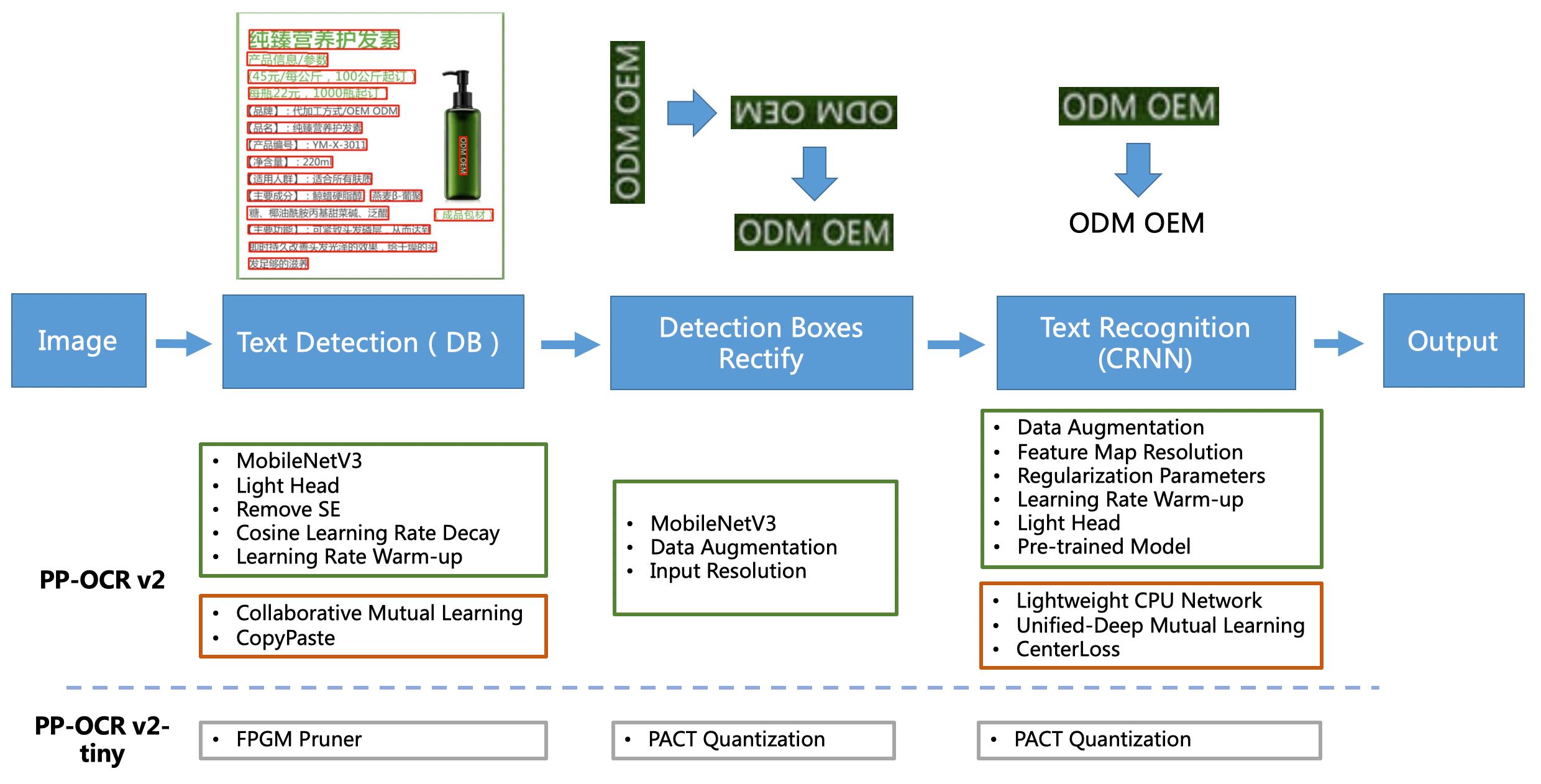
PP-OCRV2 PIPLINE
[1] O PP-Oocr é um sistema OCR ultra-leve prático. Consiste principalmente em três partes: detecção de texto db, correção do quadro de detecção e reconhecimento de texto do CRNN. O sistema usa 19 estratégias eficazes para otimizar e diminuir os modelos de cada módulo de oito aspectos: seleção e ajuste de rede de backbone, design de cabeça de previsão, aumento de dados, estratégia de transformação da taxa de aprendizado, seleção de parâmetros de regularização, uso de modelo pré-treinado e o OCR de modelos automáticos e o OCR de modelos e, finalmente, o OCR de médio-8 e o OCR de médio-8 e o OCR de médio-8 e, no meio-dia, o OCR de médio e o tamanho do meio-8 e o meio-dia 18 e o OCR do meio-dia 8 e o tamanho do OCR. Para mais detalhes, consulte a solução técnica pp-ococ https://arxiv.org/abs/2009.09941
[2] Com base no PP-OCR, o PP-OCRV2 se concentrou ainda mais na otimização em cinco aspectos. O modelo de detecção adota a estratégia de destilação de conhecimento de aprendizado mútuo colaborativo da CML e a estratégia de aumento de dados da CopyPaste; O modelo de identificação adota a rede de backbone leve LCNET, a estratégia de destilação de conhecimento aprimorada do UDML e a melhoria da função de perda de perda de CTC aprimorada (como mostrado na caixa vermelha na figura acima), melhorando ainda mais a velocidade de inferência e o efeito de previsão. Para mais detalhes, consulte o relatório técnico do PP-OCRV2.