PytorchOCR is ported by PaddleOCRv2.0+ dynamic graph version.
Recent updates
2024.02.20 PP-OCRv4, providing mobile and server models
PP-OCRv4-mobile: With comparable speed, the Chinese scene effect will be improved by 4.5% compared with PP-OCRv3, the English scene will be improved by 10%, and the average recognition accuracy of 80 language multilingual models will be increased by more than 8%.
PP-OCRv4-server: The OCR model with the highest accuracy has been released, with the accuracy of detection models in Chinese and English scenarios being increased by 4.9%, and the accuracy of identification models being increased by 2%.
2023.04.16 Formula Identification CAN
2023.04.07 Text Super Segment Text Telescope
2022.10.17 Text Recognition: ViTSTR
2022.10.07 Text Detection: DB++
2022.07.24 Text Detection Algorithm (FCENET)
2022.07.16 Text Recognition Algorithm (SVTR)
2022.06.19 Text Recognition Algorithm (SAR)
2022.05.29 PP-OCRv3, when the speed is comparable, the Chinese scene effect is increased by 5% compared with PP-OCRv2, the English scene is increased by 11%, and the average recognition accuracy of 80 language multilingual models has increased by more than 5%.
2022.05.14 PP-OCRv3 text detection model
2022.04.17 1 text recognition algorithm (NRTR)
2022.03.20 1 text detection algorithm (PSENet)
2021.09.11 PP-OCRv2, the CPU inference speed is 220% higher than that of PP-OCR server; the effect is 7% higher than that of PP-OCR mobile
2021.06.01 Update SRN
2021.04.25 Updated AAAI 2021 paper end-to-end identification algorithm PGNet
2021.04.24 Update RARE
2021.04.12 Update STARNET
2021.04.08 Updated DB, SAST, EAST, ROSETTA, CRNN
2021.04.03 Updated the multilingual recognition model, currently supports more than 27 languages, and downloads of multilingual models, including Simplified Chinese, Traditional Chinese, English, French, German, Korean, Japanese, Italian, Spanish, Portuguese, Russian, Arabic, etc. Follow-up plans can refer to the multilingual R&D plan
2021.01.10 Free Chinese and English General OCR Model
characteristic
High-quality inference model, accurate recognition effect
Ultra-light PP-OCR series: detection + direction classifier + identification
Ultra-lightweight ptocr_mobile mobile terminal series
General Ptocr_server series
Supports Chinese and English digital combination recognition, vertical text recognition, and long text recognition
Supports multilingual recognition: Korean, Japanese, German, French, etc.
Model list (updated)
PyTorch model download link: https://pan.baidu.com/s/1r1DELT8BlgxeOP2RqREJEg Extraction code: 6clx
PaddleOCR model Baidu network disk link: https://pan.baidu.com/s/1getAprT2l_JqwhjwML0g9g Extraction code: lmv7
For more model downloads (including multilingual), you can refer to the PT-OCR v2.0 series model downloads
Documentation tutorial
Quick installation
Model prediction
Pipline
Effect display
References
FAQ
refer to
TODO
Frontier algorithm: text detection DRRG, text recognition RFL
Text recognition: ABINet, VisionLAN, SPIN, RobustScanner
Table recognition: TableMaster
PP-Structurev2, the system function performance is fully upgraded, adapted to Chinese scenes, added support for layout restoration, and supports one-line command to complete PDF to Word
Layout analysis model optimization: model storage is reduced by 95%, speed is increased by 11 times, average CPU time is only 41ms
Table recognition model optimization: design three major optimization strategies, and the prediction time is not changed, the model accuracy is improved by 6%.
Optimization of key information extraction model: design visually irrelevant model structure, improve semantic entity recognition accuracy by 2.8%, and increase the relationship extraction accuracy by 9.1%.
Text recognition algorithm (SEED)
Document Structured Algorithm Key Information Extraction Algorithm (SDMGR)
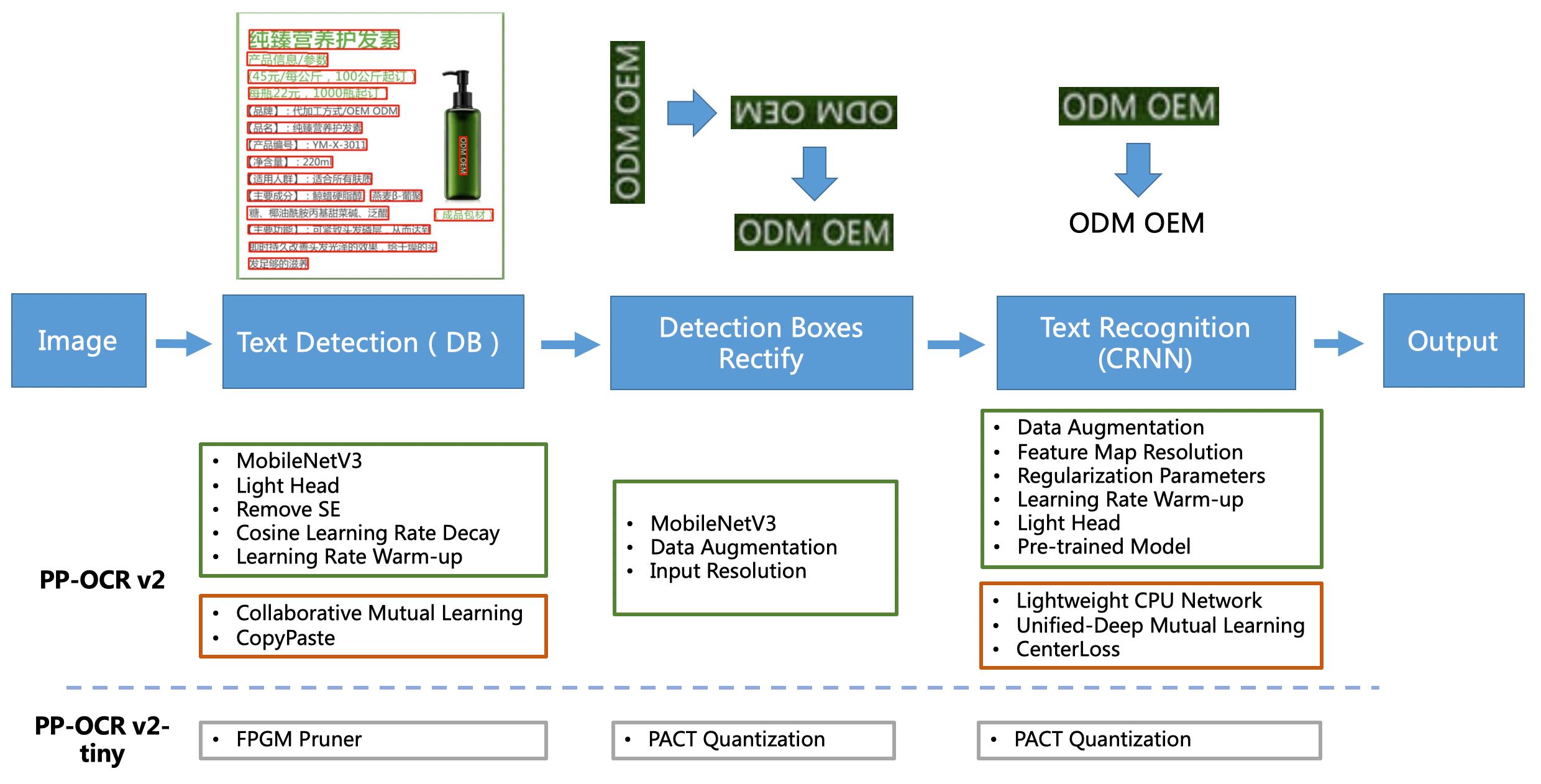
[1] PP-OCR is a practical ultra-lightweight OCR system. It mainly consists of three parts: DB text detection, detection frame correction and CRNN text recognition. The system uses 19 effective strategies to optimize and slim the models of each module from eight aspects: backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-trained model use, and automatic model cropping and quantization, and finally obtains ultra-lightweight Chinese and English OCR with an overall size of 3.5M and 2.8M English digital OCR. For more details, please refer to the PP-OCR technical solution https://arxiv.org/abs/2009.09941
[2] Based on PP-OCR, PP-OCRv2 further focused on optimization in five aspects. The detection model adopts CML collaborative mutual learning knowledge distillation strategy and CopyPaste data augmentation strategy; the identification model adopts LCNet lightweight backbone network, UDML improved knowledge distillation strategy and Enhanced CTC loss loss function improvement (as shown in the red box in the figure above), further improving the inference speed and prediction effect. For more details, please refer to the PP-OCRv2 technical report.