Paddleocr2pytorch
単純化された中国人|英語
導入
「フリーセックス」パドルクル。
このプロジェクトは、次のことを目指しています。
- Paddleocrを学びます
- Paddleocrの訓練されたモデルをPytorchで使用します
- Pytorchへのパドルの参照を提供します
知らせ
PytorchOCRは、 PaddleOCRv2.0+動的グラフバージョンによって移植されています。
最近の更新
- 2024.02.20 PP-OCRV4、モバイルモデルとサーバーモデルを提供します
- PP-OCRV4-MOBILE:同等の速度で、中国のシーン効果はPP-OCRV3と比較して4.5%改善され、英語のシーンは10%改善され、80の言語多言語モデルの平均認識精度は8%以上増加します。
- PP-OCRV4-SERVER:精度が最も高いOCRモデルがリリースされ、中国語および英語のシナリオの検出モデルの精度が4.9%増加し、識別モデルの精度が2%増加します。
- 2023.04.16式識別CAN
- 2023.04.07テキストスーパーセグメントテキストテレススコープ
- 2022.10.17テキスト認識:Vitstr
- 2022.10.07テキスト検出:DB ++
- 2022.07.24テキスト検出アルゴリズム(fcenet)
- 2022.07.16テキスト認識アルゴリズム(SVTR)
- 2022.06.19テキスト認識アルゴリズム(SAR)
- 2022.05.29 PP-OCRV3、速度が同等になると、中国のシーン効果がPP-OCRV2と比較して5%増加し、英語のシーンが11%増加し、80言語多言語モデルの平均認識精度が5%以上増加しています。
- 2022.05.14 PP-OCRV3テキスト検出モデル
- 2022.04.17 1テキスト認識アルゴリズム(NRTR)
- 2022.03.20 1テキスト検出アルゴリズム(PSENET)
- 2021.09.11 PP-OCRV2、CPU推論速度はPP-ocrサーバーの速度よりも220%高くなっています。効果はpp-ocrモバイルの効果よりも7%高くなっています
- 2021.06.01更新SRN
- 2021.04.25 AAAI 2021ペーパーエンドツーエンド識別アルゴリズムPGNETを更新しました
- 2021.04.24更新レア
- 2021.04.12 Starnetを更新します
- 2021.04.08 DB、SAST、East、Rosetta、CRNNの更新
- 2021.04.03は、多言語認識モデルを更新しており、現在27を超える言語をサポートしており、単純化された中国語、伝統的な中国語、英語、フランス語、ドイツ語、日本、イタリア語、スペイン語、ポルトガル語、ロシア語、アラビア語などを含む多言語モデルのダウンロードをサポートしています。
- 2021.01.10無料中国語および英語の一般OCRモデル
特性
高品質の推論モデル、正確な認識効果
- 超軽量PP-ocrシリーズ:検出 +方向分類器 +識別
- 超軽量PTOCR_MOBILEモバイルターミナルシリーズ
- 一般的なPTOCR_SERVERシリーズ
- 中国と英語のデジタルコンビネーション認識、垂直テキスト認識、および長いテキスト認識をサポートしています
- 多言語認識をサポートする:韓国語、日本、ドイツ語、フランス語など。
モデルリスト(更新)
pytorchモデルのダウンロードリンク:https://pan.baidu.com/s/1r1delt8blgxeop2rqrejeg抽出コード:6clx
PaddleocrモデルBaiduネットワークディスクリンク:https://pan.baidu.com/s/1getaprt2l_jqwhjwml0g9g抽出コード:LMV7
その他のモデルのダウンロード(多言語を含む)については、PT-OCR V2.0シリーズモデルのダウンロードを参照できます
ドキュメントチュートリアル
- クイックインストール
- モデル予測
- ピップライン
- エフェクトディスプレイ
- 参照
- よくある質問
- 参照してください
トト
PP-OCRV2 PIPLINE
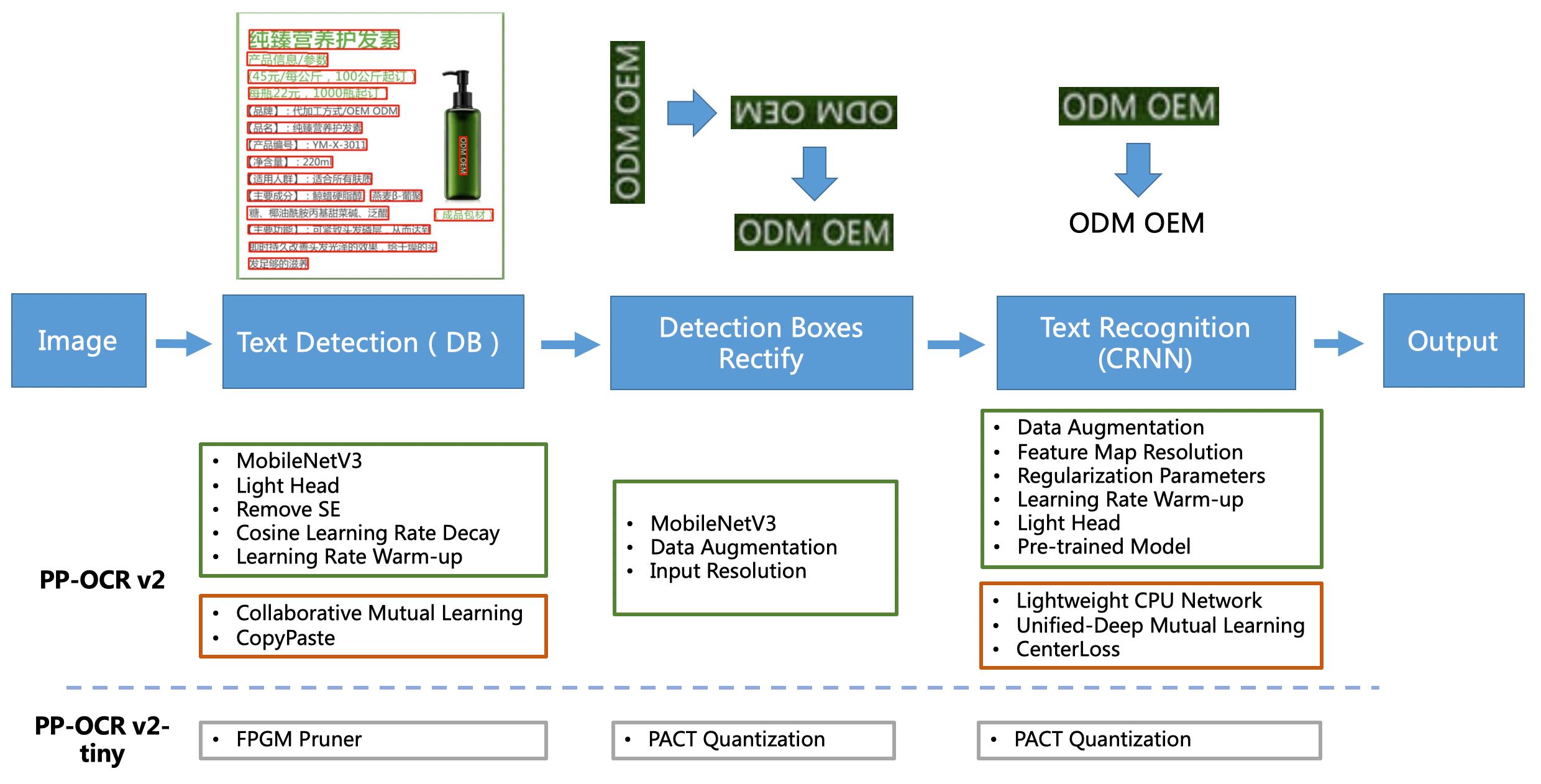
[1] PP-OCRは、実用的な超軽量OCRシステムです。主に、DBテキスト検出、検出フレームの修正、CRNNテキスト認識の3つの部分で構成されています。システムは、バックボーンネットワークの選択と調整、予測ヘッド設計、データの増強、学習率変換戦略、正規化パラメーター選択、事前訓練されたモデルの使用、および自動モデルのトリミングと量子化の8つの側面から各モジュールのモデルを最適化およびスリムするために19の効果的な戦略を使用します。詳細については、PP-OCRテクニカルソリューションhttps://arxiv.org/abs/2009.09941を参照してください。
[2] PP-OCRに基づいて、PP-OCRV2は5つの側面での最適化にさらに焦点を合わせました。検出モデルは、CMLコラボレーション相互学習知識蒸留戦略とコピーパストデータ増強戦略を採用しています。識別モデルは、LCNET軽量バックボーンネットワークを採用し、UDMLは知識蒸留戦略を改善し、CTC損失関数の改善を強化し(上記の図の赤いボックスに示すように)、推論速度と予測効果をさらに改善します。詳細については、PP-OCRV2テクニカルレポートを参照してください。
エフェクトディスプレイ
参照してください
- https://github.com/paddlepaddle/paddleocr
- https://github.com/wenmuzhou/pytorchocr
- パドル
- Pytorch
- https://github.com/frotms/image_classification_pytorch
- https://github.com/paddlepaddle/paddleocr/blob/release/2.7/doc/doc_ch/models_list.md