Lassen Sie Paddleocroc -trainierte Modelle auf Pytorch verwenden
Geben Sie Referenz für Paddel auf Pytorch an
Beachten
PytorchOCR wird durch PaddleOCRv2.0+ Dynamic Graph -Version portiert.
Neuere Updates
2024.02.20 PP-OCRV4, die mobile und servermodelle bereitstellt
PP-OCRV4-Mobile: Mit vergleichbarer Geschwindigkeit wird der chinesische Szeneffekt im Vergleich zu PP-OCRV3 um 4,5%verbessert, die englische Szene wird um 10%verbessert, und die durchschnittliche Erkennungsgenauigkeit von 80-Sprach-mehrsprachigen Modellen wird um mehr als 8%erhöht.
PP-OCRV4-Server: Das OCR-Modell mit der höchsten Genauigkeit wurde veröffentlicht, wobei die Genauigkeit von Nachweismodellen in chinesischen und englischen Szenarien um 4,9%erhöht wurde und die Genauigkeit der Identifikationsmodelle um 2%erhöht wird.
2023.04.16 Formelidentifikation kann
2023.04.07 Text Supersegment Text Teleskop
2022.10.17 Texterkennung: Vitstr
2022.10.07 Texterkennung: DB ++
2022.07.24 Texterkennungsalgorithmus (FCenet)
2022.07.16 Texterkennungsalgorithmus (SVTR)
2022.06.19 Texterkennungsalgorithmus (SAR)
2022.05.29 PP-OCRV3, wenn die Geschwindigkeit vergleichbar ist, wird der chinesische Szeneffekt im Vergleich zu PP-OCRV2 um 5%erhöht, die englische Szene wird um 11%erhöht und die durchschnittliche Erkennungsgenauigkeit von 80-Sprach-mehrsprachigen Modellen ist um mehr als 5%gestiegen.
2022.05.14 PP-OCRV3 Texterkennungsmodell
2022.04.17 1 Texterkennungsalgorithmus (NRTR)
2022.03.20 1 Texterkennungsalgorithmus (PSENET)
2021.09.11 PP-OCRV2 ist die CPU-Inferenzgeschwindigkeit um 220% höher als die des PP-OCR-Servers; Der Effekt ist um 7% höher als der von PP-OCR Mobile
2021.04.03 Das mehrsprachige Erkennungsmodell aktualisiert, unterstützt derzeit mehr als 27 Sprachen und Downloads von mehrsprachigen Modellen, einschließlich vereinfachter chinesischer, traditioneller Chinesen, Englisch, Französisch, Deutsch, Koreanisch, Japanisch, Italienisch, Spanisch, Portugiesisch, Russisch, Arabisch usw. Nachfolgerplänen können sich auf den mehrsprachigen R & D-Plan beziehen
2021.01.10 kostenloses chinesisches und englisches General OCR -Modell
PP-Structurev2, die Systemfunktionsleistung ist vollständig aktualisiert, an chinesische Szenen angepasst, unterstützt die Layout-Wiederherstellung und unterstützt den Befehl ein Zeilen, um PDF zu vervollständigen.
Layout -Analyse -Modelloptimierung: Die Modellspeicherung wird um 95%verringert, die Geschwindigkeit wird um das 11 -fache erhöht. Die durchschnittliche CPU -Zeit beträgt nur 41 ms
Tabellenerkennungsmodelloptimierung: Entwerfen Sie drei Hauptoptimierungsstrategien, und die Vorhersagezeit wird nicht geändert. Die Modellgenauigkeit wird um 6%verbessert.
Optimierung des Modells für wichtige Informationen zur Extraktion für Informationen: Entwerfen Sie visuell irrelevante Modellstruktur, verbessern Sie die Genauigkeit der Erkennung der semantischen Entität um 2,8%und erhöhen Sie die Genauigkeit der Beziehungsextraktion um 9,1%.
Dokumentstrukturanalyse PP-Struktur-Toolkit, unterstützt Layoutanalyse und Tabellenerkennung (einschließlich Excel-Export)
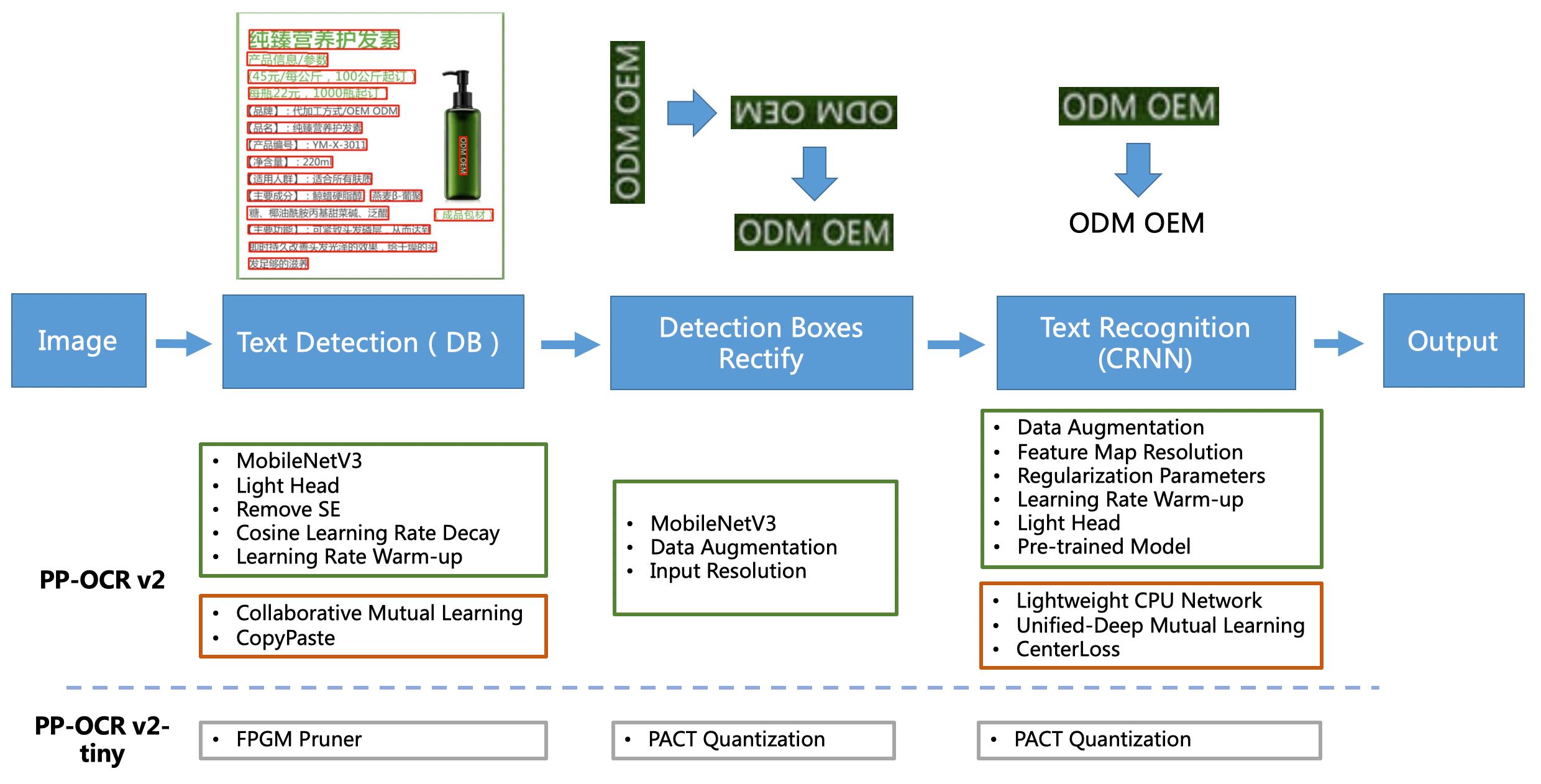
PP-OCRV2 Pipline
[1] PP-OCR ist ein praktisches OR-Lichtgewicht-OCR-System. Es besteht hauptsächlich aus drei Teilen: DB -Texterkennung, Erkennungsrahmenkorrektur und CRNN -Texterkennung. Das System verwendet 19 wirksame Strategien, um die Modelle jedes Moduls aus acht Aspekten zu optimieren und zu schlank: Auswahl und Anpassung des Rückgrates, Vorhersage-Kopfdesign, Datenerweiterung, Lernrate-Transformationsstrategie, Regularisierungsparameterauswahl, Vorausgebliebener Modellkonsum und automatischer Modell-Cropping und quantifizierter Quantierung sowie schließlich erhält ultra-leuchtende chinesische und englische OCR mit einer Gesamtgröße von 3,5 m und 2,8 m. Weitere Informationen finden Sie in der pp-oc-technischen Lösung https://arxiv.org/abs/2009.09941
[2] Basierend auf PP-OCR konzentrierte sich PP-OCRV2 weiter auf die Optimierung in fünf Aspekten. Das Erkennungsmodell übernimmt die CML -Strategie zur Destillationsstrategie für das kollaborative Kenntnisstand von Mutual Learning und die Strategie zur Erhöhung der Copypaste -Daten. Das Identifikationsmodell übernimmt das LCNET Lightweight Backbone Network, die UDML -Verbesserung der Wissensdestillationsstrategie und die Verbesserung der CTC -Verlustverlustfunktion (wie in der roten Box in der obigen Abbildung gezeigt) und verbessert den Inferenzgeschwindigkeit und den Vorhersageeffekt weiter. Weitere Informationen finden Sie im technischen Bericht PP-OCRV2.