Laissez les modèles formés à Paddleocr utiliser sur Pytorch
Fournir une référence à Paddle à Pytorch
Avis
PytorchOCR est porté par la version graphique dynamique PaddleOCRv2.0+ .
Mises à jour récentes
2024.02.20 PP-OCRV4, fournissant des modèles mobiles et de serveurs
PP-OCRV4-MOBILE: Avec une vitesse comparable, l'effet de scène chinoise sera amélioré de 4,5% par rapport à PP-OCRV3, la scène anglaise sera améliorée de 10% et la précision moyenne de reconnaissance des modèles multilingues de 80 langues sera augmentée de plus de 8%.
PP-OCRV4-Server: Le modèle OCR avec la précision la plus élevée a été publié, la précision des modèles de détection dans les scénarios chinois et anglaise étant augmentée de 4,9%, et la précision des modèles d'identification augmentée de 2%.
2023.04.16 L'identification de la formule peut
2023.04.07 TEXTOPE TEXT SUPER TEXE
2022.10.17 Reconnaissance de texte: VITSTR
2022.10.07 Détection de texte: DB ++
2022.07.24 Algorithme de détection de texte (Fcenet)
2022.07.16 Algorithme de reconnaissance de texte (SVTR)
2022.06.19 Algorithme de reconnaissance de texte (SAR)
2022.05.29 PP-OCRV3, Lorsque la vitesse est comparable, l'effet de la scène chinoise est augmenté de 5% par rapport à PP-OCRV2, la scène anglaise est augmentée de 11% et la précision moyenne de reconnaissance des modèles multilingues de 80 langues a augmenté de plus de 5%.
2022.05.14 Modèle de détection de texte PP-OCRV3
2022.04.17 1 Algorithme de reconnaissance de texte (NRTR)
2022.03.20 1 algorithme de détection de texte (PSENET)
2021.09.11 PP-OCRV2, la vitesse d'inférence du CPU est de 220% plus élevée que celle du serveur PP-OCR; L'effet est 7% supérieur à celui du mobile PP-OCR
2021.06.01 Mise à jour SRN
2021.04.25 AAAI 2021 ALGorithm d'identification de bout en bout
2021.04.24 Mise à jour rare
2021.04.12 Mettre à jour Starnet
2021.04.08 MISE À JOUR DB, SAST, EST, ROSETTA, CRNN
2021.04.03 Mise à jour du modèle de reconnaissance multilingue, prend actuellement en charge plus de 27 langues et des téléchargements de modèles multilingues, y compris chinois simplifié, chinois traditionnel, anglais, français, allemand, coréen, japonais, italien, espagnol, portugais, russe, arabe, etc.
2021.01.10 modèle OCR général chinois et anglais gratuit
caractéristiques
Modèle d'inférence de haute qualité, effet de reconnaissance précis
Série PP-OCR ultra-légère: Détection + Classificateur de direction + Identification
Série de terminaux mobiles Ptocr_Mobile ultra-légers
Série générale ptocr_server
Prend en charge la reconnaissance de la combinaison numérique chinois et anglaise, la reconnaissance de texte vertical et la reconnaissance longue du texte
Soutient la reconnaissance multilingue: coréen, japonais, allemand, français, etc.
Liste des modèles (mise à jour)
Lien de téléchargement du modèle Pytorch: https://pan.baidu.com/s/1r1delt8blgxeop2rqrejeg Code d'extraction: 6clx
Paddleococr Modèle Baidu Network Disk Link: https://pan.baidu.com/s/1getaprt2l_jqwhjwml0g9g Code d'extraction: LMV7
Pour plus de téléchargements de modèles (y compris multilingues), vous pouvez vous référer aux téléchargements du modèle PT-OCR V2.0
Tutoriel de documentation
Installation rapide
Prédiction du modèle
Gigogne
Affichage d'effet
Références
FAQ
se référer à
FAIRE
Algorithme de frontière: détection de texte DRRG, reconnaissance de texte RFL
Reconnaissance du texte: Abinet, Visionlan, Spin, RobustScanner
Reconnaissance de la table: Tablemaster
PP-StructureV2, les performances de la fonction du système sont entièrement mises à niveau, adaptées aux scènes chinoises, une prise en charge supplémentaire de la restauration de la mise en page et prend en charge la commande en une ligne pour terminer le PDF à Word
Analyse de disposition Optimisation du modèle: le stockage du modèle est réduit de 95%, la vitesse est augmentée de 11 fois, le temps moyen du processeur n'est que de 41 ms
Optimisation du modèle de reconnaissance du tableau: Concevoir trois principales stratégies d'optimisation et le temps de prédiction n'est pas modifié, la précision du modèle est améliorée de 6%.
Optimisation du modèle d'extraction d'informations clés: Concevoir une structure de modèle visuellement non pertinente, améliorer la précision de la reconnaissance de l'entité sémantique de 2,8% et augmenter la précision de l'extraction des relations de 9,1%.
Analyse de la structure des documents PP-structure Toolkit, prend en charge l'analyse de la disposition et la reconnaissance du tableau (y compris Excel Export)
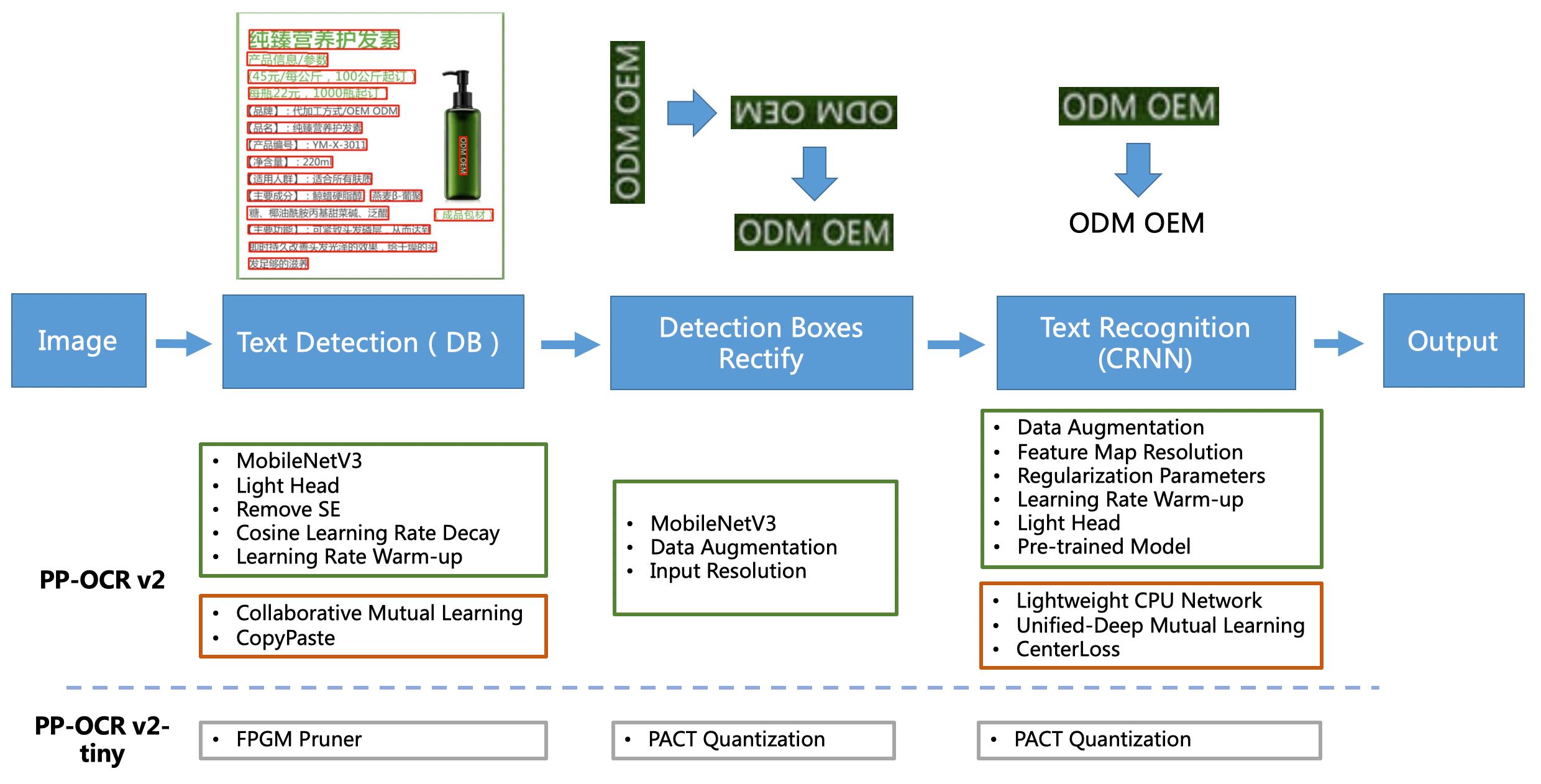
PP-OCRV2 Pipline
[1] PP-OCR est un système OCR ultra-léger pratique. Il se compose principalement de trois parties: détection de texte DB, correction du cadre de détection et reconnaissance de texte CRNN. Le système utilise 19 stratégies efficaces pour optimiser et éliminer les modèles de chaque module à partir de huit aspects: sélection et ajustement du réseau de squelette, conception de la tête de prédiction, augmentation des données, stratégie de transformation du taux d'apprentissage, sélection des paramètres de régularisation, utilisation du modèle pré-formé et COMMENTATION DU MODÈLE AUTOMATIQUE ET QUANTILISATION, et enfin obtient un OCR chinois et anglais ultra-léger avec une taille globale de 3,5m et 2,8m Pour plus de détails, veuillez vous référer à la solution technique PP-OCR https://arxiv.org/abs/2009.09941
[2] Sur la base de PP-OCR, PP-OCRV2 s'est en outre concentré sur l'optimisation dans cinq aspects. Le modèle de détection adopte la stratégie de distillation des connaissances mutuelles collaboratives de LMC et la stratégie d'augmentation des données Copypaste; Le modèle d'identification adopte le réseau de squelette léger LCNET, la stratégie de distillation de connaissances améliorée UDML et l'amélioration améliorée de la fonction de perte de perte CTC (comme indiqué dans la boîte rouge dans la figure ci-dessus), améliorant davantage la vitesse d'inférence et l'effet de prédiction. Pour plus de détails, veuillez vous référer au rapport technique PP-OCRV2.