Deje que los modelos entrenados en Padleocr se usen en Pytorch
Proporcionar referencia para Paddle a Pytorch
Aviso
PytorchOCR está portado por la versión de gráfico dinámico PaddleOCRv2.0+ .
Actualizaciones recientes
2024.02.20 PP-OCRV4, que proporciona modelos móviles y servidores
PP-OCRV4-Mobile: con una velocidad comparable, el efecto de la escena chino se mejorará en un 4,5%en comparación con PP-OCRV3, la escena inglesa mejorará en un 10%, y la precisión promedio de reconocimiento de 80 modelos multilingüe de idiomas aumentará en más del 8%.
PP-OCRV4-server: se ha liberado el modelo OCR con la mayor precisión, con la precisión de los modelos de detección en escenarios chinos e ingleses aumentados en un 4,9%, y la precisión de los modelos de identificación aumenta en un 2%.
2023.04.16 La identificación de fórmula puede
2023.04.07 Telescopio de texto Super segmento de texto
2022.10.17 Reconocimiento de texto: Vitstr
2022.10.07 Detección de texto: DB ++
2022.07.24 Algoritmo de detección de texto (FCENET)
2022.07.16 Algoritmo de reconocimiento de texto (SVTR)
2022.06.19 Algoritmo de reconocimiento de texto (SAR)
2022.05.29 PP-OCRV3, cuando la velocidad es comparable, el efecto de la escena chino aumenta en un 5%en comparación con PP-OCRV2, la escena inglesa aumenta en un 11%y la precisión promedio de reconocimiento de 80 modelos multilingües de idiomas ha aumentado en más del 5%.
2022.05.14 Modelo de detección de texto PP-OCRV3
2022.04.17 1 Algoritmo de reconocimiento de texto (NRTR)
2022.03.20 1 Algoritmo de detección de texto (Psenet)
2021.09.11 PP-OCRV2, la velocidad de inferencia de la CPU es 220% más alta que la del servidor PP-OCR; El efecto es un 7% más alto que el de PP-OCR Mobile
2021.06.01 Actualización SRN
2021.04.25 Actualizado AAAI 2021 Algoritmo de identificación de papel a extremo PGNET
2021.04.24 Actualización rara
2021.04.12 Actualización de Starnet
2021.04.08 DB actualizado, SAST, East, Rosetta, CRNN
2021.04.03 actualizó el modelo de reconocimiento multilingüe, actualmente admite más de 27 idiomas y descargas de modelos multilingües, incluidos los planes de seguimiento chino, tradicional chino, inglés, francés, alemán, coreanos, japoneses, italianos, españoles, rusos, rusos, rusos, etc.
2021.01.10 modelo de OCR general chino e inglés gratis
característica
Modelo de inferencia de alta calidad, efecto de reconocimiento preciso
Serie PP-OCR ultra ligera: Clasificador de detección + dirección + identificación
Serie Ptocr_Mobile Mobile Terminal de peso ultra ligero
Serie General Ptocr_Server
Admite reconocimiento de combinación digital china e inglesa, reconocimiento de texto vertical y reconocimiento de texto largo
Apoya el reconocimiento multilingüe: coreano, japonés, alemán, francés, etc.
Lista de modelos (actualizado)
Enlace de descarga del modelo Pytorch: https://pan.baidu.com/s/1r1delt8blgxeop2rqrejeg Código de extracción: 6CLX
Modelo Padleocr Modelo Baidu Network Disk Enlace: https://pan.baidu.com/s/1getaprt2l_jqwhjwml0g9g Código de extracción: LMV7
Para obtener más descargas de modelos (incluida la multilingüe), puede consultar las descargas de modelos de la serie PT-OCR V2.0
Tutorial de documentación
Instalación rápida
Predicción del modelo
Línea de pipa
Visualización de efectos
Referencias
Preguntas frecuentes
referirse a
HACER
Algoritmo Frontier: Detección de texto DRRG, Reconocimiento de texto RFL
Reconocimiento de texto: Abinet, VisionLan, Spin, RobustScanner
Reconocimiento de la tabla: Tablemaster
PP-StructureV2, el rendimiento de la función del sistema se actualiza completamente, se adapta a escenas chinas, se agregó soporte para la restauración del diseño y admite el comando de una línea para completar PDF a Word a Word
Análisis de diseño Optimización del modelo: el almacenamiento del modelo se reduce en un 95%, la velocidad aumenta 11 veces, el tiempo promedio de la CPU es de solo 41 ms
Optimización del modelo de reconocimiento de tabla: diseñar tres estrategias de optimización principales, y el tiempo de predicción no cambia, la precisión del modelo mejora en un 6%.
Optimización del modelo de extracción de información clave: diseñar una estructura del modelo visualmente irrelevante, mejorar la precisión del reconocimiento de entidades semánticas en un 2,8%y aumentar la precisión de la extracción de relaciones en un 9,1%.
Algoritmo de reconocimiento de texto (semilla)
Documento Algoritmo Estructurado Algoritmo de extracción de información clave (SDMGR)
Análisis de estructura de documentos PP-Estructura de herramientas de herramientas, admite el análisis de diseño y el reconocimiento de la tabla (incluida la exportación de Excel)
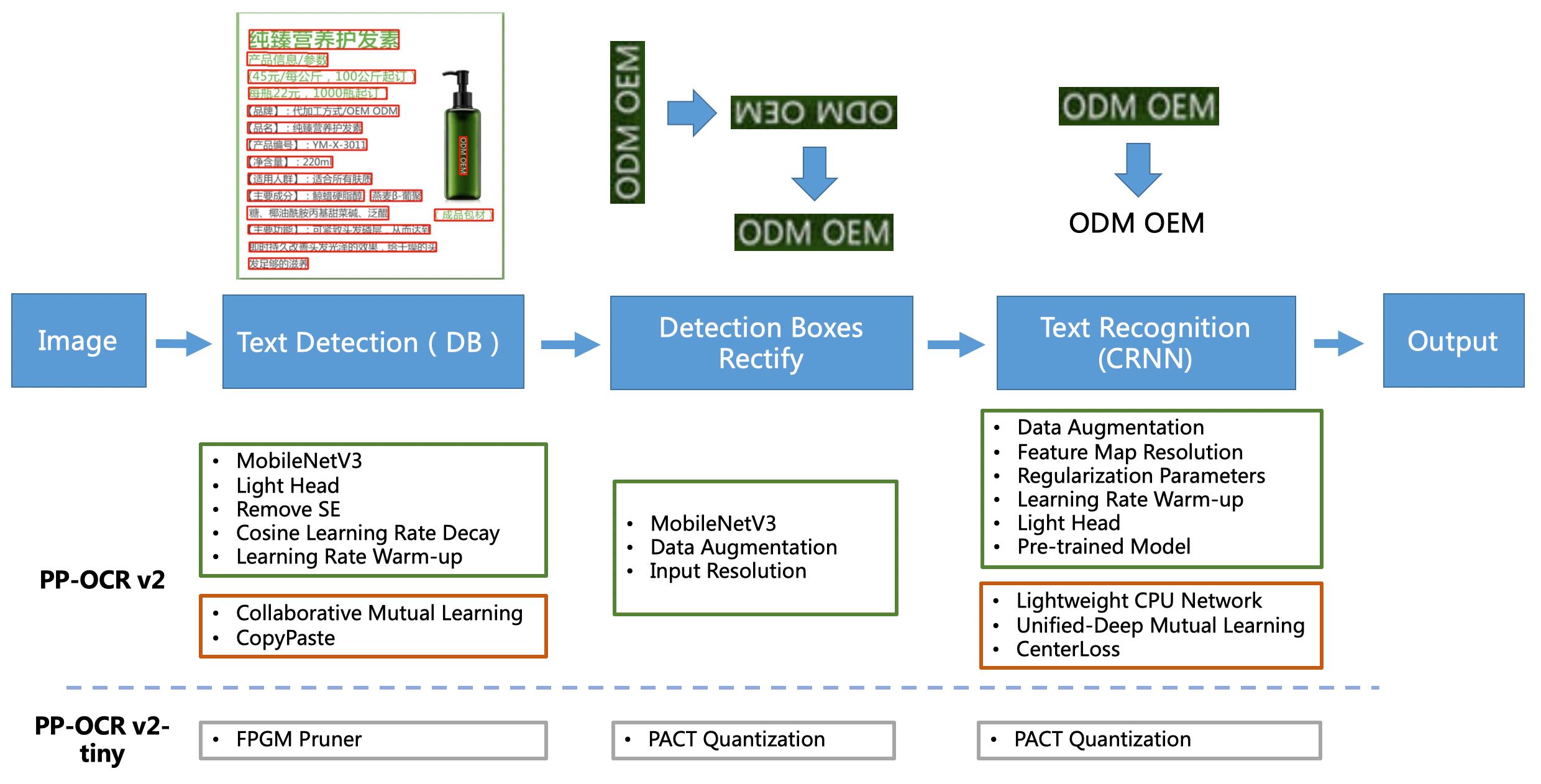
PP-OCRV2 Pipline
[1] PP-OCOC es un sistema OCR práctico de peso ultraligero. Consiste principalmente en tres partes: detección de texto de DB, corrección del marco de detección y reconocimiento de texto de CRNN. El sistema utiliza 19 estrategias efectivas para optimizar y adelgazar los modelos de cada módulo a partir de ocho aspectos: selección y ajuste de red de backbone, diseño de cabezal de predicción, aumento de datos, estrategia de transformación de tasa de aprendizaje, selección de parámetros de regularización, uso de modelos previamente capacitados y cultivo y cuantificación de modelos automáticos automáticos, y finalmente obtienen OCR chino ultra ligero e inglés con un tamaño total de 3.5M y 2.8M en el modelos de OCR en inglés. Para obtener más detalles, consulte la solución técnica PP-OOC https://arxiv.org/abs/2009.09941
[2] Basado en PP-OCR, PP-OCRV2 se centró aún más en la optimización en cinco aspectos. El modelo de detección adopta la estrategia de destilación de conocimiento de aprendizaje mutuo colaborativo de CML y estrategia de aumento de datos de copypaste; El modelo de identificación adopta la red de columna vertebral liviana LCNET, UDML mejoró la estrategia de destilación de conocimiento y mejoró la mejora de la función de pérdida de pérdida de CTC (como se muestra en el cuadro rojo en la figura anterior), mejorando aún más la velocidad de inferencia y el efecto de predicción. Para obtener más detalles, consulte el informe técnico PP-OCRV2.