lightning hydra template
v2.0.3
Um modelo limpo para iniciar seu projeto de aprendizado profundo ⚡
Clique em Use este modelo para inicializar o novo repositório.
As sugestões são sempre bem -vindas!
Por que você pode querer usá -lo:
✅ Salvar no caldeira
Adicione facilmente novos modelos, conjuntos de dados, tarefas, experimentos e treine em diferentes aceleradores, como clusters multi-GPU, TPU ou Slurm.
✅ Educação
Comentado completamente. Você pode usar este repositório como um recurso de aprendizado.
✅ REUSIBILIDADE
Coleção de ferramentas úteis, configurações e trechos de código. Você pode usar este repositório como referência para vários utilitários.
Por que você pode não querer usá -lo:
As coisas quebram de tempos em tempos
Lightning e Hydra ainda estão evoluindo e integram muitas bibliotecas, o que significa que às vezes as coisas quebram. Para a lista de problemas atualmente conhecidos, visite esta página.
Não ajustado para engenharia de dados
O modelo não é realmente ajustado para a criação de dutos de dados que dependem um do outro. É mais eficiente usá-lo para prototipagem de modelo em dados prontos para uso.
Caso de uso simples para uso simples
A configuração da configuração é construída com um simples treinamento de raios em mente. Pode ser necessário fazer algum esforço para ajustá -lo para diferentes casos de uso, por exemplo, tecido de raio.
Pode não suportar seu fluxo de trabalho
Por exemplo, você não pode retomar a pesquisa multirun ou hiperparâmetro baseada em Hydra.
Nota : Lembre -se de que este é um projeto comunitário não oficial.
Pytorch Lightning - Um invólucro leve Pytorch para pesquisa de IA de alto desempenho. Pense nisso como uma estrutura para organizar seu código Pytorch.
HYDRA - Uma estrutura para configurar elegantemente aplicativos complexos. O recurso principal é a capacidade de criar dinamicamente uma configuração hierárquica por composição e substituí -la através de arquivos de configuração e a linha de comando.
A estrutura do diretório do novo projeto se parece com o seguinte:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt O modelo contém exemplo com classificação MNIST.
Ao executar python src/train.py você deve ver algo assim:
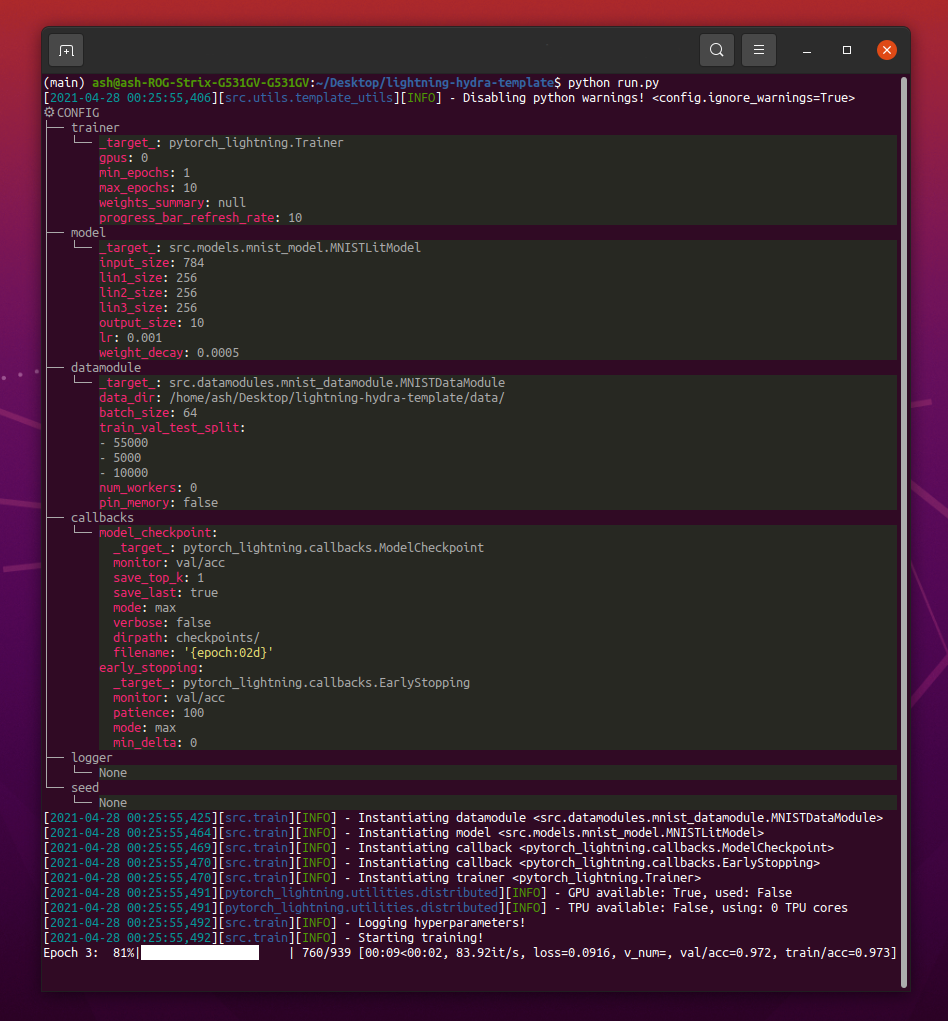
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4Nota : Você também pode adicionar novos parâmetros com
+sinal.
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mpsAVISO : Atualmente, existem problemas com o modo DDP, leia esse problema para saber mais.
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandbNOTA : O Lightning fornece integrações convenientes com as estruturas de registro mais populares. Saiba mais aqui.
NOTA : O uso do WANDB exige que você configure a conta primeiro. Depois disso, apenas complete a configuração como abaixo.
NOTA : Clique aqui para ver o Exemplo Wandb Painel gerado com este modelo.
python train.py experiment=exampleNota : As configurações de experimento são colocadas em configurações/experimento/.
python train.py callbacks=defaultNOTA : Os retornos de chamada podem ser usados para coisas como verificação de modelo, parada precoce e muito mais.
Nota : as configurações de retorno de chamada são colocadas em configurações/retornos de chamada/.
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"NOTA : O Pytorch Lightning fornece mais de 40 sinalizadores úteis de treinadores.
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2Nota : Visite Configs/ Debug/ para diferentes configurações de depuração.
python train.py ckpt_path="/path/to/ckpt/name.ckpt"NOTA : O ponto de verificação pode ser o caminho ou o URL.
NOTA : Atualmente, o carregamento do CKPT não retomará o experimento de logger, mas será suportado no futuro lançamento do Lightning.
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"NOTA : O ponto de verificação pode ser o caminho ou o URL.
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005Nota : Hydra compõe as configurações preguiçosamente no horário de lançamento do trabalho. Se você alterar o código ou as configurações após o lançamento de um trabalho/varredura, as configurações finais compostas poderão ser impactadas.
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=exampleNOTA : Usando o Sweeper Optuna não exige que você adicione qualquer placa de caldeira ao seu código, tudo é definido em um único arquivo de configuração.
Aviso : as varreduras de optuna não são resistentes a falhas (se um trabalho travar, toda a varredura falha).
python train.py -m ' experiment=glob(*) 'Nota : O Hydra fornece sintaxe especial para controlar o comportamento de multiruns. Saiba mais aqui. O comando acima executa todas as experiências de configurações/experimentos/.
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]Nota :
trainer.deterministic=Truetorna o pytorch mais determinístico, mas afeta o desempenho.
NOTA : Isso deve ser possível com a configuração simples usando o Ray Aws Launcher para Hydra. Exemplo não é implementado neste modelo.
NOTA : O Hydra permite que você preencha o argumento de configuração automática no shell ao escrever, pressionando a tecla
tab. Leia os documentos.
pre-commit run -aNota : Aplique ganchos de pré-compromisso para fazer coisas como código e configurações de formatação automática, execução de análise de código ou removendo a saída dos notebooks Jupyter. Veja # Melhores práticas para mais.
Atualize versões de gancho pré-comprometido em .pre-commit-config.yaml com:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Cada experimento deve ser marcado para filtrá -los facilmente entre os arquivos ou na interface do usuário do Logger:
python train.py tags=[ " mnist " , " experiment_X " ]NOTA : Pode ser necessário escapar dos caracteres do suporte em seu shell com
python train.py tags=["mnist","experiment_X"].
Se nenhuma tags for fornecida, você será solicitado a inseri -las na linha de comando:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):Se nenhuma tags for fornecida para multirun, será levantado um erro:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !NOTA : As listas de anexos da linha de comando atualmente não são suportadas na Hydra :(
Este projeto existe graças a todas as pessoas que contribuem.
Tem uma pergunta? Encontrou um bug? Faltando um recurso específico? Sinta -se à vontade para arquivar um novo problema, discussão ou relações públicas com o respectivo título e descrição.
Antes de fazer um problema, verifique se:
main atual.Sugestões de melhorias são sempre bem -vindas!
Todos os módulos de Lightning Pytorch são instantados dinamicamente dos caminhos do módulo especificados na configuração. Exemplo de configuração de modelo:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10Usando esta configuração, podemos instanciar o objeto com a seguinte linha:
model = hydra . utils . instantiate ( config . model ) Isso permite que você itera facilmente sobre novos modelos! Toda vez que você cria um novo, basta especificar o caminho e os parâmetros do módulo no arquivo de configuração apropriado.
Alterne entre modelos e datamodules com argumentos da linha de comando:
python train.py model=mnistExemplo de pipeline gerenciando a lógica de instanciação: src/tren.py.
Localização: Configs/Train.yaml
A configuração principal do projeto contém configuração de treinamento padrão.
Ele determina como a configuração é composta ao simplesmente executar o comando python train.py
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null Localização: configurações/experimento
As configurações de experimento permitem que você substitua os parâmetros da configuração principal.
Por exemplo, você pode usá -los para controlar a versão dos melhores hiperparâmetros para cada combinação de modelo e conjunto de dados.
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " Fluxo de trabalho básico
python src/train.py experiment=experiment_name.yamlProjeto de experimento
Digamos que você deseja executar muitas corridas para plotar como as mudanças de precisão em relação ao tamanho do lote.
Execute as execuções com algum parâmetro de configuração que permite identificá -los facilmente, como tags:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] Escreva um script ou notebook que pesquise os logs/ pasta e recupere logs CSV de execuções contendo tags especificadas na configuração. Plote os resultados.
A Hydra cria um novo diretório de saída para cada execução executada.
Estrutura de registro padrão:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
Você pode alterar essa estrutura modificando os caminhos na configuração do HYDRA.
O Pytorch Lightning suporta muitas estruturas populares de registro: pesos e vieses, Netuno, Comet, MLFlow, Tensorboard.
Essas ferramentas ajudam você a acompanhar os hiperparâmetros e as métricas de saída e permitir que você compare e visualize resultados. Para usar um deles, basta concluir sua configuração em Configs/Logger e Run:
python train.py logger=logger_nameVocê pode usar muitos deles de uma só vez (consulte Configs/Logger/Many_loggers.yaml, por exemplo).
Você também pode escrever seu próprio logger.
O Lightning fornece um método conveniente para registrar métricas personalizadas de Inside LightningModule. Leia os documentos ou dê uma olhada no exemplo mnist.
O modelo vem com testes genéricos implementados com pytest .
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "A maioria dos testes implementados não verifica nenhuma saída específica - eles existem para simplesmente verificar se a execução de alguns comandos não acaba em lançar exceções. Você pode executá -los de vez em quando para acelerar o desenvolvimento.
Atualmente, os testes cobrem casos como:
E muitos outros. Você deve ser capaz de modificá -los facilmente para o seu caso de uso.
Há também @RunIf Decorator implementado, que permite executar testes apenas se determinadas condições forem atendidas, por exemplo, a GPU estiver disponível ou o sistema não for Windows. Veja os exemplos.
Você pode definir a pesquisa de hyperparameter adicionando novo arquivo de configuração às configurações/hparams_search.
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256) Em seguida, execute -o com: python train.py -m hparams_search=mnist_optuna
Usando essa abordagem não requer adição de qualquer caldeira ao código, tudo é definido em um único arquivo de configuração. A única coisa necessária é retornar o valor métrico otimizado do arquivo de lançamento.
Você pode usar diferentes estruturas de otimização integradas ao HYDRA, como optuna, machado ou nunca.
O optimization_results.yaml estará disponível na pasta logs/task_name/multirun .
Essa abordagem não suporta retomar a pesquisa interrompida e técnicas avançadas como a poda - para pesquisas e fluxos de trabalho mais sofisticados, você provavelmente deve escrever uma tarefa de otimização dedicada (sem recurso multirun).
O modelo vem com os fluxos de trabalho do CI implementados nas ações do GitHub:
.github/workflows/test.yaml : executando todos os testes com pytest.github/workflows/code-quality-main.yaml : executando pré-compromissos na filial principal para todos os arquivos.github/workflows/code-quality-pr.yaml : executando pré-compromissos em solicitações de tração apenas para arquivos modificados O Lightning suporta várias maneiras de fazer treinamento distribuído. O mais comum é o DDP, que gera um processo separado para cada GPU e calcula os gradientes entre eles. Para aprender sobre outras abordagens, leia os documentos de raios.
Você pode executar o DDP no MNIST Exemplo com 4 GPUs como este:
python train.py trainer=ddpNOTA : Ao usar o DDP, você deve ter cuidado para que escreva seus modelos - leia os documentos.
A maneira mais simples é passar o atributo datamodule diretamente ao modelo na inicialização:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )NOTA : Não é uma solução muito robusta, pois assume que todos os seus datamodules têm algum atributo
some_paramdisponível.
Da mesma forma, você pode passar por toda uma configuração de datamodule como um parâmetro init:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )Você também pode passar um parâmetro de configuração de datamodule para o seu modelo por meio de interpolação variável:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}Outra abordagem é acessar o Datamodule no LightningModule diretamente através do treinador:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_paramNOTA : Isso funciona apenas após o início do treinamento, pois, caso contrário, o treinador ainda não estará disponível no LightningModule.
Geralmente, é desnecessário instalar o ambiente completo da Anaconda, o Miniconda deve ser suficiente (pesos em torno de 80 MB).
A grande vantagem do CONDA é que ele permite a instalação de pacotes sem exigir que determinados compiladores ou bibliotecas estejam disponíveis no sistema (pois instala binários pré -compilados), por isso geralmente facilita a instalação de algumas dependências, por exemplo, o Cudatoolkit para o suporte à GPU.
Ele também permite acessar seus ambientes globalmente, o que pode ser mais conveniente do que criar um novo ambiente local para cada projeto.
Exemplo de instalação:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shAtualize o CoNA:
conda update -n base -c defaults condaCrie um novo ambiente de conda:
conda create -n myenv python=3.10
conda activate myenv Use ganchos pré-comprometidos para padronizar a formatação do código do seu projeto e economizar energia mental.
Basta instalar o pacote pré-comprometimento com:
pip install pre-commitEm seguida, instale ganchos de .pre-com-config.yaml:
pre-commit installDepois disso, seu código será automaticamente reformado em cada novo compromisso.
Para reformar todos os arquivos no comando Use do projeto:
pre-commit run -aPara atualizar as versões do gancho em .Pre-com-config.yaml use:
pre-commit autoupdate Variáveis específicas do sistema (por exemplo, caminhos absolutos para os conjuntos de dados) não devem estar sob controle de versão ou resultará em conflitos entre diferentes usuários. Suas chaves particulares também não devem ser versadas, pois você não deseja que elas vazem.
O modelo contém o arquivo .env.example , que serve como exemplo. Crie um novo arquivo chamado .env (esse nome é excluído do controle da versão no .gitignore). Você deve usá -lo para armazenar variáveis de ambiente como esta:
MY_VAR=/home/user/my_system_path
Todas as variáveis do .env são carregadas no train.py automaticamente.
Hydra permite que você faça referência a qualquer variável Env em configurações .yaml como esta:
path_to_data : ${oc.env:MY_VAR} Dependendo de qual madeireiro você está usando, geralmente é útil definir o nome métrico com / personagem:
self . log ( "train/loss" , loss )Dessa forma, os madeireiros tratarão suas métricas como pertencentes a diferentes seções, o que ajuda a organizá -las na interface do usuário.
Use a Biblioteca Oficial Torchmetrics para garantir o cálculo adequado das métricas. Isso é especialmente importante para o treinamento multi-GPU!
Por exemplo, em vez de calcular a precisão por si mesmo, você deve usar a classe Accuracy fornecida como esta:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...Certifique -se de usar a instância métrica diferente para cada etapa para garantir a redução adequada do valor em todos os processos da GPU.
A Torchmetrics fornece métricas para a maioria dos casos de uso, como a pontuação de F1 ou a matriz de confusão. Leia a documentação para mais.
O guia de estilo está disponível aqui.
Seja explícito em seu init. Tente definir todos os padrões relevantes para que o usuário não precise adivinhar. Forneça dicas de tipo. Dessa forma, seu módulo é reutilizável em projetos!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):Preserve a ordem do método recomendado.
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
... Use o DVC para controlar a versão de arquivos grandes, como seus dados ou modelos ML treinados.
Para inicializar o repositório de DVC:
dvc init Para começar a rastrear um arquivo ou diretório, use dvc add :
dvc add data/MNISTO DVC armazena informações sobre o arquivo adicionado (ou um diretório) em um arquivo .dvc especial chamado Data/mnist.dvc, um pequeno arquivo de texto com um formato legível por humanos. Este arquivo pode ser facilmente versado como código -fonte com o GIT, como um espaço reservado para os dados originais:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data " Ele permite que outras pessoas usem facilmente seus módulos em seus próprios projetos. Altere o nome da pasta src para o nome do seu projeto e preencha o arquivo setup.py .
Agora seu projeto pode ser instalado a partir de arquivos locais:
pip install -e .Ou diretamente do Repositório Git:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradePortanto, qualquer arquivo pode ser facilmente importado para qualquer outro arquivo como assim:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModuleAlgumas configurações são específicos de usuário/máquina/instalação (por exemplo, configuração do cluster local ou caminhos de duração em uma máquina específica). Para tais cenários, pode ser criado um arquivo configs/local/default.yaml, que é carregado automaticamente, mas não rastreado pelo Git.
Por exemplo, você pode usá -lo para uma configuração de cluster slurm:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd Este modelo foi inspirado por:
Outros repositórios úteis:
Lightning-Hydra-Template é licenciado sob a licença do MIT.
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Exclua tudo acima para o seu projeto
O que faz
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvModelo de trem com configuração padrão
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpuModelo de trem com configuração de experimento escolhido de configurações/experimento//
python src/train.py experiment=experiment_name.yamlVocê pode substituir qualquer parâmetro da linha de comando como esta
python src/train.py trainer.max_epochs=20 data.batch_size=64

