lightning hydra template
v2.0.3
深い学習プロジェクトをキックスタートするためのきれいなテンプレート⚡
このテンプレートを使用して、新しいリポジトリを初期化します。
提案はいつでも大歓迎です!
なぜあなたがそれを使いたいかもしれないかもしれない:
bulerplateを保存します
新しいモデル、データセット、タスク、実験、およびMulti-GPU、TPU、Slurmクラスターなどのさまざまな加速器で簡単に追加します。
✅教育
徹底的にコメントしました。このレポは学習リソースとして使用できます。
rusabily再利用性
便利なMLOPSツール、構成、およびコードスニペットのコレクション。このレポは、さまざまなユーティリティのリファレンスとして使用できます。
なぜあなたはそれを使いたくないかもしれないかもしれない:
物事は時々壊れます
LightningとHydraはまだ多くのライブラリを進化させ、統合しています。つまり、物事が壊れることもあります。現在既知の問題のリストについては、このページをご覧ください。
データエンジニアリング用に調整されていません
テンプレートは、互いに依存するデータパイプラインを構築するために実際に調整されていません。すぐに使用できるデータのモデルプロトタイピングに使用する方が効率的です。
単純なユースケースに過度に装備されています
構成セットアップは、簡単な稲妻トレーニングを念頭に置いて構築されています。さまざまなユースケース(稲妻布)に合わせて調整するために、ある程度の努力をする必要があるかもしれません。
ワークフローをサポートしない可能性があります
たとえば、HydraベースのMultirunまたはHyperParameter検索を再開することはできません。
注:これは非公式のコミュニティプロジェクトであることに留意してください。
Pytorch Lightning-高性能AI研究のための軽量のPytorchラッパー。 Pytorchコードを整理するためのフレームワークと考えてください。
Hydra-複雑なアプリケーションをエレガントに構成するためのフレームワーク。重要な機能は、構成によって階層構成を動的に作成し、構成ファイルとコマンドラインを介してオーバーライドする機能です。
新しいプロジェクトのディレクトリ構造は次のようになります:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txtテンプレートには、Mnist分類の例が含まれています。
python src/train.pyを実行するときは、次のようなものが表示されるはずです。
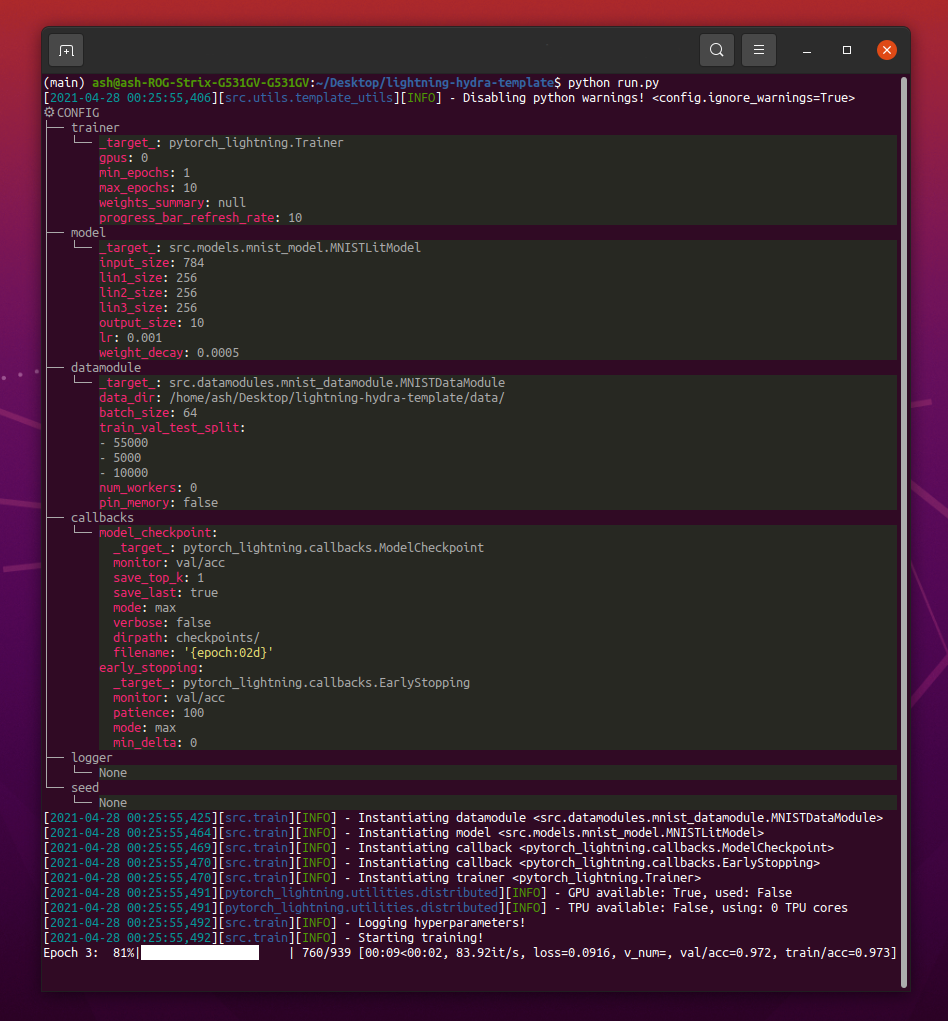
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4注:
+サインを含む新しいパラメーターを追加することもできます。
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mps警告:現在、DDPモードに問題があります。この問題を読んで詳細を確認してください。
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandb注:Lightningは、最も人気のあるロギングフレームワークと便利な統合を提供します。詳細はこちらをご覧ください。
注:WANDBを使用するには、最初にアカウントを設定する必要があります。その後、以下のように構成を完了します。
注:ここをクリックして、このテンプレートで生成されたWandbダッシュボードの例をご覧ください。
python train.py experiment=example注:実験構成はconfigs/experiment/に配置されます。
python train.py callbacks=default注:コールバックは、モデルチェックポイント、早期停止など、その他などに使用できます。
注:コールバック構成は、configs/callbacks/に配置されます。
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"注:Pytorch Lightningは、約40以上の有用なトレーナーフラグを提供します。
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2注:さまざまなデバッグ構成については、configs/ debug/にアクセスします。
python train.py ckpt_path="/path/to/ckpt/name.ckpt"注:チェックポイントは、パスまたはURLのいずれかにすることができます。
注:現在、CKPTのロードはLogger実験を再開しませんが、将来のLightningリリースでサポートされます。
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"注:チェックポイントは、パスまたはURLのいずれかにすることができます。
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005注:Hydraは、ジョブの起動時に怠lazに構成を構成します。ジョブ/スイープを起動した後にコードまたは構成を変更すると、最終的な構成構成が影響を受ける可能性があります。
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=example注:Optuna Sweeperを使用すると、ボイラープレートをコードに追加する必要はありません。すべてが単一の構成ファイルで定義されています。
警告:Optuna Sweepsは失敗に耐えることはありません(1つのジョブがクラッシュすると、スイープ全体がクラッシュします)。
python train.py -m ' experiment=glob(*) '注:Hydraは、マルチランの動作を制御するための特別な構文を提供します。詳細はこちらをご覧ください。上記のコマンドは、configs/experiment/のすべての実験を実行します。
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]注:
trainer.deterministic=TruePytorchをより決定論的にしますが、パフォーマンスに影響を与えます。
注:これは、Hydra用のRay AWSランチャーを使用したSimple Configで達成できる必要があります。このテンプレートには例が実装されていません。
注:Hydraを使用すると、
tabを押して、それらを書くときにシェルの構成引数オーバーライドをオートコンプリートできます。ドキュメントを読んでください。
pre-commit run -a注:事前にコミットのフックを適用して、オートフォーマットコードや構成、コード分析の実行、Jupyterノートブックからの出力の削除などを行います。詳細については、#ベストプラクティスを参照してください。
.pre-commit-config.yamlの事前コミットフックバージョンを次のように更新します。
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "各実験は、ファイル間またはロガーUIで簡単にフィルタリングするためにタグ付けする必要があります。
python train.py tags=[ " mnist " , " experiment_X " ]注:
python train.py tags=["mnist","experiment_X"]を使用して、シェル内のブラケット文字を脱出する必要がある場合があります。
タグが提供されていない場合は、コマンドラインからタグを入力するように求められます。
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):MultiRunにタグが提供されていない場合、エラーが発生します。
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !注:コマンドラインからのアプリのリストは現在、Hydraではサポートされていません:(
このプロジェクトは、貢献するすべての人々のおかげで存在します。
質問がありますか?バグを見つけましたか?特定の機能がありませんか?それぞれのタイトルと説明で、新しい問題、ディスカッション、またはPRを自由に提出してください。
問題を作成する前に、それを確認してください:
mainブランチに存在します。改善の提案はいつでも大歓迎です!
すべてのPytorch Lightningモジュールは、構成で指定されたモジュールパスから動的にインスタンス化されます。モデル構成の例:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10この構成を使用して、次の行でオブジェクトをインスタンス化できます。
model = hydra . utils . instantiate ( config . model )これにより、新しいモデルを簡単に反復させることができます!新しいものを作成するたびに、適切な構成ファイルでモジュールパスとパラメーターを指定するだけです。
コマンドライン引数を使用して、モデルとデータモジュールを切り替えます。
python train.py model=mnistインスタンス化ロジックの管理の例:src/train.py。
場所:configs/train.yaml
メインプロジェクト構成には、デフォルトのトレーニング構成が含まれています。
コマンドpython train.pyを単純に実行するときの構成の構成方法を決定します。
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null 場所:構成/実験
実験構成では、メイン構成からパラメーターを上書きすることができます。
たとえば、それらを使用して、モデルとデータセットの組み合わせごとに最適なハイパーパラメーターを制御できます。
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " 基本的なワークフロー
python src/train.py experiment=experiment_name.yaml実験設計
多くの実行を実行して、バッチサイズに関して精度がどのように変化するかをプロットしたいとします。
タグなど、簡単に識別できる構成パラメーターで実行を実行します。
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] logs/フォルダーを検索するスクリプトまたはノートブックを作成し、設定されたタグを含む実行からCSVログを取得します。結果をプロットします。
Hydraは、実行されるたびに新しい出力ディレクトリを作成します。
デフォルトのロギング構造:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
Hydra構成でパスを変更することにより、この構造を変更できます。
Pytorch Lightningは、Weights&Biases、Neptune、Comet、MLFlow、Tensorboardなど、人気のあるロギングフレームワークをサポートしています。
これらのツールは、ハイパーパラメーターと出力メトリックを追跡し、結果を比較および視覚化できるようにするのに役立ちます。それらのいずれかを使用するには、構成/ロガーで構成を完了して実行します。
python train.py logger=logger_nameそれらの多くを一度に使用できます(たとえば、configs/logger/many_loggers.yamlを参照してください)。
また、独自のロガーを書くこともできます。
Lightningは、内部のLightningModuleからカスタムメトリックを記録するための便利な方法を提供します。ドキュメントを読むか、Mnistの例をご覧ください。
テンプレートには、 pytestで実装された一般的なテストが付属しています。
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "実装されたテストのほとんどは、特定の出力をチェックしません - それらは、いくつかのコマンドを実行することが例外をスローすることに終わらないことを単純に確認するために存在します。開発をスピードアップするために、たまに実行できます。
現在、テストは次のようなケースをカバーしています。
そして他の多く。ユースケースのために簡単に変更できるはずです。
また、 @RunIfデコレーターが実装されているため、特定の条件が満たされている場合、たとえばGPUが利用可能であるか、システムがWindowsではない場合にのみテストを実行できます。例を参照してください。
configs/hparams_searchに新しい構成ファイルを追加することにより、HyperParameter検索を定義できます。
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256)次に、 python train.py -m hparams_search=mnist_optunaで実行します
このアプローチを使用すると、ボイラープレートをコードに追加する必要はありません。すべてが単一の構成ファイルで定義されます。必要な唯一のことは、起動ファイルから最適化されたメートル値を返すことです。
Optuna、AX、Nevergradなど、Hydraと統合されたさまざまな最適化フレームワークを使用できます。
optimization_results.yamlは、 logs/task_name/multirunフォルダーで利用可能になります。
このアプローチは、中断された検索とプランニングのような高度なテクニックの再開をサポートしていません。より洗練された検索とワークフローのために、おそらく専用の最適化タスクを作成する必要があります(マルチラン機能なし)。
テンプレートには、GitHubアクションに実装されたCIワークフローが付属しています。
.github/workflows/test.yaml :pytestですべてのテストを実行します.github/workflows/code-quality-main.yaml :すべてのファイルのメインブランチで事前委員会を実行する.github/workflows/code-quality-pr.yaml :変更されたファイルのみのプルリクエストで事前コミットを実行するLightningは、分散トレーニングを行う複数の方法をサポートしています。最も一般的なものはDDPです。これは、各GPUの個別のプロセスを生成し、それらの間で平均勾配を発生させます。他のアプローチについて学ぶために、Lightning Docsを読んでください。
このような4つのGPUでMnistの例でDDPを実行できます。
python train.py trainer=ddp注:DDPを使用する場合は、モデルの書き込み方法に注意する必要があります。ドキュメントをお読みください。
最も簡単な方法は、DataModule属性を初期化時にモデルに直接渡すことです。
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )注:すべてのデータモジュールが
some_param属性を利用できると想定しているため、非常に堅牢なソリューションではありません。
同様に、initパラメーターとしてデータモジュール構成全体を渡すことができます。
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )DataModule Configパラメーターを可変補間を介してモデルに渡すこともできます。
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}別のアプローチは、トレーナーを介してLightningModuleのDataModuleに直接アクセスすることです。
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_param注:これは、トレーナーがLightningModuleでまだ利用できないため、トレーニングが開始された後にのみ機能します。
通常、完全なアナコンダ環境をインストールする必要はありません。ミニコンダは十分である必要があります(80MB前後の重量)。
Condaの大きな利点は、特定のコンパイラやライブラリをシステムで利用できるようにすることなくパッケージをインストールできることです(Precompiled Binariesをインストールするため)。したがって、GPUサポート用のCudatoolkitなどの依存関係を簡単にインストールすることができます。
また、すべてのプロジェクトに新しいローカル環境を作成するよりも便利かもしれないグローバルな環境にアクセスすることもできます。
インストールの例:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shCondaを更新:
conda update -n base -c defaults conda新しいコンドラ環境を作成します:
conda create -n myenv python=3.10
conda activate myenv事前コミットフックを使用して、プロジェクトのコードフォーマットを標準化し、精神的エネルギーを節約します。
以下の事前コミットパッケージをインストールするだけです。
pip install pre-commit次に、.pre-commit-config.yamlからフックをインストールします:
pre-commit installその後、コードはすべての新しいコミットごとに自動的に再フォーマットされます。
プロジェクト内のすべてのファイルをフォーマットするには、コマンドを使用します。
pre-commit run -a.pre-commit-config.yamlの使用でフックバージョンを更新するには:
pre-commit autoupdateシステム固有の変数(たとえば、データセットへの絶対パス)がバージョン制御下にあるべきではないか、異なるユーザー間で競合します。あなたのプライベートキーも、漏れを望まないので、バージョンにされるべきではありません。
テンプレートには、例として機能する.env.exampleファイルが含まれます。 .envという新しいファイルを作成します(この名前は.gitignoreのバージョンコントロールから除外されます)。このような環境変数を保存するために使用する必要があります。
MY_VAR=/home/user/my_system_path
.envからのすべての変数は、 train.pyに自動的にロードされます。
Hydraを使用すると、このような.yaml構成でev env変数を参照できます。
path_to_data : ${oc.env:MY_VAR}使用しているロガーに応じて、メトリック名を/文字で定義することはしばしば役立ちます。
self . log ( "train/loss" , loss )このようにして、ロガーはメトリックをさまざまなセクションに属するものとして扱い、UIで整理するのに役立ちます。
公式のTorchmetricsライブラリを使用して、メトリックの適切な計算を確認します。これは、マルチGPUトレーニングにとって特に重要です!
たとえば、自分で精度を計算する代わりに、次のような提供されたAccuracyクラスを使用する必要があります。
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...すべてのGPUプロセスにわたって適切な価値削減を確保するために、各ステップに異なるメトリックインスタンスを使用してください。
Torchmetricsは、F1スコアや混乱マトリックスなど、ほとんどのユースケースにメトリックを提供します。詳細については、ドキュメントを読んでください。
スタイルガイドはこちらから入手できます。
あなたのイニシを明示してください。ユーザーが推測する必要がないように、関連するすべてのデフォルトを定義してみてください。タイプのヒントを提供します。このようにして、モジュールはプロジェクト間で再利用可能です!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):推奨されるメソッド順序を保持します。
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
...DVCを使用して、データやトレーニングされたMLモデルなど、大きなファイルを制御します。
DVCリポジトリを初期化するには:
dvc initファイルまたはディレクトリの追跡を開始するには、 dvc add使用します。
dvc add data/MNISTDVCは、追加されたファイル(またはディレクトリ)に関する情報を、人間が読みやすい形式を持つ小さなテキストファイルという名前の特別な.DVCファイルにあるDATA/MNIST.DVCに保存します。このファイルは、元のデータのプレースホルダーとして、GITを使用したソースコードのように簡単にバージョンすることができます。
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data "これにより、他の人は自分のプロジェクトでモジュールを簡単に使用できます。 srcフォルダーの名前をプロジェクト名に変更し、 setup.pyファイルに記入します。
これで、プロジェクトはローカルファイルからインストールできます。
pip install -e .またはgitリポジトリから直接:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradeしたがって、任意のファイルは、次のような他のファイルに簡単にインポートできます。
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModule一部の構成は、ユーザー/マシン/インストール固有のものです(たとえば、ローカルクラスターの構成、または特定のマシンのハードドライブパス)。このようなシナリオでは、ファイル構成/local/default.yamlを作成できます。これは自動的に読み込まれますが、GITで追跡されません。
たとえば、SluRMクラスター構成に使用できます。
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd このテンプレートは次のように触発されました。
その他の便利なリポジトリ:
Lightning-Hydra-Templateは、MITライセンスに基づいてライセンスされています。
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
プロジェクトのために上記のすべてを削除します
それがすること
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvデフォルトの構成を備えたトレーニングモデル
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpu構成/実験から選択した実験構成を備えた列車モデル/
python src/train.py experiment=experiment_name.yamlこのようなコマンドラインからのパラメーターをオーバーライドできます
python src/train.py trainer.max_epochs=20 data.batch_size=64

