lightning hydra template
v2.0.3
Template yang bersih untuk memulai proyek pembelajaran mendalam Anda ⚡
Klik Gunakan templat ini untuk menginisialisasi repositori baru.
Saran selalu diterima!
Mengapa Anda mungkin ingin menggunakannya:
✅ Simpan di boilerplate
Mudah menambahkan model baru, kumpulan data, tugas, eksperimen, dan melatih akselerator yang berbeda, seperti kelompok multi-GPU, TPU atau Slurm.
✅ Pendidikan
Berkomentar dengan seksama. Anda dapat menggunakan repo ini sebagai sumber belajar.
✅ Reusability
Pengumpulan alat MLOP yang berguna, konfigurasi, dan cuplikan kode. Anda dapat menggunakan repo ini sebagai referensi untuk berbagai utilitas.
Mengapa Anda mungkin tidak ingin menggunakannya:
Hal -hal rusak dari waktu ke waktu
Petir dan Hydra masih berkembang dan mengintegrasikan banyak perpustakaan, yang berarti kadang -kadang rusak. Untuk daftar masalah yang saat ini diketahui, kunjungi halaman ini.
Tidak disesuaikan untuk rekayasa data
Template tidak benar -benar disesuaikan untuk membangun pipa data yang saling bergantung. Lebih efisien untuk menggunakannya untuk prototipe model pada data siap pakai.
Overfitted ke case penggunaan sederhana
Pengaturan konfigurasi dibangun dengan pelatihan petir sederhana dalam pikiran. Anda mungkin perlu berupaya menyesuaikannya untuk kasus penggunaan yang berbeda, misalnya kain petir.
Mungkin tidak mendukung alur kerja Anda
Misalnya, Anda tidak dapat melanjutkan pencarian multirun atau hiperparameter berbasis Hydra.
Catatan : Ingatlah ini adalah proyek komunitas tidak resmi.
Pytorch Lightning - Pembungkus Pytorch yang ringan untuk penelitian AI berkinerja tinggi. Anggap saja sebagai kerangka kerja untuk mengatur kode Pytorch Anda.
Hydra - Kerangka kerja untuk mengonfigurasi aplikasi yang kompleks secara elegan. Fitur utama adalah kemampuan untuk secara dinamis membuat konfigurasi hierarkis dengan komposisi dan mengesampingkannya melalui file konfigurasi dan baris perintah.
Struktur direktori proyek baru terlihat seperti ini:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt Template berisi contoh dengan klasifikasi MNIST.
Saat menjalankan python src/train.py Anda harus melihat sesuatu seperti ini:
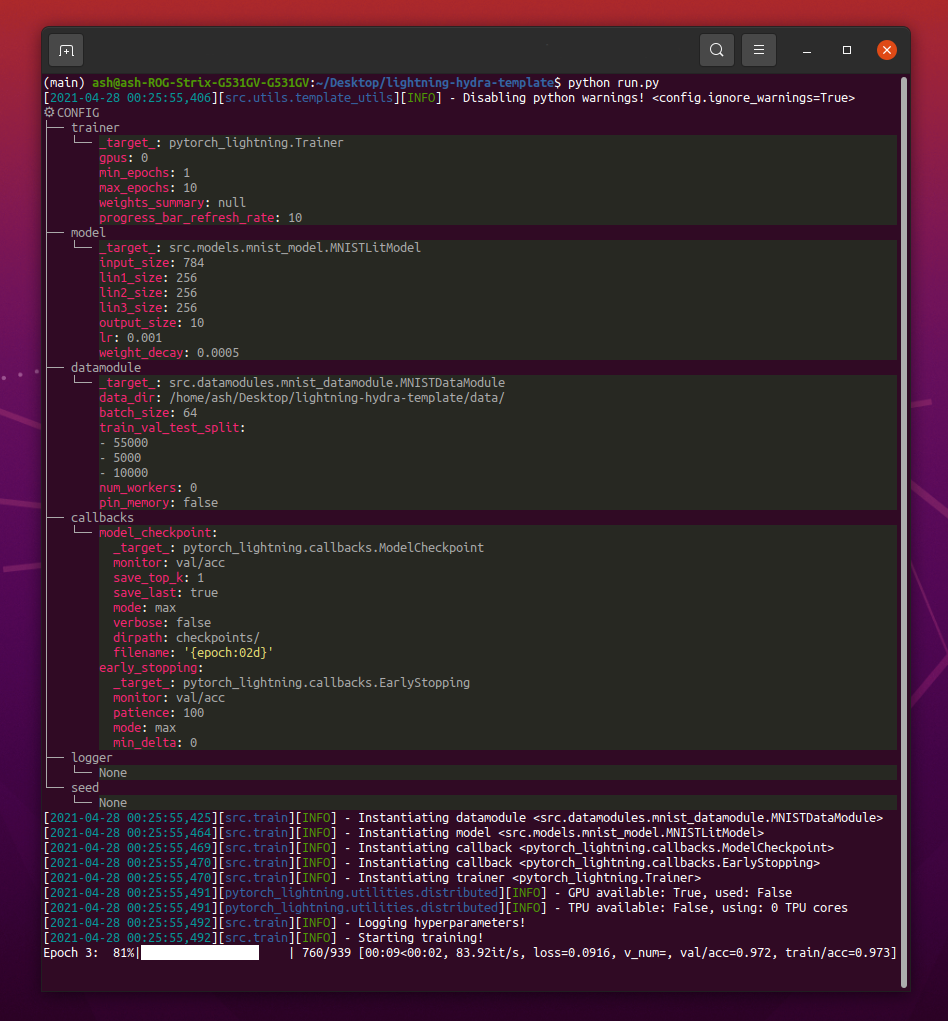
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4Catatan : Anda juga dapat menambahkan parameter baru dengan tanda
+.
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mpsPeringatan : Saat ini ada masalah dengan mode DDP, baca masalah ini untuk mempelajari lebih lanjut.
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandbCatatan : Lightning menyediakan integrasi yang nyaman dengan kerangka kerja logging paling populer. Pelajari lebih lanjut di sini.
Catatan : Menggunakan Wandb mengharuskan Anda untuk mengatur akun terlebih dahulu. Setelah itu, lengkapi konfigurasi seperti di bawah ini.
Catatan : Klik di sini untuk melihat contoh dasbor wandb yang dihasilkan dengan template ini.
python train.py experiment=exampleCatatan : Konfigurasi Eksperimen ditempatkan di Configs/Experiment/.
python train.py callbacks=defaultCatatan : Callbacks dapat digunakan untuk hal -hal seperti sebagai pos pemeriksaan model, penghentian awal dan banyak lagi.
Catatan : Callbacks Config ditempatkan di konfigurasi/callbacks/.
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"Catatan : Pytorch Lightning menyediakan sekitar 40+ bendera pelatih yang berguna.
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2Catatan : Kunjungi Configs/ Debug/ untuk berbagai konfigurasi debugging.
python train.py ckpt_path="/path/to/ckpt/name.ckpt"Catatan : Pos Pemeriksaan dapat berupa jalur atau URL.
Catatan : Saat ini memuat CKPT tidak melanjutkan eksperimen logger, tetapi akan didukung dalam rilis Lightning di masa depan.
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"Catatan : Pos Pemeriksaan dapat berupa jalur atau URL.
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005Catatan : Hydra menyusun konfigurasi dengan malas pada waktu peluncuran kerja. Jika Anda mengubah kode atau konfigurasi setelah meluncurkan pekerjaan/sapuan, konfigurasi akhir yang disusun mungkin terpengaruh.
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=exampleCatatan : Menggunakan Optuna Sweeper tidak mengharuskan Anda menambahkan boilerplate ke kode Anda, semuanya ditentukan dalam satu file konfigurasi.
PERINGATAN : Optuna Sweeps tidak tahan kegagalan (jika satu pekerjaan jatuh maka seluruh sapuan crash).
python train.py -m ' experiment=glob(*) 'Catatan : Hydra menyediakan sintaks khusus untuk mengendalikan perilaku multirun. Pelajari lebih lanjut di sini. Perintah di atas menjalankan semua percobaan dari configs/experiment/.
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]Catatan :
trainer.deterministic=Truemembuat pytorch lebih deterministik tetapi berdampak pada kinerja.
Catatan : Ini harus dicapai dengan konfigurasi sederhana menggunakan peluncur Ray AWS untuk Hydra. Contohnya tidak diimplementasikan dalam templat ini.
Catatan : Hydra memungkinkan Anda untuk mengarahkan argumen konfigurasi secara otomatis di Shell saat Anda menulisnya, dengan menekan tombol
tab. Baca dokumen.
pre-commit run -aCatatan : Terapkan kait pra-komit untuk melakukan hal-hal seperti kode dan konfigurasi format otomatis, melakukan analisis kode atau menghapus output dari jupyter notebooks. Lihat # Praktik Terbaik Untuk Lebih Banyak.
Perbarui versi kait pra-komit di .pre-commit-config.yaml dengan:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Setiap percobaan harus ditandai untuk memfilternya dengan mudah di seluruh file atau di Logger UI:
python train.py tags=[ " mnist " , " experiment_X " ]Catatan : Anda mungkin perlu melarikan diri dari karakter braket di shell Anda dengan
python train.py tags=["mnist","experiment_X"].
Jika tidak ada tag yang disediakan, Anda akan diminta untuk memasukkannya dari baris perintah:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):Jika tidak ada tag disediakan untuk multirun, kesalahan akan dinaikkan:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !CATATAN : Daftar penambahan dari baris perintah saat ini tidak didukung di Hydra :(
Proyek ini ada berkat semua orang yang berkontribusi.
Punya pertanyaan? Menemukan bug? Kehilangan fitur tertentu? Jangan ragu untuk mengajukan masalah baru, diskusi, atau PR dengan judul dan deskripsi masing -masing.
Sebelum membuat masalah, harap verifikasi itu:
main saat ini.Saran untuk perbaikan selalu diterima!
Semua modul petir pytorch secara dinamis dipakai dari jalur modul yang ditentukan dalam config. Contoh Model Config:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10Menggunakan konfigurasi ini kita dapat membuat instansi objek dengan baris berikut:
model = hydra . utils . instantiate ( config . model ) Ini memungkinkan Anda untuk dengan mudah mengulangi model baru! Setiap kali Anda membuat yang baru, tentukan saja jalur modul dan parameternya dalam file konfigurasi yang sesuai.
Beralih antara model dan datamodul dengan argumen baris perintah:
python train.py model=mnistContoh Pipa Mengelola Logika Instantiasi: SRC/Train.py.
Lokasi: configs/train.yaml
Konfigurasi proyek utama berisi konfigurasi pelatihan default.
Ini menentukan bagaimana konfigurasi disusun saat hanya mengeksekusi perintah python train.py .
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null Lokasi: Konfigurasi/Eksperimen
Konfigurasi Eksperimen memungkinkan Anda untuk menimpa parameter dari konfigurasi utama.
Misalnya, Anda dapat menggunakannya untuk mengontrol versi hyperparameters terbaik untuk setiap kombinasi model dan dataset.
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " Alur kerja dasar
python src/train.py experiment=experiment_name.yamlDesain Eksperimen
Katakanlah Anda ingin menjalankan banyak lari untuk memplot bagaimana perubahan akurasi sehubungan dengan ukuran batch.
Jalankan menjalankan dengan beberapa parameter konfigurasi yang memungkinkan Anda untuk mengidentifikasinya dengan mudah, seperti tag:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] Tulis skrip atau notebook yang mencari di atas logs/ folder dan mengambil log CSV dari menjalankan yang berisi tag yang diberikan dalam config. Plot hasilnya.
Hydra membuat direktori output baru untuk setiap menjalankan yang dieksekusi.
Struktur logging default:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
Anda dapat mengubah struktur ini dengan memodifikasi jalur dalam konfigurasi Hydra.
Pytorch Lightning mendukung banyak kerangka kerja logging populer: Bobot & Bias, Neptunus, Komet, MLFLOW, Tensorboard.
Alat -alat ini membantu Anda melacak hiperparameter dan metrik output dan memungkinkan Anda untuk membandingkan dan memvisualisasikan hasil. Untuk menggunakan salah satunya, cukup selesaikan konfigurasinya di Configs/Logger dan jalankan:
python train.py logger=logger_nameAnda dapat menggunakan banyak dari mereka sekaligus (lihat Configs/Logger/Many_loggers.yaml misalnya).
Anda juga dapat menulis logger Anda sendiri.
Lightning menyediakan metode yang nyaman untuk mencatat metrik khusus dari dalam LightningModule. Baca dokumen atau lihat contoh MNIST.
Template hadir dengan tes generik yang diimplementasikan dengan pytest .
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Sebagian besar tes yang diimplementasikan tidak memeriksa output spesifik apa pun - mereka ada untuk memverifikasi bahwa menjalankan beberapa perintah tidak berakhir dengan melempar pengecualian. Anda dapat menjalankannya sesekali untuk mempercepat pengembangan.
Saat ini, tes mencakup kasus seperti:
Dan banyak lainnya. Anda harus dapat memodifikasinya dengan mudah untuk kasus penggunaan Anda.
Ada juga @RunIf Decorator yang diimplementasikan, yang memungkinkan Anda menjalankan tes hanya jika kondisi tertentu terpenuhi, misalnya GPU tersedia atau sistem bukan Windows. Lihat contohnya.
Anda dapat mendefinisikan pencarian hyperparameter dengan menambahkan file konfigurasi baru ke configs/hparams_search.
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256) Selanjutnya, jalankan dengan: python train.py -m hparams_search=mnist_optuna
Menggunakan pendekatan ini tidak memerlukan menambahkan boilerplate ke kode, semuanya ditentukan dalam satu file konfigurasi. Satu -satunya hal yang diperlukan adalah mengembalikan nilai metrik yang dioptimalkan dari file peluncuran.
Anda dapat menggunakan kerangka kerja optimasi yang berbeda yang terintegrasi dengan Hydra, seperti Optuna, AX atau NeverGrad.
optimization_results.yaml akan tersedia di bawah logs/task_name/multirun .
Pendekatan ini tidak mendukung melanjutkan pencarian yang terputus dan teknik canggih seperti pisau - untuk pencarian dan alur kerja yang lebih canggih, Anda mungkin harus menulis tugas optimasi khusus (tanpa fitur multirun).
Template dilengkapi dengan alur kerja CI yang diimplementasikan dalam tindakan GitHub:
.github/workflows/test.yaml : Menjalankan semua tes dengan pytest.github/workflows/code-quality-main.yaml : Menjalankan pra-komit di cabang utama untuk semua file.github/workflows/code-quality-pr.yaml : Menjalankan pra-komit pada permintaan menarik hanya untuk file yang dimodifikasi Petir mendukung berbagai cara melakukan pelatihan terdistribusi. Yang paling umum adalah DDP, yang memunculkan proses terpisah untuk setiap GPU dan rata -rata gradien di antara mereka. Untuk mempelajari tentang pendekatan lain, baca dokumen Lightning.
Anda dapat menjalankan DDP pada contoh MNIST dengan 4 GPU seperti ini:
python train.py trainer=ddpCatatan : Saat menggunakan DDP Anda harus berhati -hati bagaimana Anda menulis model Anda - baca dokumen.
Cara paling sederhana adalah dengan meneruskan atribut datamodule langsung ke model inisialisasi:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )Catatan : Bukan solusi yang sangat kuat, karena mengasumsikan semua datamodul Anda memiliki atribut
some_paramyang tersedia.
Demikian pula, Anda dapat melewati seluruh konfigurasi datamodule sebagai parameter init:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )Anda juga dapat melewati parameter konfigurasi datamodule ke model Anda melalui interpolasi variabel:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}Pendekatan lain adalah mengakses datamodule di LightningModule langsung melalui pelatih:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_paramCatatan : Ini hanya berfungsi setelah pelatihan dimulai karena jika tidak, pelatih belum tersedia di LightningModule.
Biasanya tidak perlu memasang lingkungan Anaconda penuh, miniconda seharusnya cukup (bobot sekitar 80MB).
Keuntungan besar dari Conda adalah memungkinkan untuk memasang paket tanpa memerlukan kompiler atau pustaka tertentu untuk tersedia dalam sistem (karena menginstal biner yang dikompilasi), sehingga sering membuatnya lebih mudah untuk menginstal beberapa dependensi misalnya Cudatoolkit untuk dukungan GPU.
Ini juga memungkinkan Anda untuk mengakses lingkungan Anda secara global yang mungkin lebih nyaman daripada menciptakan lingkungan lokal baru untuk setiap proyek.
Contoh instalasi:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shPerbarui conda:
conda update -n base -c defaults condaBuat Lingkungan Conda Baru:
conda create -n myenv python=3.10
conda activate myenv Gunakan kait pra-komit untuk menstandarkan pemformatan kode proyek Anda dan hemat energi mental.
Cukup instal paket pra-komit dengan:
pip install pre-commitSelanjutnya, instal kait dari .pre-commit-config.yaml:
pre-commit installSetelah itu kode Anda akan secara otomatis diformat ulang pada setiap komit baru.
Untuk memformat ulang semua file dalam perintah penggunaan proyek:
pre-commit run -aUntuk memperbarui versi kait di .pre-commit-config.yaml menggunakan:
pre-commit autoupdate Variabel spesifik sistem (misalnya jalur absolut ke set data) tidak boleh berada di bawah kontrol versi atau akan mengakibatkan konflik antara pengguna yang berbeda. Kunci pribadi Anda juga tidak boleh diversi karena Anda tidak ingin mereka bocor.
Template berisi file .env.example , yang berfungsi sebagai contoh. Buat file baru yang disebut .env (nama ini dikecualikan dari kontrol versi di .gitignore). Anda harus menggunakannya untuk menyimpan variabel lingkungan seperti ini:
MY_VAR=/home/user/my_system_path
Semua variabel dari .env dimuat dalam train.py secara otomatis.
Hydra memungkinkan Anda merujuk variabel apa pun di .yaml configs seperti ini:
path_to_data : ${oc.env:MY_VAR} Bergantung pada logger mana yang Anda gunakan, seringkali berguna untuk mendefinisikan nama metrik dengan / karakter:
self . log ( "train/loss" , loss )Dengan cara ini, penebang akan memperlakukan metrik Anda sebagai bagian dari bagian yang berbeda, yang membantu agar mereka terorganisir dalam UI.
Gunakan pustaka Torchmetrics resmi untuk memastikan perhitungan metrik yang tepat. Ini sangat penting untuk pelatihan multi-GPU!
Misalnya, alih -alih menghitung akurasi sendiri, Anda harus menggunakan kelas Accuracy yang disediakan seperti ini:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...Pastikan untuk menggunakan contoh metrik yang berbeda untuk setiap langkah untuk memastikan pengurangan nilai yang tepat atas semua proses GPU.
Torchmetrics menyediakan metrik untuk sebagian besar kasus penggunaan, seperti skor F1 atau matriks kebingungan. Baca dokumentasi untuk lebih lanjut.
Panduan gaya tersedia di sini.
Jadilah eksplisit di init Anda. Cobalah untuk mendefinisikan semua default yang relevan sehingga pengguna tidak harus menebak. Berikan petunjuk jenis. Dengan cara ini modul Anda dapat digunakan kembali di seluruh proyek!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):Lestarikan urutan metode yang disarankan.
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
... Gunakan DVC untuk mengontrol versi file besar, seperti data Anda atau model ML terlatih.
Untuk menginisialisasi repositori DVC:
dvc init Untuk mulai melacak file atau direktori, gunakan dvc add :
dvc add data/MNISTDVC menyimpan informasi tentang file yang ditambahkan (atau direktori) dalam file .dvc khusus bernama data/mnist.dvc, file teks kecil dengan format yang dapat dibaca manusia. File ini dapat dengan mudah diversi seperti kode sumber dengan git, sebagai placeholder untuk data asli:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data " Ini memungkinkan orang lain untuk dengan mudah menggunakan modul Anda dalam proyek mereka sendiri. Ubah nama folder src ke nama proyek Anda dan lengkapi file setup.py .
Sekarang proyek Anda dapat diinstal dari file lokal:
pip install -e .Atau langsung dari git repositori:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradeJadi file apa pun dapat dengan mudah diimpor ke file lain seperti itu:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModuleBeberapa konfigurasi spesifik pengguna/mesin/pemasangan (misalnya konfigurasi cluster lokal, atau jalur harddrive pada mesin tertentu). Untuk skenario seperti itu, file configs/local/default.yaml dapat dibuat yang secara otomatis dimuat tetapi tidak dilacak oleh git.
Misalnya, Anda dapat menggunakannya untuk konfigurasi kluster slurm:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd Template ini terinspirasi oleh:
Repositori yang bermanfaat lainnya:
Lightning-hydra-template dilisensikan di bawah lisensi MIT.
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Hapus semuanya di atas untuk proyek Anda
Apa yang dilakukannya
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvModel kereta dengan konfigurasi default
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpuModel kereta dengan konfigurasi eksperimen yang dipilih dari configs/eksperimen/
python src/train.py experiment=experiment_name.yamlAnda dapat mengganti parameter apa pun dari baris perintah seperti ini
python src/train.py trainer.max_epochs=20 data.batch_size=64

