lightning hydra template
v2.0.3
Una plantilla limpia para iniciar su proyecto de aprendizaje profundo ⚡
Haga clic en Usar esta plantilla para inicializar un nuevo repositorio.
¡Las sugerencias siempre son bienvenidas!
Por qué es posible que desee usarlo:
✅ Guardar en Boilerplate
Agregue fácilmente nuevos modelos, conjuntos de datos, tareas, experimentos y entrena en diferentes aceleradores, como clústeres de múltiples GPU, TPU o SLURM.
✅ Educación
Comentó completamente. Puede usar este repositorio como recurso de aprendizaje.
✅ Reutilización
Colección de herramientas, configuraciones y fragmentos de código útiles útiles. Puede usar este repositorio como referencia para varias utilidades.
Por qué es posible que no quieras usarlo:
Las cosas se rompen de vez en cuando
Lightning e Hydra siguen evolucionando e integran muchas bibliotecas, lo que significa que a veces las cosas se rompen. Para la lista de problemas conocidos actualmente, visite esta página.
No ajustado para la ingeniería de datos
La plantilla no se ajusta realmente para construir tuberías de datos que dependen entre sí. Es más eficiente usarlo para la creación de prototipos de modelos en datos listos para usar.
Caso de uso simple en exceso
La configuración de configuración está construida con una simple capacitación en rayos en mente. Es posible que deba poner un esfuerzo para ajustarlo para diferentes casos de uso, por ejemplo, tela de rayo.
Es posible que no apoye su flujo de trabajo
Por ejemplo, no puede reanudar la búsqueda multirunun o hiperparameter basada en Hydra.
Nota : Tenga en cuenta que este es un proyecto comunitario no oficial.
Pytorch Lightning: un envoltorio de pytorch liviano para la investigación de IA de alto rendimiento. Piense en ello como un marco para organizar su código Pytorch.
Hydra: un marco para configurar elegantemente aplicaciones complejas. La característica clave es la capacidad de crear dinámicamente una configuración jerárquica por composición y anularla a través de archivos de configuración y la línea de comando.
La estructura del directorio del nuevo proyecto se ve así:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt La plantilla contiene un ejemplo con clasificación MNIST.
Al ejecutar python src/train.py debería ver algo como esto:
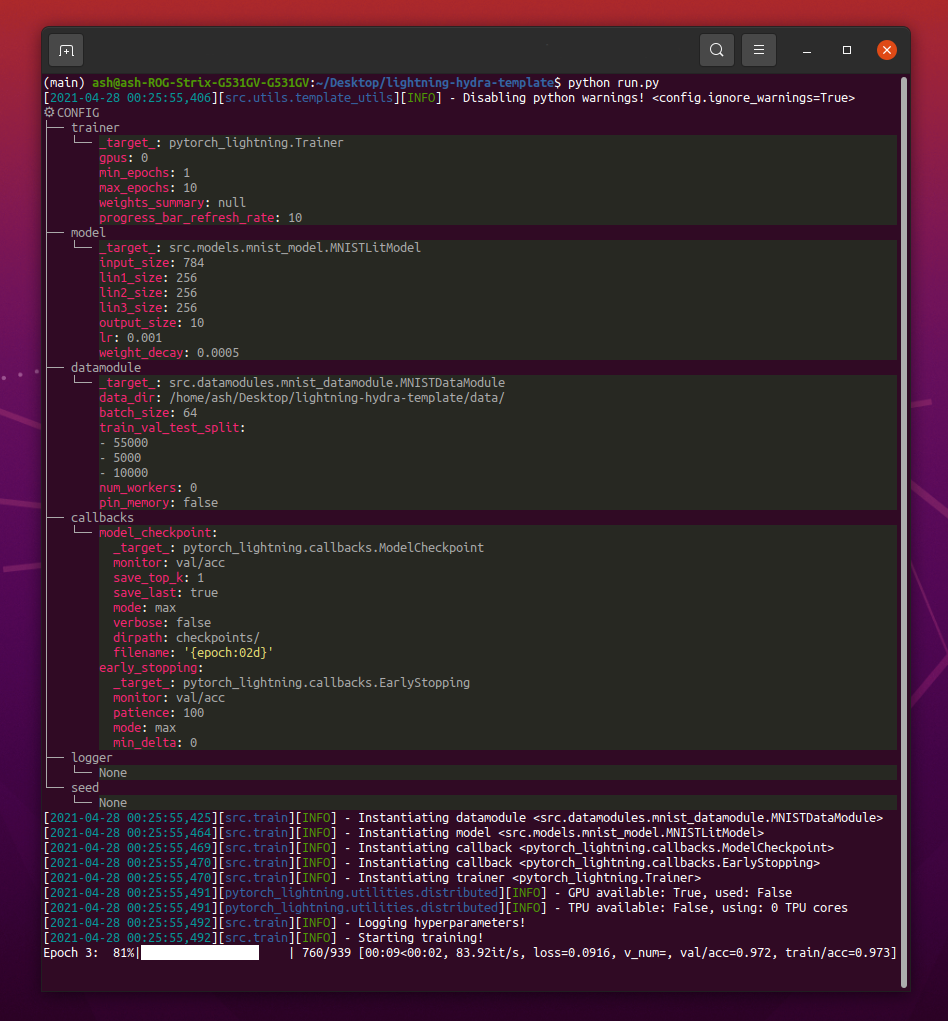
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4Nota : También puede agregar nuevos parámetros con
+signo.
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mpsADVERTENCIA : Actualmente hay problemas con el modo DDP, lea este problema para obtener más información.
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandbNota : Lightning proporciona integraciones convenientes con los marcos de registro más populares. Obtenga más información aquí.
Nota : El uso de WandB requiere que configure primero la cuenta. Después de eso, simplemente complete la configuración como se muestra a continuación.
Nota : Haga clic aquí para ver el tablero Wandb de ejemplo generado con esta plantilla.
python train.py experiment=exampleNota : Las configuraciones del experimento se colocan en Configs/Experiment/.
python train.py callbacks=defaultNota : Las devoluciones de llamada se pueden usar para cosas como el punto de control de modelo, la parada temprana y muchos más.
Nota : Las configuraciones de devolución de llamada se colocan en configuraciones/devoluciones de llamada/.
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"NOTA : Pytorch Lightning proporciona más de 40 banderas de entrenadores útiles.
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2Nota : Visite Configs/ Depug/ para diferentes configuraciones de depuración.
python train.py ckpt_path="/path/to/ckpt/name.ckpt"Nota : El punto de control puede ser ruta o URL.
Nota : Actualmente, cargar CKPT no reanuda el experimento del registrador, pero será compatible con el lanzamiento de Lightning futuro.
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"Nota : El punto de control puede ser ruta o URL.
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005Nota : Hydra compone las configuraciones perezosamente en el tiempo de lanzamiento del trabajo. Si cambia de código o configuraciones después de iniciar un trabajo/barrido, las configuraciones compuestas finales podrían verse afectadas.
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=exampleNota : El uso de Optuna Sweper no requiere que agregue ninguna caldera a su código, todo se define en un solo archivo de configuración.
ADVERTENCIA : Los barridos de optuna no son resistentes a la falla (si un trabajo se bloquea, todo el barrido se bloquea).
python train.py -m ' experiment=glob(*) 'Nota : Hydra proporciona una sintaxis especial para controlar el comportamiento de MultIRuns. Obtenga más información aquí. El comando anterior ejecuta todos los experimentos desde Configs/Experiment/.
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]Nota :
trainer.deterministic=Truehace que Pytorch sea más determinista pero afecta el rendimiento.
Nota : Esto debe lograrse con una configuración simple utilizando Ray AWS Launcher para HYDRA. El ejemplo no se implementa en esta plantilla.
Nota : Hydra le permite anular el argumento de configuración de configuración en el shell mientras los escribe, presionando la tecla
tab. Lea los documentos.
pre-commit run -aNota : Aplique ganchos previos al compromiso para hacer cosas como código de formato automático y configuraciones, realizar análisis de código o eliminar la salida de los cuadernos Jupyter. Ver # Las mejores prácticas para más.
Actualizar versiones de gancho previa al Commit en .pre-commit-config.yaml con:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Cada experimento debe etiquetarse para filtrarlos fácilmente a través de archivos o en la interfaz de usuario de Logger:
python train.py tags=[ " mnist " , " experiment_X " ]Nota : Es posible que deba escapar de los caracteres del soporte en su shell con
python train.py tags=["mnist","experiment_X"].
Si no se proporcionan etiquetas, se le pedirá que las ingrese desde la línea de comando:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):Si no se proporcionan etiquetas para multirun, se planteará un error:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !Nota : Actualmente no es compatible con Hydra :(
Este proyecto existe gracias a todas las personas que contribuyen.
¿Tienes una pregunta? Encontrado un error? ¿Se pierde una característica específica? Siéntase libre de presentar un nuevo tema, discusión o relaciones públicas con el título y la descripción respectivos.
Antes de hacer un problema, verifique eso:
main actual.¡Las sugerencias de mejoras son siempre bienvenidas!
Todos los módulos de rayos de Pytorch están instanciados dinámicamente desde las rutas de módulos especificadas en la configuración. Ejemplo de configuración del modelo:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10Usando esta configuración podemos instanciar el objeto con la siguiente línea:
model = hydra . utils . instantiate ( config . model ) ¡Esto le permite iterar fácilmente sobre nuevos modelos! Cada vez que crea uno nuevo, simplemente especifique su ruta de módulo y parámetros en el archivo de configuración apropiado.
Cambiar entre modelos y datamodules con argumentos de línea de comandos:
python train.py model=mnistEjemplo de tubería Administración de la lógica de instanciación: src/trenes.py.
Ubicación: configuraciones/trenes.yaml
La configuración del proyecto principal contiene una configuración de capacitación predeterminada.
Determina cómo se compone la configuración al simplemente ejecutar comando python train.py
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null Ubicación: configuraciones/experimento
Las configuraciones de experimentos le permiten sobrescribir los parámetros de la configuración principal.
Por ejemplo, puede usarlos para controlar las mejores hiperparámetros para cada combinación de modelo y conjunto de datos.
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " Flujo de trabajo básico
python src/train.py experiment=experiment_name.yamlDiseño de experimentos
Digamos que desea ejecutar muchas ejecuciones para trazar cómo cambia la precisión con respecto al tamaño del lote.
Ejecute las ejecuciones con algún parámetro de configuración que le permite identificarlos fácilmente, como las etiquetas:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] Escriba un script o un cuaderno que busque en los logs/ carpeta y recupera registros de CSV de las ejecuciones que contienen etiquetas dadas en la configuración. Traza los resultados.
Hydra crea un nuevo directorio de salida para cada ejecución ejecutada.
Estructura de registro predeterminada:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
Puede cambiar esta estructura modificando rutas en la configuración de Hydra.
Pytorch Lightning admite muchos marcos de registro populares: pesas y sesgos, Neptuno, cometa, mlflow, tensorboard.
Estas herramientas lo ayudan a realizar un seguimiento de los hiperparámetros y las métricas de salida y le permiten comparar y visualizar los resultados. Para usar uno de ellos, simplemente complete su configuración en Configs/Logger y ejecute:
python train.py logger=logger_namePuede usar muchos de ellos a la vez (consulte Configs/Logger/Many_loggers.yaml, por ejemplo).
También puede escribir su propio registrador.
Lightning proporciona un método conveniente para registrar métricas personalizadas desde el interior de LightningModule. Lea los documentos o eche un vistazo al ejemplo de mnist.
La plantilla viene con pruebas genéricas implementadas con pytest .
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "La mayoría de las pruebas implementadas no verifican ningún resultado específico: existen simplemente para verificar que la ejecución de algunos comandos no termine en lanzar excepciones. Puede ejecutarlos de vez en cuando para acelerar el desarrollo.
Actualmente, las pruebas cubren casos como:
Y muchos otros. Debería poder modificarlos fácilmente para su caso de uso.
También hay @RunIf Decorator implementado, que le permite ejecutar pruebas solo si se cumplen ciertas condiciones, por ejemplo, GPU está disponible o el sistema no es Windows. Ver los ejemplos.
Puede definir la búsqueda de hiperparameter agregando un nuevo archivo de configuración a config/hparams_search.
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256) Siguiente, ejecutarlo con: python train.py -m hparams_search=mnist_optuna
Usar este enfoque no requiere agregar ninguna placa a código, todo se define en un solo archivo de configuración. Lo único necesario es devolver el valor métrico optimizado del archivo de lanzamiento.
Puede usar diferentes marcos de optimización integrados con Hydra, como Optuna, Ax o Nevergrad.
La optimization_results.yaml estará disponible en la carpeta logs/task_name/multirun .
Este enfoque no es compatible con la reanudación de la búsqueda interrumpida y las técnicas avanzadas como PRUNNING, para obtener flujos de búsqueda y búsqueda más sofisticados, probablemente debería escribir una tarea de optimización dedicada (sin la función multirun).
La plantilla viene con flujos de trabajo de CI implementados en acciones de GitHub:
.github/workflows/test.yaml : ejecutando todas las pruebas con pytest.github/workflows/code-quality-main.yaml : Ejecución de pre-Commits en la rama principal para todos los archivos.github/workflows/code-quality-pr.yaml : ejecutar las solicitudes de extracción de los archivos modificados solamente Lightning admite múltiples formas de hacer capacitación distribuida. El más común es DDP, que genera un proceso separado para cada GPU y promedia los gradientes entre ellos. Para aprender sobre otros enfoques, lea los Docios Lightning.
Puede ejecutar DDP en MNIST Ejemplo con 4 GPU como este:
python train.py trainer=ddpNota : Cuando usa DDP, debe tener cuidado de cómo escribe sus modelos: lea los documentos.
La forma más sencilla es pasar el atributo DataModule directamente al modelado en la inicialización:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )Nota : No es una solución muy robusta, ya que asume que todos sus Datamodules tienen un atributo
some_paramdisponible.
Del mismo modo, puede pasar una configuración de DataModule completa como un parámetro Init:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )También puede pasar un parámetro de configuración de DataModule a su modelo a través de la interpolación variable:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}Otro enfoque es acceder a DataModule en LightningModule directamente a través del entrenador:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_paramNota : Esto solo funciona después de que comience la capacitación, ya que de lo contrario el entrenador aún no estará disponible en LightningModule.
Por lo general, es innecesario instalar un entorno de Anaconda completo, Miniconda debería ser suficiente (pesas de alrededor de 80 MB).
La gran ventaja de Conda es que permite instalar paquetes sin requerir que ciertos compiladores o bibliotecas estén disponibles en el sistema (ya que instala binarios precompilados), por lo que a menudo facilita la instalación de algunas dependencias, por ejemplo, CUDatoolkit para soporte de GPU.
También le permite acceder a sus entornos a nivel mundial, lo que puede ser más conveniente que crear un nuevo entorno local para cada proyecto.
Instalación de ejemplo:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shActualización de condena:
conda update -n base -c defaults condaCrea un nuevo entorno de condena:
conda create -n myenv python=3.10
conda activate myenv Use ganchos previos al compromiso para estandarizar el formato de código de su proyecto y ahorrar energía mental.
Simplemente instale el paquete previo al compromiso con:
pip install pre-commitA continuación, instale ganchos de .Pre-Commit-Config.yaml:
pre-commit installDespués de eso, su código se reformateará automáticamente en cada nuevo compromiso.
Para reformatear todos los archivos en el comando de uso del proyecto:
pre-commit run -aPara actualizar las versiones de gancho en .pre-commit-config.yaml use:
pre-commit autoupdate Las variables específicas del sistema (por ejemplo, las rutas absolutas a los conjuntos de datos) no deben estar bajo el control de versiones o dará como resultado un conflicto entre diferentes usuarios. Sus claves privadas tampoco deberían ser versionadas ya que no desea que se filtren.
La plantilla contiene el archivo .env.example , que sirve como ejemplo. Cree un nuevo archivo llamado .env (este nombre se excluye del control de versiones en .gitignore). Debe usarlo para almacenar variables de entorno como esta:
MY_VAR=/home/user/my_system_path
Todas las variables de .env se cargan en train.py automáticamente.
Hydra le permite hacer referencia a cualquier variable ENV en configuraciones .yaml como esta:
path_to_data : ${oc.env:MY_VAR} Dependiendo del registrador que esté utilizando, a menudo es útil definir el nombre métrico con / carácter:
self . log ( "train/loss" , loss )De esta manera, los registradores tratarán sus métricas como pertenecientes a diferentes secciones, lo que ayuda a organizarlas en la interfaz de usuario.
Use la biblioteca oficial de Torchmetrics para garantizar el cálculo adecuado de las métricas. ¡Esto es especialmente importante para la capacitación de múltiples GPU!
Por ejemplo, en lugar de calcular la precisión por sí mismo, debe usar la clase Accuracy proporcionada como esta:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...Asegúrese de usar diferentes instancias de métricas para cada paso para garantizar una reducción del valor adecuada en todos los procesos de GPU.
Torchmetrics proporciona métricas para la mayoría de los casos de uso, como la puntuación F1 o la matriz de confusión. Lea la documentación para más.
La guía de estilo está disponible aquí.
Sea explícito en su init. Intente definir todos los valores predeterminados relevantes para que el usuario no tenga que adivinar. Proporcionar sugerencias de tipo. ¡De esta manera, su módulo es reutilizable en todos los proyectos!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):Preserva el orden de método recomendado.
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
... Use DVC para controlar los archivos grandes, como sus datos o modelos ML capacitados.
Para inicializar el repositorio de DVC:
dvc init Para comenzar a rastrear un archivo o directorio, use dvc add :
dvc add data/MNISTDVC almacena información sobre el archivo agregado (o un directorio) en un archivo .dvc especial llamado Data/Mnist.DVC, un pequeño archivo de texto con un formato legible por humanos. Este archivo se puede verificar fácilmente como el código fuente con GIT, como marcador de posición para los datos originales:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data " Permite a otras personas usar fácilmente sus módulos en sus propios proyectos. Cambie el nombre de la carpeta src a su nombre de proyecto y complete el archivo setup.py .
Ahora su proyecto se puede instalar desde archivos locales:
pip install -e .O directamente del repositorio de Git:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradePor lo tanto, cualquier archivo se puede importar fácilmente a cualquier otro archivo como así:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModuleAlgunas configuraciones son específicas del usuario/máquina/instalación (por ejemplo, la configuración del clúster local o las rutas de disco duro en una máquina específica). Para tales escenarios, se puede crear un archivo configs/local/default.yaml que se carga automáticamente pero no rastrea por GIT.
Por ejemplo, puede usarlo para una configuración de clúster SLURM:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd Esta plantilla se inspiró en:
Otros repositorios útiles:
Lightning-Hydra-Template tiene licencia bajo la licencia MIT.
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Elimine todo lo anterior para su proyecto
Que hace
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvModelo de tren con configuración predeterminada
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpuModelo de tren con configuración de experimento elegida desde Configs/Experiment/
python src/train.py experiment=experiment_name.yamlPuede anular cualquier parámetro de la línea de comando como esta
python src/train.py trainer.max_epochs=20 data.batch_size=64

