lightning hydra template
v2.0.3
قالب نظيف لبدء مشروع التعلم العميق ⚡
انقر فوق استخدام هذا القالب لتهيئة مستودع جديد.
الاقتراحات دائما موضع ترحيب!
لماذا قد ترغب في استخدامه:
✅ حفظ على غلاية
أضف بسهولة نماذج جديدة ومجموعات بيانات ومهام وتجارب وتدريب على مسرعات مختلفة ، مثل مجموعات Multi-GPU أو TPU أو slurm.
✅ التعليم
علق تماما. يمكنك استخدام هذا الريبو كمورد تعليمي.
✅ إعادة استخدام
مجموعة من أدوات MLOPs المفيدة ، والتكوينات ، ومقتطفات التعليمات البرمجية. يمكنك استخدام هذا الريبو كمرجع لمختلف المرافق.
لماذا قد لا ترغب في استخدامه:
الأشياء تنكسر من وقت لآخر
لا يزال Lightning و Hydra يتطوران ويدمجون العديد من المكتبات ، مما يعني في بعض الأحيان أن الأمور تنكسر. لقائمة المشاكل المعروفة حاليًا ، تفضل بزيارة هذه الصفحة.
لم يتم ضبطه لهندسة البيانات
لا يتم تعديل القالب حقًا لبناء خطوط أنابيب البيانات التي تعتمد على بعضها البعض. من المفيد استخدامه للنماذج الأولية النموذجية على البيانات الجاهزة للاستخدام.
تم تجهيزه في حالة الاستخدام البسيطة
تم تصميم إعداد التكوين مع تدريب البرق البسيط في الاعتبار. قد تحتاج إلى بذل بعض الجهد لضبطه لحالات الاستخدام المختلفة ، مثل نسيج البرق.
قد لا تدعم سير العمل الخاص بك
على سبيل المثال ، لا يمكنك استئناف البحث المتعدد في Hydra Multirun أو Hyperparameter.
ملاحظة : ضع في اعتبارك أن هذا مشروع مجتمع غير رسمي.
Pytorch Lightning - غلاف Pytorch خفيف الوزن للبحث عالي الأداء من الذكاء الاصطناعي. فكر في الأمر كإطار لتنظيم رمز Pytorch الخاص بك.
Hydra - إطار لتكوين التطبيقات المعقدة بأناقة. الميزة الرئيسية هي القدرة على إنشاء تكوين هرمي بشكل ديناميكي عن طريق التكوين وتجاوزه من خلال ملفات التكوين وخط الأوامر.
يبدو أن هيكل دليل المشروع الجديد هكذا:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt يحتوي القالب على مثال مع تصنيف MNIST.
عند تشغيل python src/train.py يجب أن ترى شيئًا كهذا:
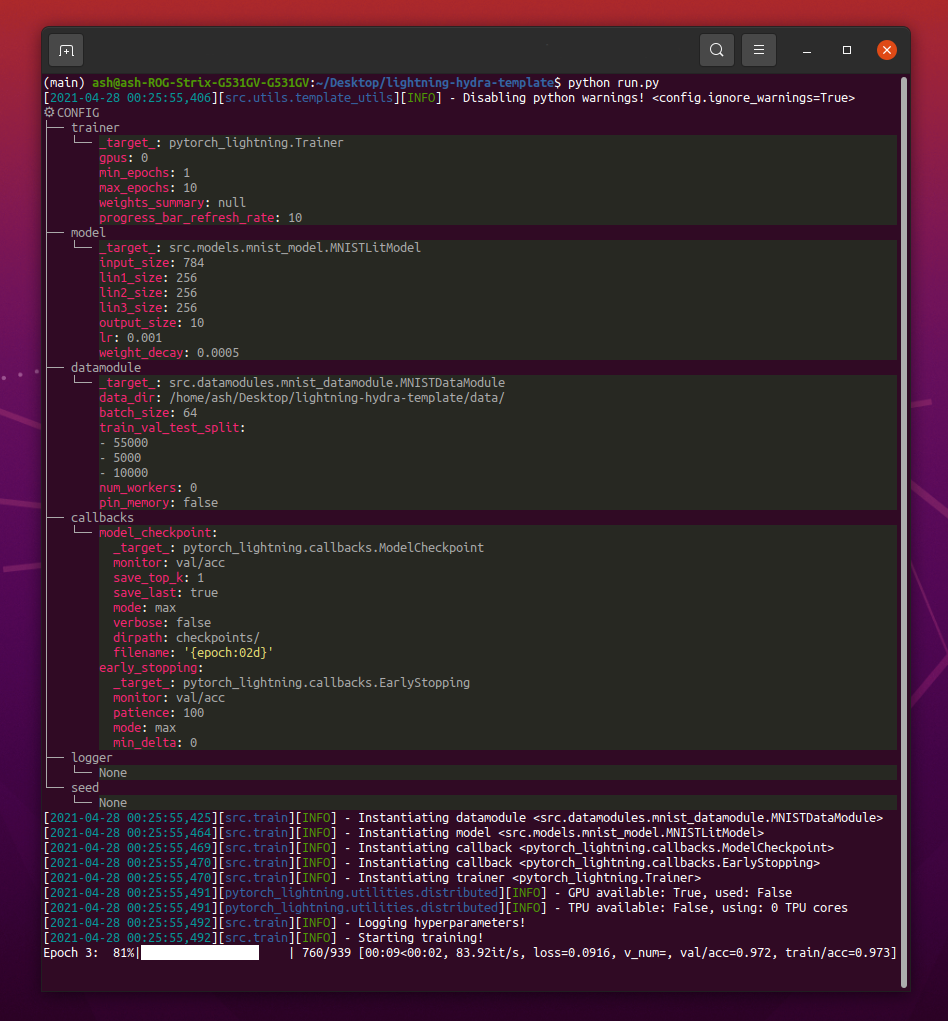
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4ملاحظة : يمكنك أيضًا إضافة معلمات جديدة باستخدام
+علامة.
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mpsتحذير : حاليًا هناك مشاكل في وضع DDP ، اقرأ هذه المشكلة لمعرفة المزيد.
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandbملاحظة : يوفر Lightning تكاملات مريحة مع أطر التسجيل الأكثر شعبية. تعرف على المزيد هنا.
ملاحظة : يتطلب استخدام WANDB إعداد الحساب أولاً. بعد ذلك فقط أكمل التكوين على النحو التالي.
ملاحظة : انقر هنا للاطلاع على مثال Wandb Dashboard الذي تم إنشاؤه باستخدام هذا القالب.
python train.py experiment=exampleملاحظة : يتم وضع تكوينات التجربة في التكوينات/التجربة/.
python train.py callbacks=defaultملاحظة : يمكن استخدام عمليات الاسترجاعات لأشياء مثل تحديد النماذج ، والتوقف المبكر وغيرها الكثير.
ملاحظة : يتم وضع تكوينات عمليات الاسترجاع في التكوينات/عوائق/.
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"ملاحظة : يوفر Pytorch Lightning حوالي 40+ من أعلام المدربين المفيدة.
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2ملاحظة : قم بزيارة التكوينات/ تصحيح/ لتكوينات تصحيح الأخطاء المختلفة.
python train.py ckpt_path="/path/to/ckpt/name.ckpt"ملاحظة : يمكن أن تكون نقطة التفتيش إما مسار أو عنوان URL.
ملاحظة : لا تستأنف تحميل CKPT حاليًا تجربة المسجل ، ولكن سيتم دعمها في إصدار Lightning في المستقبل.
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"ملاحظة : يمكن أن تكون نقطة التفتيش إما مسار أو عنوان URL.
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005ملاحظة : تقوم Hydra بتكوينات بتكاسل في وقت إطلاق الوظيفة. إذا قمت بتغيير الرمز أو تكوينه بعد إطلاق مهمة/عملية مسح ، فقد تتأثر التكوينات المؤلفة النهائية.
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=exampleملاحظة : لا يتطلب منك استخدام Optuna Sweeper إضافة أي Boilerplate إلى الرمز الخاص بك ، يتم تعريف كل شيء في ملف تكوين واحد.
تحذير : عمليات مسح Optuna ليست مقاومة للفشل (إذا تعطلت وظيفة واحدة ، فإن عملية المسح بأكملها).
python train.py -m ' experiment=glob(*) 'ملاحظة : يوفر Hydra بناء جملة خاص للسيطرة على سلوك Multiruns. تعرف على المزيد هنا. ينفذ الأمر أعلاه جميع التجارب من التكوينات/التجربة/.
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]ملاحظة :
trainer.deterministic=Trueيجعل Pytorch أكثر حتمية ولكن يؤثر على الأداء.
ملاحظة : يجب تحقيق ذلك مع التكوين البسيط باستخدام Ray AWS Launcher لـ Hydra. لم يتم تنفيذ مثال في هذا القالب.
ملاحظة : يتيح لك Hydra إتمام وسيطة التكوين التلقائية في Shell أثناء كتابتها ، عن طريق الضغط على مفتاح
tab. اقرأ المستندات.
pre-commit run -aملاحظة : قم بتطبيق خطافات ما قبل الالتزام للقيام بأشياء مثل رمز التنسيق التلقائي وتكوينات وتحليل التعليمات البرمجية أو إزالة الإخراج من أجهزة الكمبيوتر المحمولة Jupyter. انظر # أفضل الممارسات للمزيد.
قم بتحديث إصدارات خطاف ما قبل الالتزام في .pre-commit-config.yaml مع:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "يجب وضع علامة على كل تجربة من أجل تصفيةها بسهولة عبر الملفات أو في واجهة مستخدم Logger:
python train.py tags=[ " mnist " , " experiment_X " ]ملاحظة : قد تحتاج إلى الهروب من أحرف الأقواس في قذيفك باستخدام
python train.py tags=["mnist","experiment_X"].
إذا لم يتم توفير علامات ، فسيُطلب منك إدخالها من سطر الأوامر:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):إذا لم يتم توفير علامات للوصول إلى Multirun ، فسيتم رفع خطأ:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !ملاحظة : لا يتم دعم قوائم الإلحاح من سطر الأوامر حاليًا في Hydra :(
هذا المشروع موجود بفضل جميع الأشخاص الذين يساهمون.
لديك سؤال؟ وجدت خطأ؟ في عداد المفقودين ميزة محددة؟ لا تتردد في تقديم مشكلة جديدة أو مناقشة أو علاقات عامة مع العنوان والوصف.
قبل تولي مشكلة ، يرجى التحقق من ذلك:
main الحالي.اقتراحات للتحسينات دائما موضع ترحيب!
يتم إنشاء جميع وحدات Lightning Pytorch ديناميكيًا من مسارات الوحدة النمطية المحددة في التكوين. مثال على تكوين النموذج:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10باستخدام هذا التكوين ، يمكننا إنشاء مثيل للكائن مع السطر التالي:
model = hydra . utils . instantiate ( config . model ) هذا يتيح لك التكرار بسهولة عبر نماذج جديدة! في كل مرة تقوم فيها بإنشاء مسار جديد ، فقط حدد مسار الوحدة النمطية والمعلمات في ملف التكوين المناسب.
التبديل بين النماذج و datamodules مع وسيط سطر الأوامر:
python train.py model=mnistمثال على خط الأنابيب إدارة منطق الاستئصال: src/train.py.
الموقع: configs/train.yaml
يحتوي تكوين المشروع الرئيسي على تكوين التدريب الافتراضي.
ويحدد كيفية تكوين التكوين عند تنفيذ Command python train.py .
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null الموقع: التكوين/التجربة
تتيح لك تكوينات التجربة الكتابة فوق المعلمات من التكوين الرئيسي.
على سبيل المثال ، يمكنك استخدامها للتحكم في الإصدار أفضل أجهزة HyperParameters لكل مجموعة من مجموعة البيانات ومجموعة البيانات.
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " سير العمل الأساسي
python src/train.py experiment=experiment_name.yamlتصميم التجربة
لنفترض أنك ترغب في تنفيذ العديد من عمليات التشغيل لرسم كيف تتغير الدقة فيما يتعلق بحجم الدُفعة.
قم بتنفيذ عمليات التشغيل مع بعض معلمات التكوين التي تتيح لك التعرف عليها بسهولة ، مثل العلامات:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] اكتب برنامجًا نصيًا أو دفتر ملاحظات يبحث عن logs/ المجلد واسترداد سجلات CSV من عمليات التشغيل التي تحتوي على علامات معينة في التكوين. ارسم النتائج.
تقوم Hydra بإنشاء دليل إخراج جديد لكل تشغيل تم تنفيذه.
بنية التسجيل الافتراضية:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
يمكنك تغيير هذا الهيكل عن طريق تعديل المسارات في تكوين Hydra.
يدعم Lightning Pytorch العديد من أطر التسجيل الشائعة: الأوزان والتحيزات ، Neptune ، Comet ، Mlflow ، Tensorboard.
تساعدك هذه الأدوات على تتبع المقاييس المفرطة ومقاييس الإخراج وتسمح لك بمقارنة النتائج وتصورها. لاستخدام واحد منهم ببساطة أكمل تكوينه في التكوينات/المسجل وتشغيله:
python train.py logger=logger_nameيمكنك استخدام العديد منها مرة واحدة (انظر التكوينات/logger/many_loggers.yaml على سبيل المثال).
يمكنك أيضًا كتابة المسجل الخاص بك.
يوفر Lightning طريقة مريحة لتسجيل المقاييس المخصصة من Inside LightningModule. اقرأ المستندات أو ألقِ نظرة على مثال Mnist.
القالب يأتي مع اختبارات عامة تنفذ مع pytest .
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "لا تتحقق معظم الاختبارات التي تم تنفيذها من أي إخراج محدد - فهي موجودة ببساطة للتحقق من أن تنفيذ بعض الأوامر لا ينتهي في إلقاء الاستثناءات. يمكنك تنفيذها مرة واحدة في حين لتسريع التطوير.
حاليا ، تغطي الاختبارات حالات مثل:
وغيرها الكثير. يجب أن تكون قادرًا على تعديلها بسهولة لحالة الاستخدام الخاصة بك.
يتم تنفيذ @RunIf Decorator أيضًا ، مما يتيح لك إجراء اختبارات فقط إذا تم استيفاء شروط معينة ، على سبيل المثال ، GPU متاح أو أن النظام ليس Windows. انظر الأمثلة.
يمكنك تحديد بحث Hyperparameter عن طريق إضافة ملف تكوين جديد إلى Configs/HParams_Search.
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256) بعد ذلك ، قم بتنفيذها بـ: python train.py -m hparams_search=mnist_optuna
لا يتطلب استخدام هذا النهج إضافة أي Boilerplate إلى رمز ، يتم تعريف كل شيء في ملف تكوين واحد. الشيء الوحيد الضروري هو إرجاع القيمة المترية المحسنة من ملف الإطلاق.
يمكنك استخدام أطر التحسين المختلفة المدمجة مع Hydra ، مثل Optuna أو AX أو Nevergrad.
سيكون optimization_results.yaml متاحًا ضمن مجلد logs/task_name/multirun .
لا يدعم هذا النهج استئناف البحث المقاطع والتقنيات المتقدمة مثل التقلب - من أجل البحث وسير العمل الأكثر تطوراً ، على الأرجح أن تكتب مهمة تحسين مخصصة (بدون ميزة متعددة).
يأتي القالب مع سير عمل CI المنفذ في إجراءات GitHub:
.github/workflows/test.yaml : تشغيل جميع الاختبارات مع Pytest.github/workflows/code-quality-main.yaml : تشغيل مسبقات على الفرع الرئيسي لجميع الملفات.github/workflows/code-quality-pr.yaml : تشغيل مسبقات على طلبات السحب للملفات المعدلة فقط يدعم Lightning طرقًا متعددة للقيام بالتدريب الموزع. الأكثر شيوعًا هو DDP ، الذي يولد عملية منفصلة لكل GPU ومتوسطات التدرجات بينهما. للتعرف على الأساليب الأخرى اقرأ مستندات البرق.
يمكنك تشغيل DDP على مثال Mnist مع 4 وحدات معالجة الرسومات مثل هذا:
python train.py trainer=ddpملاحظة : عند استخدام DDP ، يجب أن تكون حذراً في كيفية كتابة النماذج الخاصة بك - اقرأ المستندات.
أبسط طريقة هي تمرير سمة Datamodule مباشرة إلى النموذج عند التهيئة:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )ملاحظة : ليس حلًا قويًا للغاية ، لأنه يفترض أن جميع Datamodules لديك سمة
some_paramمتوفرة.
وبالمثل ، يمكنك تمرير تكوين Datamodule بالكامل كمعلمة init:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )يمكنك أيضًا تمرير معلمة تكوين Datamodule إلى النموذج الخاص بك من خلال الاستيفاء المتغير:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}طريقة أخرى هي الوصول إلى Datamodule في LightningModule مباشرة من خلال المدرب:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_paramملاحظة : يعمل هذا فقط بعد بدء التدريب لأن المدرب وإلا فلن يكون المدرب متاحًا بعد في LightningModule.
عادة ما يكون من غير الضروري تثبيت بيئة Anaconda الكاملة ، يجب أن تكون Miniconda كافية (الأوزان حوالي 80 ميجابايت).
تتمثل الميزة الكبيرة في الكوندا في أنه يسمح بتثبيت الحزم دون الحاجة إلى متاحين لمجموعة أو مكتبات معينة في النظام (نظرًا لأنه يقوم بتثبيت الثنائيات المسبقة) ، لذلك غالبًا ما يسهل تثبيت بعض التبعيات على سبيل المثال لدعم GPU.
كما يتيح لك الوصول إلى بيئاتك على مستوى العالم والتي قد تكون أكثر ملاءمة من إنشاء بيئة محلية جديدة لكل مشروع.
مثال التثبيت:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shتحديث كوندا:
conda update -n base -c defaults condaإنشاء بيئة كوندا جديدة:
conda create -n myenv python=3.10
conda activate myenv استخدم السنانير المسبقة لتوحيد تنسيق الرمز لمشروعك وتوفير الطاقة العقلية.
ما عليك سوى تثبيت حزمة ما قبل الالتزام مع:
pip install pre-commitبعد ذلك ، قم بتثبيت الخطافات من .pre-commit-config.yaml:
pre-commit installبعد ذلك سيتم إعادة تنسيق رمزك تلقائيًا على كل التزام جديد.
لإعادة تنسيق جميع الملفات في أمر استخدام المشروع:
pre-commit run -aلتحديث إصدارات الخطاف في .pre-commit-config.yaml استخدام:
pre-commit autoupdate لا ينبغي أن تكون المتغيرات الخاصة بالنظام (مثل المسارات المطلقة إلى مجموعات البيانات) تحت التحكم في الإصدار أو أنها ستؤدي إلى تعارض بين المستخدمين المختلفين. يجب ألا يتم إصدار مفاتيحك الخاصة لأنك لا تريد تسربها.
يحتوي القالب على ملف .env.example ، والذي يعمل كمثال. إنشاء ملف جديد يسمى .env (يتم استبعاد هذا الاسم من التحكم في الإصدار في .gitignore). يجب عليك استخدامه لتخزين متغيرات البيئة مثل هذا:
MY_VAR=/home/user/my_system_path
يتم تحميل جميع المتغيرات من .env في train.py تلقائيًا.
يتيح لك Hydra الرجوع إلى أي متغير ENV في .yaml يتكوين مثل هذا:
path_to_data : ${oc.env:MY_VAR} اعتمادًا على المسجل الذي تستخدمه ، غالبًا ما يكون من المفيد تحديد اسم متري مع / حرف:
self . log ( "train/loss" , loss )وبهذه الطريقة ، سيتعامل سجلات المسجلين إلى مقاييسك على أنها تنتمي إلى أقسام مختلفة ، مما يساعد على تنظيمها في واجهة المستخدم.
استخدم مكتبة TorchMetrics الرسمية لضمان حساب مناسب للمقاييس. هذا مهم بشكل خاص للتدريب متعدد GPU!
على سبيل المثال ، بدلاً من حساب الدقة بنفسك ، يجب عليك استخدام فئة Accuracy المقدمة مثل هذا:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...تأكد من استخدام مثيل متري مختلف لكل خطوة لضمان تخفيض القيمة المناسبة على جميع عمليات GPU.
يوفر TorchMetrics مقاييس لمعظم حالات الاستخدام ، مثل درجة F1 أو مصفوفة الارتباك. اقرأ الوثائق للمزيد.
دليل النمط متاح هنا.
كن واضحا في init الخاص بك. حاول تحديد جميع العوامل الافتراضية ذات الصلة بحيث لا يتعين على المستخدم التخمين. توفير تلميحات النوع. بهذه الطريقة تكون الوحدة النمطية قابلة لإعادة الاستخدام عبر المشاريع!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):الحفاظ على ترتيب الطريقة الموصى بها.
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
... استخدم DVC للتحكم في الملفات الكبيرة ، مثل بياناتك أو نماذج ML المدربة.
لتهيئة مستودع DVC:
dvc init لبدء تتبع ملف أو دليل ، استخدم dvc add :
dvc add data/MNISTتقوم DVC بتخزين معلومات حول الملف المضافة (أو الدليل) في ملف .DVC خاص باسم Data/Mnist.dvc ، وهو ملف نصي صغير بتنسيق قابل للقراءة الإنسان. يمكن إصدار هذا الملف بسهولة مثل التعليمات البرمجية المصدر مع GIT ، كعنصر نائب للبيانات الأصلية:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data " يسمح للآخرين باستخدام وحداتك بسهولة في مشاريعهم الخاصة. تغيير اسم مجلد src إلى اسم مشروعك وأكمل ملف setup.py .
الآن يمكن تثبيت مشروعك من الملفات المحلية:
pip install -e .أو مباشرة من مستودع GIT:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradeلذلك يمكن استيراد أي ملف بسهولة إلى أي ملف آخر مثل:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModuleبعض التكوينات هي المستخدم/الجهاز/التثبيت محدد (مثل تكوين الكتلة المحلية ، أو مسارات Rarddrive على جهاز معين). لمثل هذه السيناريوهات ، يمكن إنشاء ملف/محلي/default.yaml يتم تحميله تلقائيًا ولكن لا يتم تتبعه بواسطة GIT.
على سبيل المثال ، يمكنك استخدامه لتكوين مجموعة slurm:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd هذا القالب مستوحى من:
مستودعات مفيدة أخرى:
تم ترخيص Lightning-Hydra-Template بموجب ترخيص MIT.
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
احذف كل شيء أعلاه لمشروعك
ماذا تفعل
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvنموذج القطار مع التكوين الافتراضي
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpuنموذج القطار مع تكوين التجربة المختار من التكوينات/التجربة/
python src/train.py experiment=experiment_name.yamlيمكنك تجاوز أي معلمة من سطر الأوامر مثل هذا
python src/train.py trainer.max_epochs=20 data.batch_size=64

