workflUX
1.0.0
(Anteriormente conhecido como cwlab.)
Um aplicativo da web de código aberto e pronto para a nuvem para implantação simplificada de fluxos de trabalho de big data.
CI/CD:
Embalagem:
Citação e contribuição:
ATENÇÃO: O Workflux está no estado beta e as mudanças de ruptura podem ser introduzidas no futuro. No entanto, se você gosta de testá -lo ou mesmo executar em produção, nós o apoiaremos.
A instalação pode ser feita usando PIP:
python3 -m pip install workflux
Consulte a seção "Configuração" para uma discussão das opções disponíveis.
Inicie o servidor da web com sua configuração personalizada (ou deixe de fora o sinalizador --config para usar o padrão):
workflux up --config config.yaml
Se você deseja fazer uso de contêineres para gerenciamento de dependência, é necessário instalar o Docker ou uma solução de contêiner com compatível com o Docker, como singularidade ou udocker. Para executar no Windows ou MacOS, instale as versões dedicadas do Docker: Docker for Windows, Docker for Mac
O uso da interface da Web deve ser auto-explicativo com as instruções de construção. A seção a seguir fornece uma visão geral do cenário de uso básico.
O Workflux está escrito em Python agnóstico da plataforma e, portanto, pode ser executado em:
Qualquer corredor da CWL que tenha uma interface de linha de comando pode ser integrado ao Fluxo de Works para executar fluxos de trabalho da CWL ou fretadores de ferramentas, como:
Portanto, o Workflux pode ser usado em qualquer infraestrutura suportada por esses corredores da CWL, incluindo:
* Observe:
A execução no Windows é suportada apenas pela CWLTool, que fala com o Docker for Windows. Portanto, ferramentas e fluxos de trabalho com CWL, que originalmente projetados para Linux/MacOS podem ser executados no Windows com uma interface gráfica fornecida pelo Workflux.
Consulte o nosso tutorial, que o leva a um exemplo simples, mas significativo, de como o Flux Workflux pode ser usado para comparar as sequências de proteínas de pico do CoVID-19 em duas coortes de pacientes.
Aqui estão alguns apetizadores: 
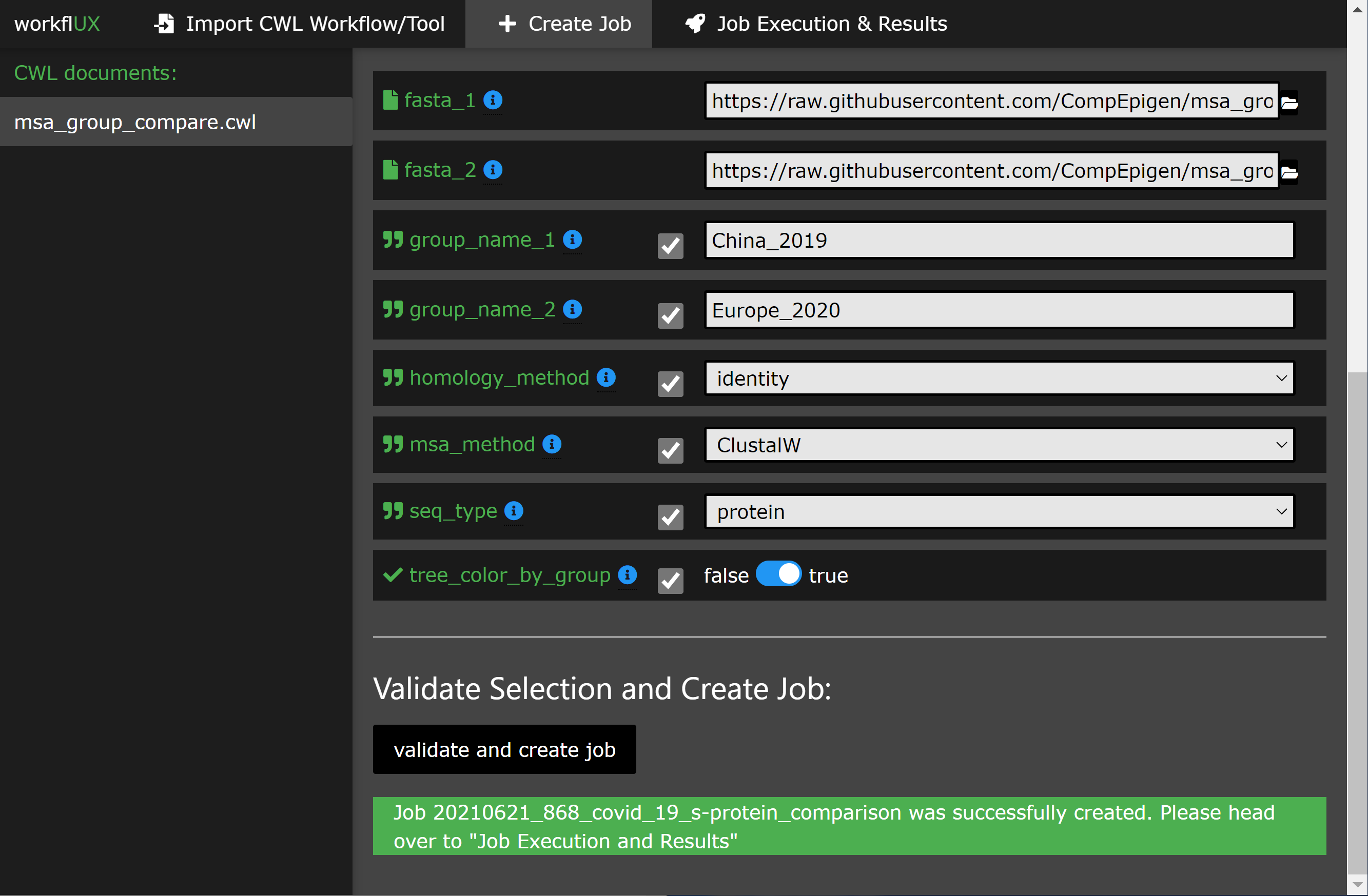
O Workflux é um pacote altamente versátil e quase não faz suposições sobre o seu ambiente difícil e de software usado para a execução da CWL. Para adaptá -lo ao seu sistema e usar o caso, um conjunto de opções de configuração está disponível:
Todas as opções de configuração podem ser especificadas em um único arquivo YAML que é fornecido ao Workflux após o início:
workflux up --config my_config.yaml
Para obter um exemplo de arquivo de configuração, execute o seguinte comando:
workflux print_config > config.yaml (ou veja o exemplo abaixo)
Web_server_host :
Especifique o host ou endereço IP no qual o servidor da web deve ser executado. Use localhost para uso local apenas na sua máquina. Use 0.0.0.0 para permitir a acessibilidade remota por outras máquinas na mesma rede.
Padrão : localhost
Web_server_port :
Especifique a porta usada pelo servidor da web.
Padrão : 5000
Temp_dir :
Diretório para arquivos temporários.
Padrão : uma subpasta "Workflux/Temp" no diretório doméstico
Workflow_dir :
Diretório para salvar documentos CWL.
Padrão : uma subpasta "Workflux/Temp" no diretório doméstico
EXEC_DIR :
Diretório para salvar dados de execução, incluindo arquivos de saída.
Padrão : uma subpasta "Workflux/Temp" no diretório doméstico
Default_input_dir :
Diretório padrão em que os usuários podem pesquisar arquivos de entrada. Você pode especificar diretórios de entrada adicionais usando o parâmetro " add_input_dirs ". Padrão : uma subpasta "Workflux/Temp" no diretório doméstico
Db_dir :
Diretório para bancos de dados.
Padrão : uma subpasta "Workflux/Temp" no diretório doméstico
Add_input_dirs :
Além de " default_input_dir ", esses diretórios podem ser pesquisados pelo usuário por arquivos de entrada.
Especifique -os no formato " Nome: Path ", como mostrado neste exemplo:
ADD_INPUT_DIRS:
GENOMES_DIR: '/ngs_share/genomes'
PUBLIC_GEO_DATA: '/datasets/public/geo'
Padrão : Nenhum diretor de entrada adicional.
Add_input_and_upload_dirs :
Os usuários podem pesquisar esses diretórios quanto a arquivos de entrada (além de " default_input_dir ") e também podem fazer upload de seus arquivos.
Especifique -os no formato " Nome: Path ", como mostrado neste exemplo:
ADD_INPUT_AND_UPLOAD_DIRS:
UPLOAD_SCRATCH: '/scratch/upload'
PERMANEN_UPLOAD_STORE: '/datasets/upload'
Padrão : Nenhum diretor de entrada adicional.
Debug :
Se definido como true, o modo de depuração é ativado. Não use em sistemas de produção.
Padrão : false
É aqui que você configura como executar trabalhos de CWL em seu sistema. Um perfil consiste em quatro etapas: preparar, executar, avaliar e finalizar (apenas o executivo necessário, o restante é opcional). Para cada etapa, você pode especificar comandos executados no terminal Bash ou CMD.
Você pode definir vários perfil de execução, como mostrado no exemplo de configuração abaixo. Isso permite que os usuários de front -end escolham entre diferentes opções de execução (por exemplo, usando diferentes corredores de CWL, diferentes sistemas de gerenciamento de dependência ou até mesmo escolha um entre vários vários infraestruturas de execução em lote disponíveis como LSF, PBS, ...). Para cada perfil de execução, os seguintes parâmetros de configuração estão disponíveis (mas apenas o tipo e o executivo são necessários):
tipo :
Especifique qual shell/intérprete a ser usado. Para Linux ou MacOS, use bash . Para Windows, use powershell .
Obrigatório .
max_retries : especifique quantas vezes a execução (todas as etapas) está se refletindo antes de marcar uma execução como falhou.
tempo esgotado :
Para cada etapa no perfil de execução, você pode definir um limite de tempo limite.
Padrão :
prepare : 120
exec : 86400
eval : 120
finalize : 120 Prepare *:
Comandos que são executados antes da execução real da CWL. Por exemplo, para carregar ambientes de python/conda necessários.
Opcional .
EXEC *:
Comandos para iniciar a execução da CWL. Geralmente, esta é apenas a linha de comando para executar o corredor da CWL. O stdout e o stderr do corredor da CWL devem ser redirecionados para o arquivo de log predefinido.
Obrigatório .
Eval *:
O status de saída no final da etapa do EXEC é verificado automaticamente. Aqui você pode especificar comandos para avaliar adicionalmente o conteúdo do log de execução para determinar se a execução foi bem -sucedida. Para comunicar a falha no WorkFlux, defina a variável SUCCESS como False .
Opcional .
Finalize *: comandos executados após o EXEC e avaliar . Por exemplo, isso pode ser usado para limpar arquivos temporários.
* Notas adicionais sobre etapas do perfil de execução:
JOB_IDRUN_ID (observe: é apenas exclusivo dentro de um trabalho)WORKFLOW (o caminho para o documento CWL usado)RUN_INPUT (o caminho para o arquivo YAML contendo parâmetros de entrada)OUTPUT_DIR (o caminho do diretório de saída específico da execução)LOG_FILE (o caminho do arquivo de log que deve receber o stdout e o stderr do CWL Runner)SUCCESS (se definido como False , a execução será marcada como falhada e terminada)PYTHON_PATH (o caminho para o intérprete Python usado para executar o Workflux)SUCCESS como False .{...} ) deve estar em uma linha.Abaixo, você pode encontrar configurações de exemplo para a execução local de fluxos de trabalho ou ferramentas da CWL com o CWLTool.
WEB_SERVER_HOST : localhost
WEB_SERVER_PORT : 5000
DEBUG : False
TEMP_DIR : ' /home/workflux_user/workflux/temp '
WORKFLOW_DIR : ' /home/workflux_user/workflux/workflows '
EXEC_DIR : ' /datasets/processing_out/ '
DEFAULT_INPUT_DIR : ' /home/workflux_user/workflux/input '
DB_DIR : ' /home/workflux_user/workflux/db '
ADD_INPUT_DIRS :
GENOMES_DIR : ' /ngs_share/genomes '
PUBLIC_GEO_DATA : ' /datasets/public/geo '
ADD_INPUT_AND_UPLOAD_DIRS :
UPLOAD_SCRATCH : ' /scratch/upload '
PERMANEN_UPLOAD_STORE : ' /datasets/upload '
EXEC_PROFILES :
cwltool_local :
type : bash
max_retries : 2
timeout :
prepare : 120
exec : 86400
eval : 120
finalize : 120
exec : |
cwltool --outdir "${OUTPUT_DIR}" "${WORKFLOW}" "${RUN_INPUT}"
>> "${LOG_FILE}" 2>&1
eval : |
LAST_LINE=$(tail -n 1 ${LOG_FILE})
if [[ "${LAST_LINE}" == *"Final process status is success"* ]]
then
SUCCESS=True
else
SUCCESS=False
ERR_MESSAGE="cwltool failed - ${LAST_LINE}"
fi WEB_SERVER_HOST : localhost
WEB_SERVER_PORT : 5000
DEBUG : False
TEMP_DIR : ' C:Usersworkflux_userworkfluxtemp '
WORKFLOW_DIR : ' C:Usersworkflux_userworkfluxworkflows '
EXEC_DIR : ' D:processing_out '
DEFAULT_INPUT_DIR : ' C:Usersworkflux_userworkfluxinput '
DB_DIR : ' C:Usersworkflux_userworkfluxdb '
ADD_INPUT_DIRS :
GENOMES_DIR : ' E:genomes '
PUBLIC_GEO_DATA : ' D:publicgeo '
ADD_INPUT_AND_UPLOAD_DIRS :
UPLOAD_SCRATCH : ' E:upload '
PERMANEN_UPLOAD_STORE : ' D:upload '
EXEC_PROFILES :
cwltool_windows :
type : powershell
max_retries : 2
timeout :
prepare : 120
exec : 86400
eval : 120
finalize : 120
exec : |
. "${PYTHON_PATH}" -m cwltool --debug --default-container ubuntu:16.04 --outdir "${OUTPUT_DIR}" "${CWL}" "${RUN_INPUT}" > "${LOG_FILE}" 2>&1
eval : |
$LAST_LINES = (Get-Content -Tail 2 "${LOG_FILE}")
if ($LAST_LINES.Contains("Final process status is success")){$SUCCESS="True"}
else {$SUCCESS="False"; $ERR_MESSAGE = "cwltool failed - ${LAST_LINE}"} Este pacote é gratuito para usar e modificar sob a licença Apache 2.0.
Obrigado a essas pessoas maravilhosas (key emoji):
Kersten Breuer ? | Pavlo Lutsik ? ? | Sven Twardziok | Marius ? | Lukas Jelonek | Michael Franklin | Alex Kanitz |
Yoanan PageAud | Yassen Asenov ? | Yuyu Lin ? |
Este projeto segue a especificação de todos os contribuintes. Contribuições de qualquer tipo de boas -vindas!


