cassandra es index
1.0.0
<type>Esta documentação explica o uso e a configuração do "esindex" que é um índice secundário baseado em Elasticsearch para Cassandra.
Este plug -in requer um cluster Elasticsearch (s) já configurado.
O plug -in instalará em uma versão regular do Cassandra 4.0.x baixada de http://cassandra.apache.org/. Não há nada a mudar nos arquivos de configuração do Cassandra para suportar o índice. O comportamento de Cassandra permanece inalterado para aplicativos que não usam o índice.
Uma vez criado em uma tabela Cassandra, esse índice permite executar consultas de pesquisa de pesquisa de "pesquisa completa" no Cassandra usando o CQL e retornar linhas correspondentes a dados do Cassandra. O uso deste plug -in não requer alteração de código -fonte Cassandra, implementamos o índice Elasticsearch para Cassandra usando:
As versões testadas são elasticsearch 5.x, 6.x, 7.x e Cassandra 4.0.x. No entanto, o plug -in também pode funcionar com diferentes versões do Elasticsearch (1.7, 2.x 5.x, 6.x, 7.x) se o aplicativo fornecer os mapeamentos e opções correspondentes. Outras versões do Apache Cassandra como 1.x 2.x, 3.x ou 4.1 não são suportadas, pois a interface do índice secundário usada pelo plug -in é diferente. Outros fornecedores de Cassandra não são testados, o Scylladb não é suportado.
| Versões | Elasticsearch 1.x | Elasticsearch 2.x | Elasticsearch 5.x | Elasticsearch 6.x. | Elasticsearch 7.x. |
|---|---|---|---|---|---|
| Cassandra 1.x | Não | Não | Não | Não | Não |
| Cassandra 2.x | Não | Não | Não | Não | Não |
| Cassandra 3.x | Não | Não | Não | Não | Não |
| Cassandra 4.x | Limitado | Limitado | Limitado | Sim | Sim |
Este projeto requer Maven e Compila com Java 8. Para construir o plug -in, na raiz do projeto executivo:
MVN Pacote limpo
Isso vai construir um "tudo em um frasco" em target/distribution/lib4cassandra
<dependency>
<groupId>com.genesyslab</groupId>
<artifactId>es-index</artifactId>
<version>9.2.000.00</version>
</dependency>
Veja o pacote Github
Veja o repositório maven
Coloque es-index-9.2.000.xx-jar-with-dependencies.jar na pasta Lib de Cassandra, juntamente com outros frascos de Cassandra, por exemplo '/usr/share/Cassandra/lib' em todos os nós Cassandra. Inicie ou reinicie seus nó (s) Cassandra.
Devido à falta de teste, as tabelas com chaves de agrupamento não são suportadas. Somente uma chave de partição é suportada, as chaves de partição compostas devem funcionar, mas não foram extensivamente testadas.
O ESIndex suporta apenas o nível de linha TTL, onde todas as células expirarão ao mesmo tempo e o documento ES correspondente pode ser excluído ao mesmo tempo. Se uma linha tiver células que expirarem em momentos diferentes, o documento correspondente será excluído quando a última célula expirar. Se o uso de TTL de células diferentes, os dados retornados de uma pesquisa ainda serão consistentes à medida que os dados são lidos no SSTABLES, mas ainda será possível encontrar a linha usando dados expirados usando uma consulta ES.
É possível criar vários índices na mesma tabela, o Esindex não impedirá isso. No entanto, se mais de um esindex existir, o comportamento pode ser inconsistente, essa configuração não será suportada. O comando cqlsh 'descreve a tabela <Ks.tablename>' pode ser usado para mostrar índices criados na tabela e soltá -los, se necessário.
Por uma questão de simplicidade, crie este espaço de chave primeiro:
CREATE KEYSPACE genesys WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}
Vamos usar abaixo da tabela como exemplo:
CREATE TABLE genesys.emails (
id UUID PRIMARY KEY,
subject text,
body text,
userid int,
query text
);
Você precisa dedicar uma coluna de texto dummy para uso do índice. Esta coluna nunca deve receber dados. Neste exemplo, a coluna query é a coluna fictícia.
Aqui está como criar o índice para a tabela de exemplo e usar o Eshost para Elasticsearch:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {'unicast-hosts': 'eshost:9200'};
Por exemplo, se o seu servidor Elasticsearch estiver ouvindo no localhost , substitua o Eshost pelo localhost .
Os erros retornados pelo CQL são muito limitados, se algo der errado, como seu host Elasticsearch indisponível, você receberá um tempo limite ou outro tipo de exceção. Você terá que verificar os logs da Cassandra para entender o que deu errado.
Não fornecemos nenhum mapeamento, por isso estamos confiando no mapeamento dinâmico do Elasticsearch, vamos inserir alguns dados:
INSERT INTO genesys.emails (id, subject, body, userid)
VALUES (904b88b2-9c61-4539-952e-c179a3805b22, 'Hello world', 'Cassandra is great, but it''s even better with EsIndex and Elasticsearch', 42);
Você pode ver que o índice está sendo criado no Elasticsearch se tiver acesso a logs:
[o.e.c.m.MetaDataCreateIndexService] [node-1] [genesys_emails_index@] creating index, cause [api], templates [], shards [5]/[1], mappings []
[INFO ][o.e.c.m.MetaDataMappingService] [node-1] [genesys_emails_index@/waSGrPvkQvyQoUEiwqKN3w] create_mapping [emails]
Agora podemos pesquisar Cassandra usando o Elasticsearch através do índice, aqui está uma pesquisa de sintaxe do Lucene:
select id, subject, body, userid, query from emails where query='body:cassan*';
id | subject | body | userid | query
--------------------------------------+-------------+-------------------------------------------------------------------------+--------+-------
904b88b2-9c61-4539-952e-c179a3805b22 | Hello world | Cassandra is great, but it's even better with EsIndex and Elasticsearch | 42 |
{
"_index": "genesys_emails_index@",
"_type": "emails",
"_id": "904b88b2-9c61-4539-952e-c179a3805b22",
"_score": 0.24257512,
"_source": {
"id": "904b88b2-9c61-4539-952e-c179a3805b22"
},
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.24257512
}
}
(1 rows)
(JSON foi formatado)
Todas as linhas conterão dados do Cassandra carregados de SSTABLES usando a consistência do CQL. Os dados na coluna 'Query' são os metadados retornados pelo Elasticsearch.
Aqui está como consultar o Elasticsearch para verificar o mapeamento gerado: GET http://eshost:9200/genesys_emails_index@/emails/_mapping?pretty
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"properties" : {
"IndexationDate" : {
"type" : " date "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"id" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
}
}
}
}
}
}O plug -in esindex adicionou dois campos:
Podemos ver que o mapeamento parece bom, mas o Elasticsearch não percebeu que o UserID é um número inteiro e adicionado [palavra -chave] a todo o texto.
Aqui está como os dados se parecem no Elasticsearch:
GET http://localhost:9200/genesys_emails_index@/emails/_search?pretty&q=body:cassandra
{
"took" : 2 ,
"timed_out" : false ,
"_shards" : {
"total" : 5 ,
"successful" : 5 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.2876821 ,
"hits" : [
{
"_index" : " genesys_emails_index@ " ,
"_type" : " emails " ,
"_id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"_score" : 0.2876821 ,
"_source" : {
"id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"body" : " Cassandra is great, but it's even better with EsIndex and Elasticsearch " ,
"subject" : " Hello world " ,
"userid" : " 42 " ,
"IndexationDate" : " 2019-01-15T16:53:00.107Z " ,
"_cassandraTtl" : 2147483647
}
}
]
}
} Vamos corrigir o mapeamento soltando o índice: drop index genesys.emails_query_idx; Isso também descartará o Elasticsearch Index e os dados!
e recriá -lo com um mapeamento adequado:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {
'unicast-hosts': 'localhost:9200',
'mapping-emails': '
{
"emails":{
"date_detection":false,
"numeric_detection":false,
"properties":{
"id":{
"type":"keyword"
},
"userid":{
"type":"long"
},
"subject":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"body":{
"type":"text"
},
"IndexationDate":{
"type":"date",
"format":"yyyy-MM-dd''T''HH:mm:ss.SSS''Z''"
},
"_cassandraTtl":{
"type":"long"
}
}
}
}
'};
Isso criará um novo índice fornecerá mapeamento e reiíex os dados que estão em Cassandra.
Aqui está o mapeamento ES resultante:
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"date_detection" : false ,
"numeric_detection" : false ,
"properties" : {
"IndexationDate" : {
"type" : " date " ,
"format" : " yyyy-MM-dd'T'HH:mm:ss.SSS'Z' "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text "
},
"id" : {
"type" : " keyword "
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " long "
}
}
}
}
}
}Agora que o mapeamento é definido corretamente, podemos pesquisar o UserID como um número. Neste exemplo, estamos usando o Elasticsearch Consulta DSL:
select id, subject, body, userid from genesys.emails
where query='{"query":{"range":{"userid":{"gte":10,"lte":50}}}}';
@ Row 1
---------+-------------------------------------------------------------------------
id | 904b88b2-9c61-4539-952e-c179a3805b22
subject | Hello world
body | Cassandra is great, but it's even better with EsIndex and Elasticsearch
userid | 42
É muito importante obter o mapeamento antes de iniciar a produção. A reindexação de uma tabela grande levará muito tempo e colocará uma carga significativa em Cassandra e Elasticsearch. Você precisará verificar os logs do Cassandra quanto a erros no seu mapeamento de ES. Certifique -se de escapar de citações únicas (') dobrando -as nas opções JSON fornecidas ao comando Create Index.
Abaixo estão todas as opções relacionadas à configuração do Elasticsearch Index. Os nomes de chave podem usar o hífen '-' char ou pontos. Por exemplo, ambos os nomes funcionarão:
Observe que todas as opções abaixo são específicas para a implementação da Genesys e não o Elasticsearch.
Se as classes de jest não forem encontradas, o modo fictício será ativado e nenhum outro caso se aplica.
O Multi-Datacenter é suportado e os dados são replicados apenas por replicação de fofocas Cassandra. Os clusters ES em diferentes DCs não são os mesmos e nunca devem ser unidos ou o desempenho será impactado. Como os dados são replicados no nível da tabela, o ESIndex receberá uma atualização em cada cluster DC e Local ES, também será atualizado.
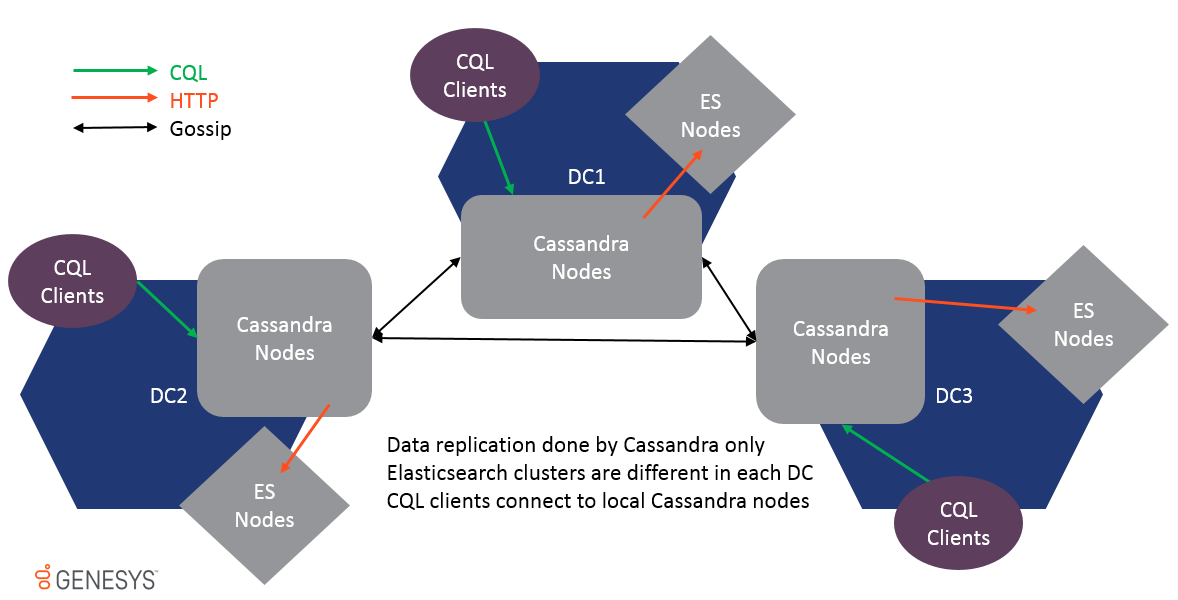
Para suportar o Multi-DC, todas as opções podem ser prefixadas pelo Datacenter e Nome do Rack para tornar as configurações específicas do local, por exemplo:
Para fornecer Índice Cassandra para Elasticsearch com credenciais, cada nó deve ter a variável de ambiente definida corretamente antes de iniciar. Isso deve ser definido em todos os hosts de Cassandra.
O exemplo abaixo fornece a senha para o usuário 'elástico' e senha 'ExpleTPassword' separado por: (cólon). Isso pode ser feito diretamente no sistema como uma variável de ambiente ou no atalho que inicia o Cassandra.
Credencials = Elastic: ExementPassword Depois que o índice for inicializado com êxito, ele escreverá "Credenciais de pesquisa de elasticidade fornecidas" nos logs Cassandra no nível de informação. Uma vez que esta mensagem é emitida, é possível limpar a variável de ambiente. Se Cassandra for reiniciado, a variável de ambiente deve ser definida novamente antes de iniciar. As credenciais são mantidas apenas na memória e não são salvas em nenhum outro lugar. Se o usuário e/ou a senha for alterados, todos os nós Cassandra deverão ser reiniciados com o valor da variável de ambiente atualizado.
No conjunto de opções de índice
unicast-hosts = https : //<host name>:9200
Atualmente, não é possível migrar um índice existente de HTTP para HTTPS, o uso de um ou outro deve ser decidido antes de criar o esquema Cassandra. Para facilitar a implantação do HTTPS, o índice confiará automaticamente em todos os certificados HTTPS.
É possível manter os dados do lado do Elasticsearch por um período mais longo do que o Cassandra TTL definido. Este modo é girado usando a opção ES-Analytic no modo. Quando a opção estiver ativada, o ElasticIndex pulará todas as operações de exclusão.
Para impedir que os dados cresçam demais no lado da ES, é aconselhável usar as configurações de mudança de TTL e delete com força.
Ao criar o índice, você fornecerá opções de índice, bem como opções de índice de pesquisa de elasticidade usando o comando "usando opção".
As opções de índice devem ser especificadas na criação do índice, aqui está um exemplo
CREATE CUSTOM INDEX on genesys.email(query) using 'com.genesyslab.webme.commons.index.EsSecondaryIndex' WITH options =
{
'read-consistency-level':'QUORUM',
'insert-only':'false',
'index-properties': '{
"index.analysis.analyzer.dashless.tokenizer":"dash-ex",
"index.analysis.tokenizer.dash-ex.pattern":"[^\\w\\-]",
"index.analysis.tokenizer.dash-ex.type":"pattern"
}',
'mapping-email': '{
"email": {
"dynamic": "false",
"properties": {
"subject" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}',
'discard-nulls':'false',
'async-search':'true',
'async-write':'false'
};
Você também pode definir ou substituir as opções usando variáveis de ambiente ou propriedades do sistema Java, prefixando opções com 'Genesys-es-'.
As opções fornecidas no comando "Criar índice personalizado" são usadas primeiro. Eles podem ser substituídos localmente usando um arquivo chamado es-index.properties encontrados em ".", "./Conf/", "../conf/" ou "./bin/". (pode ser alterado com -dgenesys-es-esi-fil-File ou -dgenesys.es.esi.file System Property)
Aqui está um exemplo para o conteúdo do arquivo:
insert-inly = true descarte-nula = false assíncrono-write = false
| Nome | Padrão | Descrição |
|---|---|---|
| resultados max | 10000 | Número de resultados para ler as pesquisas ES para carregar linhas Cassandra. |
| LEAD-CONSISTÊNCIA | UM | Utilizado para pesquisas, esse nível de consistência é usado para carregar linhas Cassandra. |
| apenas inserir | falso | Por padrão, o ESIndex usará operações UPSERT. Na inserção, apenas os dados do modo serão sempre substituídos. |
| assíncrono-escravo | verdadeiro | Envie o índice atualiza de forma assíncrona sem verificar a execução correta. Isso fornece gravações muito mais rápidas, mas os dados podem se tornar inconsistentes se o cluster ES não estiver disponível, porque as gravações não falharão. O padrão é verdadeiro. |
| segmento | DESLIGADO | Off, hora, dia, mês, ano, segmentação de índice automático personalizado é controlado por essa configuração. Se definido como dia, todos os dias um novo índice será criado sob o alias. Observe que os índices vazios são excluídos automaticamente a cada hora. Nota: A configuração de hora é desencorajada, pois criará muitos índices e pode diminuir o desempenho. Essa configuração é recomendada para fins de desenvolvimento e teste. |
| nome do segmento | Se segmento = personalizado Este valor será usado para a criação de novos índices. | |
| Mapeamento- <Tepe> | {} | Para cada índice secundário, o nome da tabela é passado como um tipo, por exemplo, mapeando-visit = {JSON Definition}. |
| unicast-hosts | http: // localhost: 9200 | Uma lista separada por vírgula do host, pode ser host1, host2, host3 ou http: // host1, http: // host2, http: // host3 ou http: // host1: 9200, http: // host2: 9200, http: // host3: 9200. Se o protocolo ou porta estiverem ausentes HTTP e 9200 assumidos. É possível usar HTTPS. |
| descarte-nulos | verdadeiro | Não passe valores nulos para o índice ES, significa que você não poderá excluir um valor. O padrão é verdadeiro . |
| Propriedades do índice | {} | As propriedades como uma string json, passadas para criar um novo índice, podem conter definições de tokenizer, por exemplo. |
| JSON-Serialized-Fields | {} | Uma string separada coma definindo que uma coluna de string deve ser indexada como uma string json. Strings para parsáveis não json impedirão inserções em Cassandra. |
| JSON-FLAT-ERIALIZADO CAMPO | {} | Uma string separada coma definindo que uma coluna de string deve ser indexada como um documento JSON seguro para tipos. O Mapeamento JSON Elasticsearch não permite indexar um valor que alterará o tipo ao longo do tempo. Por exemplo, {"key": "value"} não pode se tornar {"key": {"subkey": "value"}} No Elasticsearch, você receberá uma exceção de mapeamento. Esse json-flat será conversor em um objeto JSON que possui teclas de string e matrizes de string como valores. |
| fictício | falso | Desative completamente o índice secundário. Observe que, se as classes de jest não forem encontradas, o índice será colocado no modo fictício automaticamente. |
| Validar-emerias | falso | Envia consultas de pesquisa para ES para validação para fornecer erros de sintaxe significativos em vez de tempo limite de Cassandra. |
| Lock simultâneo | verdadeiro | Bloqueia execuções de índice no ID da partição. Isso evita problemas de simultaneidade ao lidar com várias atualizações na mesma partição ao mesmo tempo. |
| Skip-Log-replay | verdadeiro | Quando os nós Cassandra inicia, ele reproduz o log de confirmação, essas atualizações são ignoradas para melhorar o tempo de inicialização, pois já foram aplicadas ao ES. |
| SKIP-NON-LOCAL-APDATES | verdadeiro | Para melhorar o desempenho, a ativação dessa configuração executará apenas atualizações de índice na réplica principal do intervalo de token. |
| Modo Es-Analítico ES | falso | Desativa as exclusão (ttl ou excluir) dos documentos ES. |
| linhas de tipo tipo | nenhum | Lista do tipo para configurar pipelines. |
| Pipeline- <Tepe> | nenhum | Definição de pipeline para este tipo. |
| Index.TransLog.Durabilidade | assíncrono | Ao criar um índice, usamos o modo de confirmação Async para garantir o melhor desempenho, foi a configuração padrão no ES 1.7. Desde 2.x, é sincronizada, resultando em degradação séria de desempenho. |
| Disponível e rebunda | verdadeiro | Ao criar um novo índice, é possível (ou não) executar pesquisas no índice parcial. |
| truncate-reboild | falso | Índice truncado ES antes da reconstrução. |
| Período de purga | 60 | A cada 60 minutos, todos os índices vazios serão excluídos do alias. |
| por índice-tipo | verdadeiro | Aperte o nome do índice com o nome da tabela. No ES 5.x, não é mais possível ter um mapeamento diferente para o mesmo nome de campo em diferentes tipos do mesmo índice. Nos tipos de 6.x será removido. |
| força de força | falso | A cada minuto, uma solicitação "Excluir por consulta" é enviada para ES para excluir documentos que expiraram _cassandrattl. Isso é para emular a funcionalidade TTL que foi removida no ES 5.x. Observe que, embora o Cassandra Compaction realmente exclua o documento do ES, não há garantia de quando ocorrer. |
| TTL-Shift | 0 | Tempo em segundos para mudar de Cassandra TTL. Se o TTL foi 1H em Cassandra e Shift for 3600, significa que o documento no ES será excluído 1H depois de Cassandra. |
| Manager de índice | com.genesyslab.webme.commons.index.defaultIndexmanager | Nome da classe Gerenciador de índice. É usado para gerenciar a funcionalidade de segmentação e expiração. |
| tamanho do segmento | 86400000 | Tempo de segmento em milissegundos. Cada milissegundos de "tamanho de segmento" Novo índice será criado pelo seguinte |
| Max-Connections por rotina | 2 | Número de conexão HTTP por nó, o padrão é o valor do pool http apache, pode aumentar o desempenho do índice Cassandra, mas aumentar a carga no ES. (Novo no WCC 9.0.000.15) |
Você deve desativar a detecção da data em sua definição de mapeamento.
O seguinte JSON:
{
"maps" : {
"key1" : " value " ,
"key2" : 42 ,
"keymap" : {
"sss1" : null ,
"sss2" : 42 ,
"sss0" : " ffff "
},
"plap" : " plop "
},
"string" : " string " ,
"int" : 42 ,
"plplpl" : [ 1 , 2 , 3 , 4 ]
}Será convertido em:
{
"maps" : [ " key1=value " , " key2=42 " , " keymap={sss1=null, sss2=42, sss0=ffff} " , " plap=plop " ],
"string" : [ " string " ],
"int" : [ " 42 " ],
"plplpl" : [ " 1 " , " 2 " , " 3 " , " 4 " ]
}Valores possíveis:
<type>Consulte a documentação do Elasticsearch para obter detalhes sobre o mapeamento do tipo: http://www.ellasticsearch.org/guide/en/elticsearch/reference/current/mapping.html
Todos os tipos de colunas Cassandra são suportados, os dados serão enviados como uma string, uma matriz ou um mapa, dependendo do tipo Cassandra. Com o mapeamento adequado, o Elasticsearch converterá os dados no tipo relevante. Isso permitirá pesquisas e relatórios muito melhores.
| Tipos de Cassandra | Elasticsearch recomendou o mapeamento | Comentário |
|---|---|---|
| ASCII | texto ou palavra -chave | Veja a próxima seção sobre o tipo de texto |
| bigint | longo | |
| Blob | desabilitado | Não é possível indexar conteúdo binário |
| booleano | booleano | |
| contador | longo | |
| data | data | |
| decimal | dobro | |
| dobro | dobro | |
| flutuador | dobro | |
| INET | palavra -chave | ES IP não é testado |
| int | int | |
| Lista <Tepe> | O mesmo que tipo | ES espera que um tipo possa ser um único valor ou uma matriz |
| Mapa < Typek , Typev > | objeto | Se suas chaves podem ter muitos valores diferentes, cuidado com a explosão de mapeamento |
| SET <TIPE> | O mesmo que tipo | ES espera que um tipo possa ser um único valor ou uma matriz |
| smallint | int | |
| texto | texto ou palavra -chave | Veja a próxima seção sobre o tipo de texto |
| tempo | palavra -chave | |
| Timestamp | "type": "date", "formato": "yyyy-mm-dd't'hh: mm: sssss'z '" | |
| TimeUuid | palavra -chave | |
| tinyint | int | |
| tupla <tipo1 tipo2, ...> | tipo | |
| uuid | palavra -chave | |
| Varchar | texto ou palavra -chave | Veja a próxima seção sobre o tipo de texto |
| Varint | longo | |
| Tipo definido pelo usuário | objeto | Cada campo UDT será mapeado usando seus nomes e valores |
Mapeamento do tipo de texto
Quando uma coluna de texto (ASCII ou VARCHAR) é enviada para ES, ela é enviada como texto bruto a ser indexado. No entanto, se o texto for JSON adequado, é possível enviá -lo como um documento JSON para o ES de indexar. Isso permite indexar/pesquisar o documento em vez de texto bruto.
O uso desse mapeamento JSON permite pesquisar dados usando "ColumnName.Key: Value".
Se suas chaves podem ter muitos valores diferentes, cuidado com a explosão de mapeamento
JSON-Serialized-Fields (consulte Opções para obter detalhes)
O conteúdo do texto é enviado como JSON. No seu mapeamento, você pode definir cada campo de documento separadamente. Observe que uma vez que um campo for mapeado como um tipo, pelo mapeamento estático ou no mapeamento dinâmico, fornecendo um tipo incompatível resultará em falhas de gravação de Cassandra.
JSON-FLAT-ERIALIZED-FIELDS (consulte Opções para obter detalhes e exemplo de conversão)
O conteúdo do texto também é enviado como JSON, no entanto, todos os valores são forçados a matrizes de cordas planas. Isso limitará a capacidade de pesquisar no JSON aninhado, mas é mais seguro se você não puder controlar o tipo JSON dos valores.
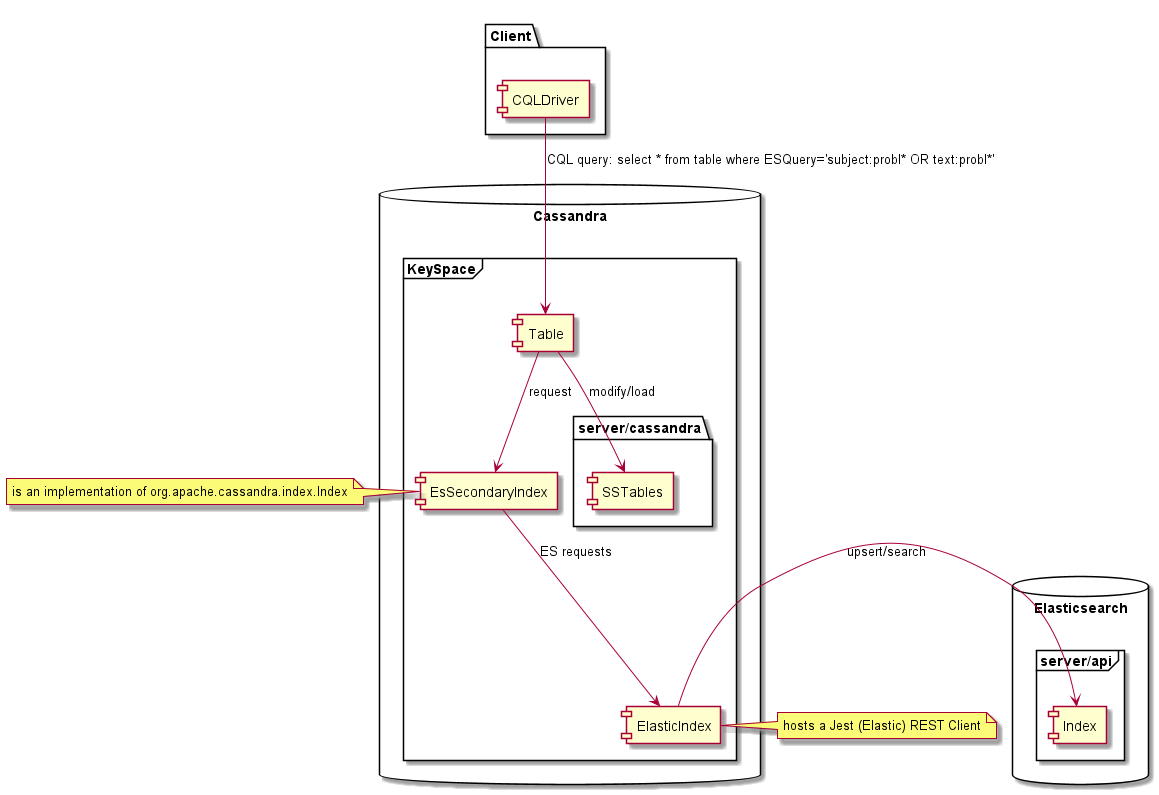
É uma implementação personalizada de um índice Cassandra. Isso introduz algumas limitações vinculadas ao modelo de consistência de Cassandra. A principal limitação se deve à natureza dos índices secundários de Cassandra, cada nó Cassandra contém apenas dados que é responsável dentro do anel Cassandra, com índices secundários que é a mesma coisa, cada nó indexa apenas seus dados locais. Isso significa que, ao fazer uma consulta no índice, a consulta é enviada a todos os nós e, em seguida, os resultados são agregados pelo coordenador de consulta e retornados aos clientes.
Com o ESIndex, é diferente, pois a pesquisa de índices é baseada no Elasticsearch, cada nó é capaz de responder à consulta. Isso significa que a consulta deve ser enviada apenas para um único nó ou resultado conterá duplicatas. Isso é conseguido forçando um token à consulta CQL, como abaixo.
select * from emails where query='subject:12345' and token(id)=0;
O token deve ser um valor longo aleatório para espalhar consultas pelos nós. Ele deve ser construído na chave da partição da linha, 'id' no exemplo acima.
No exemplo acima, a consulta Elasticsearch é 'Assunto: 12345'. Este é um Lucene como uma consulta. Também é possível executar consultas DSL, consulte a página Elasticsearch Query-DSL para obter mais detalhes.
Um único índice de pesquisa de elasticidade conterá todos os índices de tabela Cassandra para um determinado espaço de chave. Para cada índice, é usado um tipo de pesquisa de elasticidade dedicado. Para permitir agregações cruzadas, o tipo não é aplicado nas consultas. Isso significa que, se sua consulta puder corresponder a diferentes tipos, ela retornará mais IDs do que o esperado. Como esses não correspondem às linhas Cassandra, você não obterá mais resultados, mas também poderá obter menos se limitar o número de resultados retornados.
Se a contagem de linhas correspondente for alta e as linhas forem grandes, as pesquisas podem terminar no tempo limitado. Você pode solicitar que apenas o PK seja devolvido com os metadados ES e, em seguida, carregue linhas em paralelo do seu código usando consultas CQL.
Para dizer ao índice para retornar PKs apenas, você precisa usar a dica de consulta abaixo #Options: Load-Rows = false #:
select * from emails where query='#options:load-rows=false#id:ab*';
É importante observar que as linhas devolvidas são falsas e construídas a partir dos resultados da consulta ElasicSearch. Isso significa que as linhas retornadas podem não existir mais:
Quando uma solicitação de pesquisa retorna um resultado, a primeira linha conterá os metadados do Elasticsearch como ## uma string json na coluna do índice. Veja, por exemplo:
cqlsh:ucs> select id,query from emails where query='id:00008RD9PrJMMmpr';
id | query
------------------+---------------------------------------------------------------------------------------------------------------------
00008RD9PrJMMmpr | {"took":5,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":7.89821}}
O mecanismo de segmentação do ESIndex divide o índice de pesquisa de elasticidade monolítica na sequência de índices baseados no tempo. Os propósitos para isso estão seguindo:
Como elasticsearch 5.x TTL não é mais suportado. No entanto, os processos normais de compactação e reparo da Cassandra removem automaticamente os dados da Tombstone, o ElasticIndex removerá os dados do Elasticsearch.
O ESIndex suporta rastreamento de CQL, ele pode ser ativado em um nó ou usando o comando cqlsh com o comando abaixo:
Rastreamento de;
O rastreamento seleciona e você obterá traços de toda a consulta contra todos os nós participantes:
cqlsh:ucs> select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1;
Id | AttributeValues | AttributeValuesDate | Attributes| CreatedDate | ESQuery | ExpirationDate | MergeIds | ModifiedDate| PrimaryAttributes| Segment| TenantId
1001uiP2niJPJGBa | {"LastName":["IdentifyTest-aBEcKPnckHVP"],"EmailAddress":["IdentifyTest-HHzmNornOr"]} |{} | {'EmailAddress_IdentifyTest-HHzmNornOr': {Id: 'EmailAddress_IdentifyTest-HHzmNornOr', Name: 'EmailAddress', StrValue: 'IentifyTest-HHzmNornOr', Description: null, MimeType: null, IsPrimary: False}, 'LastName_IdentifyTest-aBEcKPnckHVP': {Id: 'LastName_IdentifyTest-aBEcKPnckHVP', Name: 'LastName', StrValue: 'IdentifyTest-aBEcKPnckHVP', Description: null, MimeType: null IsPrimary: False}} | 2018-10-30 02:05:06.960000+0000 | {"_index":"ucsperf2_contact_index@","_type":"Contact","_id":"1001uiP2niJPJGBa","_score":1.0,"_source":{"Id":"1001uiP2niJPJGBa"},"took":485,"timed_out":false,"_shards":{"total":5,"successful":5,failed":0},"hits":{"total":18188,"max_score":1.0}} | null | null | 2018-10-30 02:05:06.960000+0000 | {'EmailAddress': 'IdentifyTest-HHzmNornOr', 'LastName': 'IdentifyTest-aBEcKPnckHVP'} | not-applicable |1
(1 rows)
Em seguida, você receberá informações de rastreamento da sua sessão:
Sessão de rastreamento: 8ED07B60-180D-11E9-B832-33A777983333
activity | timestamp | source | source_elapsed | client
-----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:03:32.118000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
RANGE_SLICE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.200000 | xxx.xx.47.49 | 34 | xxx.xx.40.11
Executing read on ucsperf2.Contact using index Contact_ESQuery_idx [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 411 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Searching 'AttributeValues.LastName:ab*' [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 693 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Found 10000 matching ES docs in 514ms [ReadStage-1] | 2019-01-14 16:02:30.716000 | xxx.xx.47.49 | 515336 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator initialized [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 516911 | xxx.xx.40.11
reading data from /xxx.xx.47.100 [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 517121 | xxx.xx.40.11
speculating read retry on /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517435 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517436 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517445 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517558 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517866 | xxx.xx.40.11
Bloom filter allows skipping sstable 83 [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517965 | xxx.xx.40.11
Partition index with 0 entries found for sstable 400 [ReadStage-2] | 2019-01-14 16:02:30.719000 | xxx.xx.47.49 | 518300 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519720 | xxx.xx.40.11
Processing response from /xxx.xx.47.82 [RequestResponseStage-4] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519865 | xxx.xx.40.11
Bloom filter allows skipping sstable 765 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522352 | xxx.xx.40.11
Bloom filter allows skipping sstable 790 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522451 | xxx.xx.40.11
Bloom filter allows skipping sstable 819 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522516 | xxx.xx.40.11
Bloom filter allows skipping sstable 848 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522662 | xxx.xx.40.11
Bloom filter allows skipping sstable 861 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522741 | xxx.xx.40.11
Skipped 0/7 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522855 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523075 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523164 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524717 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator closed [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524805 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524872 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524971 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528222 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528364 | xxx.xx.40.11
Initiating read-repair [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528481 | xxx.xx.40.11
Parsing select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1; [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 174 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 254 | xxx.xx.40.11
Index mean cardinalities are Contact_ESQuery_idx:-2109988917941223823. Scanning with Contact_ESQuery_idx. [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 418 | xxx.xx.40.11
Computing ranges to query [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2480 | xxx.xx.40.11
Submitting range requests on 1 ranges with a concurrency of 1 (-4.6099044E15 rows per range expected) [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2568 | xxx.xx.40.11
Enqueuing request to /xxx.xx.47.49 [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2652 | xxx.xx.40.11
Submitted 1 concurrent range requests [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2708 | xxx.xx.40.11
Sending RANGE_SLICE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2874 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.100 | 29 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521263 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521468 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521566 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1187 [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521775 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 266 | xxx.xx.40.11
Bloom filter allows skipping sstable 1188 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522130 | xxx.xx.40.11
Acquiring sstable references [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 361 | xxx.xx.40.11
Bloom filter allows skipping sstable 1189 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522205 | xxx.xx.40.11
Bloom filter allows skipping sstable 1190 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522259 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522303 | xxx.xx.40.11
Bloom filter allows skipping sstable 1186 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522415 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522540 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522679 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522734 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522863 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1208 [ReadStage-1] | 2019-01-14 16:03:32.644000 | xxx.xx.47.100 | 3756 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528443 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-2] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528516 | xxx.xx.40.11
Bloom filter allows skipping sstable 1209 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9090 | xxx.xx.40.11
Bloom filter allows skipping sstable 1210 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9162 | xxx.xx.40.11
Bloom filter allows skipping sstable 1211 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9187 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9237 | xxx.xx.40.11
Bloom filter allows skipping sstable 1207 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9335 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9571 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9734 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9842 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 10116 | xxx.xx.40.11
Request complete | 2019-01-14 16:03:32.646708 | xxx.xx.47.82 | 528708 | xxx.xx.40.11
Todas as atividades que começam pela ESI são atividades da esindex:
* ESI <id> Searching 'AttributeValues.LastName:ab*': The query have been received and decoded by the ESIndex, it is now sent to ElasticSearch
* ESI <id> Found 10000 matching ES docs in 514ms: The query to ElasticSearch has found 10000 results
* ESI <id> StreamingPartitionIterator initialized: Streaming partition iterator have been provided with all Ids found, and starts reading rows
* ESI <id> StreamingPartitionIterator closed: Client is done reading rows (limit was 1)
Rastrear atualizações/inserções/exclui
cqlsh:ucs> update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa';
Sessão de rastreamento: F76E4AC0-180E-11E9-B832-33A777983333
activity | timestamp | source | source_elapsed | client
----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 22 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 354 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 465 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2356 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2548 | xxx.xx.40.11
Parsing update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa'; [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 146 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 213 | xxx.xx.40.11
Determining replicas for mutation [Native-Transport-Requests-1] | 2019-01-14 16:13:37.133000 | xxx.xx.47.82 | 1895 | xxx.xx.40.11
Appending to commitlog [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2042 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2149 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2186 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2232 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 28 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 390 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 471 | xxx.xx.40.11
ESI decoding row 31303031756950326e694a504a474261 [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 579 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5160 | xxx.xx.40.11
ESI writing 31303031756950326e694a504a474261 to ES index [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 664 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-4] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5280 | xxx.xx.40.11
ESI index 31303031756950326e694a504a474261 done [MutationStage-1] | 2019-01-14 16:13:37.160000 | xxx.xx.47.100 | 23878 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28445 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-2] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28549 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25614 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25793 | xxx.xx.40.11
Request complete | 2019-01-14 16:13:37.814048 | xxx.xx.47.82 | 682048 | xxx.xx.40.11
Todas as atividades que começam pela ESI são atividades da esindex:
* ESI decoding row <rowId>: update request have been received by the ESIndex, row is being converted to JSON
* ESI writing <rowId> to ES index: update is being sent to ElasticSearch
* ESI index <rowId> done: ElasticSearch acknowledged the update
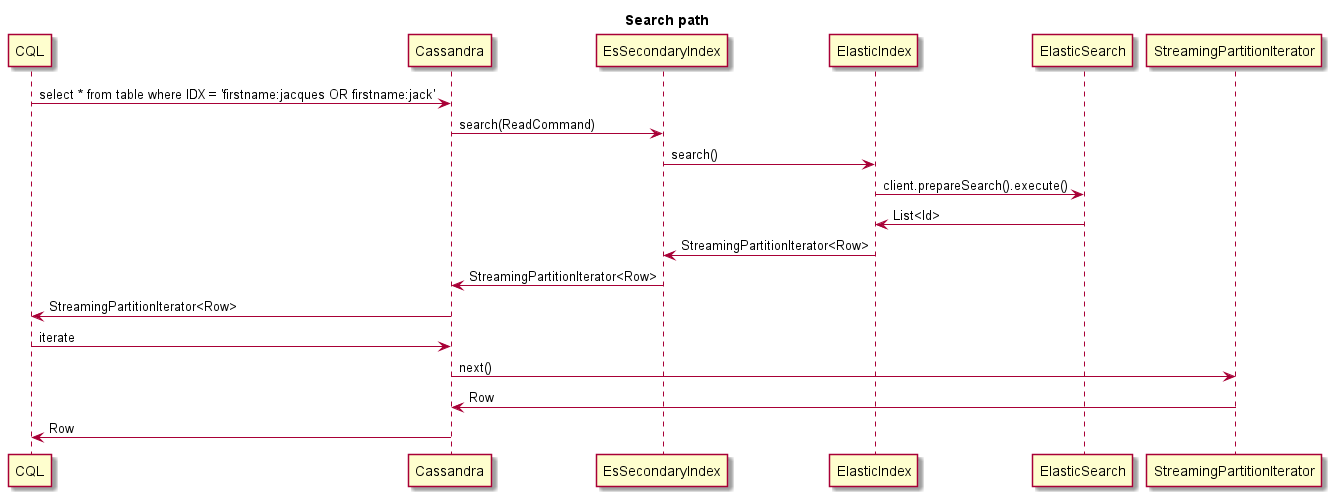
Este é um exemplo do que acontece ao pesquisar:
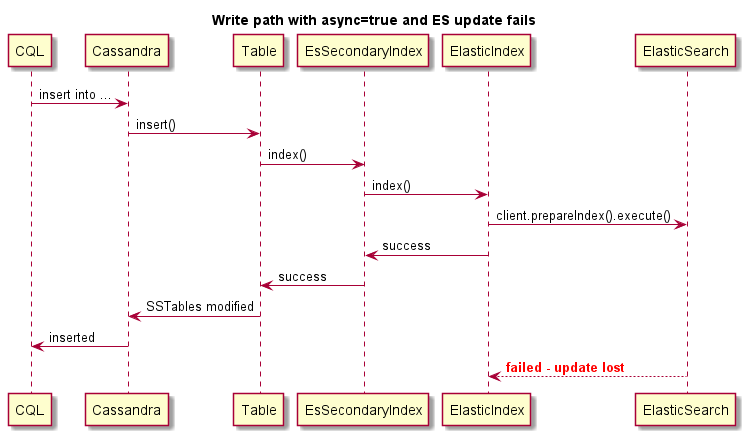
Este é um exemplo de gravação síncrona (a operação de Cassandra falhará se ES falhar):
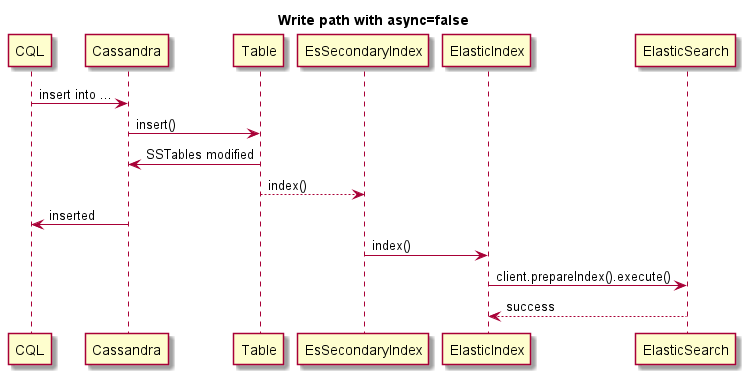
Este é um exemplo de gravação assíncrona:
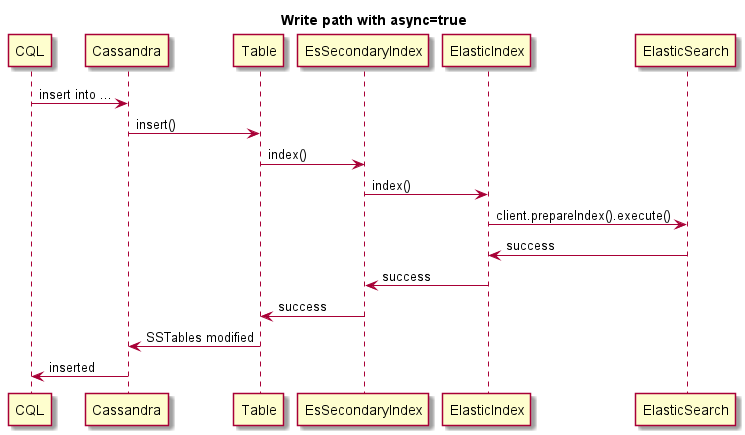
Este é um exemplo de gravação assíncrona, a operação de Cassandra não falhará se o ES falhar: